支持向量机SVM(一):基本概念、目标函数的推导
本文旨在介绍支持向量机(SVM)的基本概念并解释SVM中的一个关键问题:
为什么SVM目标函数中的函数间隔取1?
一、分类问题
给定N个分属两类的样本,给出一个决策边界使得边界一侧只含一种样本(如下图)
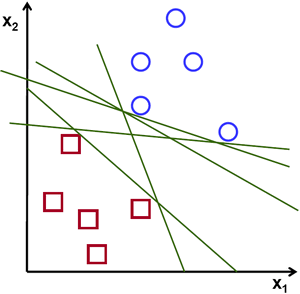
从直观上讲,两种样本集被分开的“间隔”越大表示分类效果越好,如下图中,边界2的效果显然是最好的
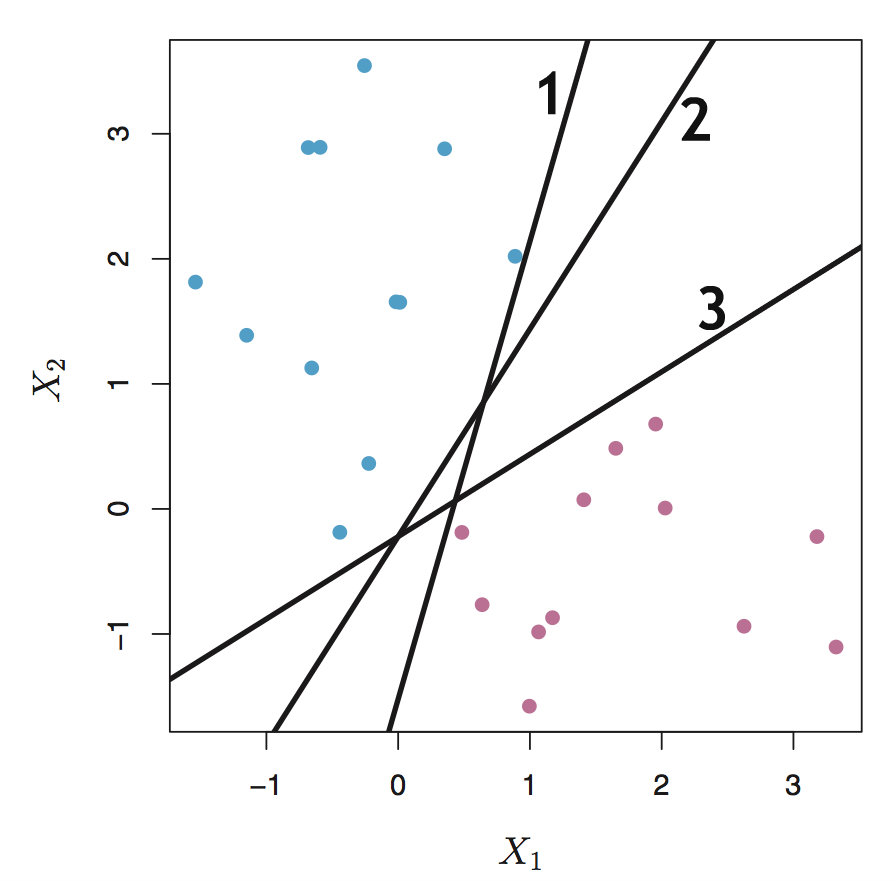
传统的方法来计算间隔时,一般考虑所有样本点,比如可以使用样本集中所有样本点到决策边界的距离和来作为这个样本集到决策边界的距离。由于考虑了所有样本,因此这么做的一个缺点在于对离群值(outlier)十分敏感
我们发现确定决策边界的过程中,最重要的点是两个样本集之间距离靠的最近的那些点,是否可以只利用这些点来给出决策边界呢?SVM就是基于这一点产生的分类技术。
二、SVM相关的数学概念
由于SVM中包含大量数学推导,因此想要完全理解SVM就必须先理解SVM中涉及到的数学概念。
超平面(hyperplane)
上图给出的例子中,样本是二维平面中的点,由(X1, X2)来描述,而决策边界由一条的直线来描述,这条直线将平面分成了两部分。
实际问题中涉及到的样本往往是多维的,比如学生=[学号,姓名,地址,...],因此需要给出一个更一般的定义。
超平面是n维空间中n-1维的子空间,由方程$a_1 x_1 + \cdots + a_n x_n = b$来确定(其中$a_1 , … , a_n$是不全为零的常数)
超平面将n维空间分成了两部分,比如二维空间$R^2$中,$a_1 x_1 + a_2 x_2= b$表示的直线就是二维空间中的一个超平面,它将平面分为了两部分。
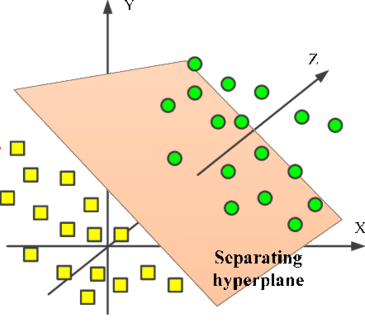
而三维空间$R^3$中,$a_1 x_1 + a_2 x_2 + a_3 x_3= b$表示的平面是三维空间的一个超平面,它将三维空间分为两部分,如下图
在数据分析领域,一般将d维空间中的样本表示为$(\mathbf{x_i,y_i}),其中\mathbf{x_i} = (x_{i1},x_{i2},...,x_{id})$表示一个d维的向量,$\mathbf{y_i} = \{-1,1\}$表示$\mathbf{x_i}$所属的类别
例如,二维空间中((1, 1), 1)表示点(1,1)属于类别1。
$\mathbf{y_i}$是样本所属的标签,理论上可以取任何值,如{apple, orange},但为了方便接下来的数学计算,设为{-1,1}
超平面被称为决策边界,一般写成如下的形式:
$w^Tx+b=0$
其中$w=(w_1, ... , w_d)$,$b$是一个常数,称为偏移量
例如,在二维空间中$2x_1+x_2+1=0$就是一个决策边界,其中$w=(2,1)$,$b=1$
注意:
- 不要把$w$理解为斜率,$b$理解为截距
- 由于$w,b$可以同比缩放,因此同一个超平面有多种表示方式,如$2x_1+x_2+1=0$和$4x_1+2x_2+2=0$表示同一个超平面
超平面的性质
如果$x_a,x_b$是超平面上$w^Tx+b=0$上的点,则
$w^Tx_a+b=0$
$w^Tx_b+b=0$
相减得到
$w^T(x_a-x_b)=0$
因为$x_a,x_b$是超平面上的点,$x_a-x_b$就是一个平行于超平面的向量。由于点积为零,所以$w$垂直于超平面,即$w$表示超平面$w^Tx+b=0$的一个法向量
点到超平面的距离
$\vec {a}$在$\vec {b}$上的投影公式:
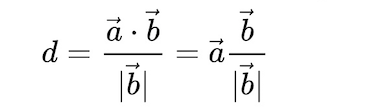
下图中,$A$是超平面上一点,点$P$是超平面外一点
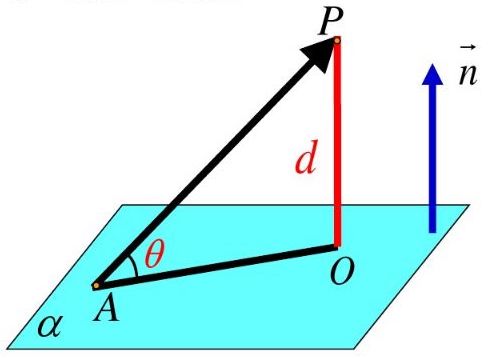
则$P$到超平面$α$的距离为$\vec {AP}$在法向量$\vec {n}$方向上投影的绝对值,即
$d = \displaystyle \frac{|\vec {AP} · \vec {n}|}{|\vec {n}|}$
因此,设$x$是超平面外一点,$x_0$是超平面内一点,法向量为$w$,则$x$到超平面$w^Tx+b=0$的距离为:
$d = \displaystyle \frac{|w^T(x-x_0)|}{||w||} = \frac{|w^Tx+b|}{||w||}$
这里$||·||$表示L2范数,$||w||_2 = \sqrt{|w_1|^2+|w_1|^2+...+|w_d|^2}$
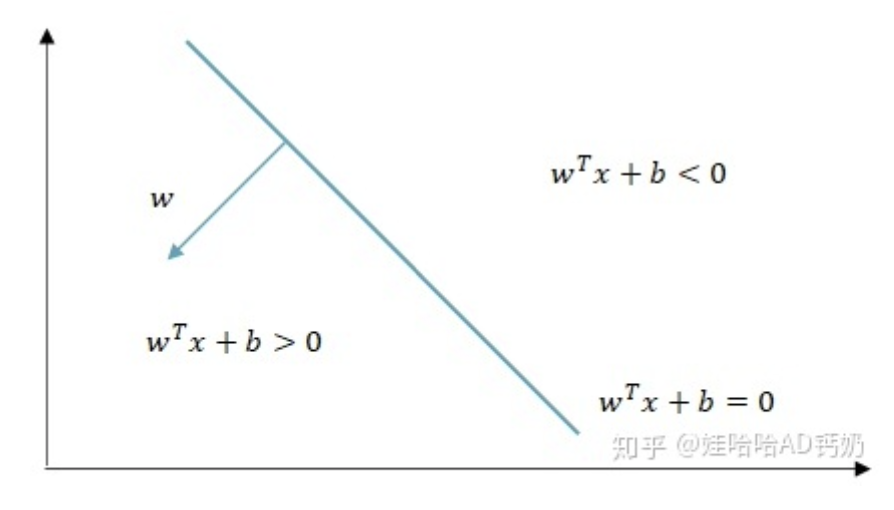
同时,这里可以看出,如果点$x$在超平面$w^Tx+b=0$的“上方”($w$指向的那一侧),则$x-x_0$与$w$的夹角$θ∈[0,\displaystyle \frac{\pi}{2})$(图中$\vec {AP}$和$\vec {n}$的夹角),因此$w^Tx+b = w^T(x-x_0) = |w|·|x-x_0|·cosθ > 0$
同理, 如果点$x$在超平面$w^Tx+b=0$的“下方”,$w^Tx+b < 0$
三、 SVM分类器
SVM分类器的目标是给出一个决策边界(超平面)将样本正确地分为两类,且该决策边界拥有最大的边缘
决策边界
首先,我们需要找出正确分类的超平面,即对于所有样本$(\mathbf{x_i,y_i})$,满足$\mathbf{y_i}=1$的$\mathbf{x_i}$都在超平面的一侧,而满足$\mathbf{y_i}=-1$的$\mathbf{x_i}$都在超平面的另一侧
一般来说,我们希望$\mathbf{y_i}=1$的样本都在超平面上方,$\mathbf{y_i}=-1$的样本都在超平面下方
需要注意的是“上方”和“下方”并不是视觉上的超平面上面或下面,而是以超平面的法向量$w$指向的方向为上方,反之为下方
根据之前的计算,我们知道:
$w^Tx+b > 0$ ⇔ 点$x$在超平面$w^Tx+b=0$的上方
$w^Tx+b < 0$ ⇔ 点$x$在超平面$w^Tx+b=0$的下方
因此,当超平面w^Tx+b正确分类时,对所有样本$(\mathbf{x_i,y_i})$:
$w^Tx_i+b > 0, y_i = 1$
$w^Tx_i+b < 0, y_i = -1$
这时将$y_i$定义为{-1,1}的方便之处就体现出来了,上述约束可以简化为:
$y_i(w^Tx_i+b) >0, ∀i$
函数间隔、几何间隔
点$x_i$到超平面的距离$d = \displaystyle \frac{|w^Tx_i+b|}{||w||}$,我们将其称为$x_i$到超平面的几何间隔γ
当超平面正确分类时,上式也可以写成:$γ = \displaystyle \frac{y_i(w^Tx_i+b)}{||w||}$,同时,我们将$y_i(w^Tx_i+b)$称为$x_i$到超平面的函数间隔γ'
因此,我们得到$γ' = γ · ||w||$
同一个超平面有多种表示方式,如:$w_1^Tx+b_1=0$ 和 $2w_1^Tx+2b_1=0$,因此即使是同一个超平面,$x_i$的函数间隔γ'也和表示超平面的$w,b$有关,
对于一个确定超平面,$x_i$到超平面的几何间隔表示点到超平面的实际距离,这是一个定值,和超平面的表示方式无关
例:样本点$(x_1, y_1)$= ((1, 1), 1),样本点$(x_2, y_2)$= ((-1, -1), -1),决策边界$x_{i1}+x_{i2}-1 = 0$,即$w=(1,1), b=-1$,如下图
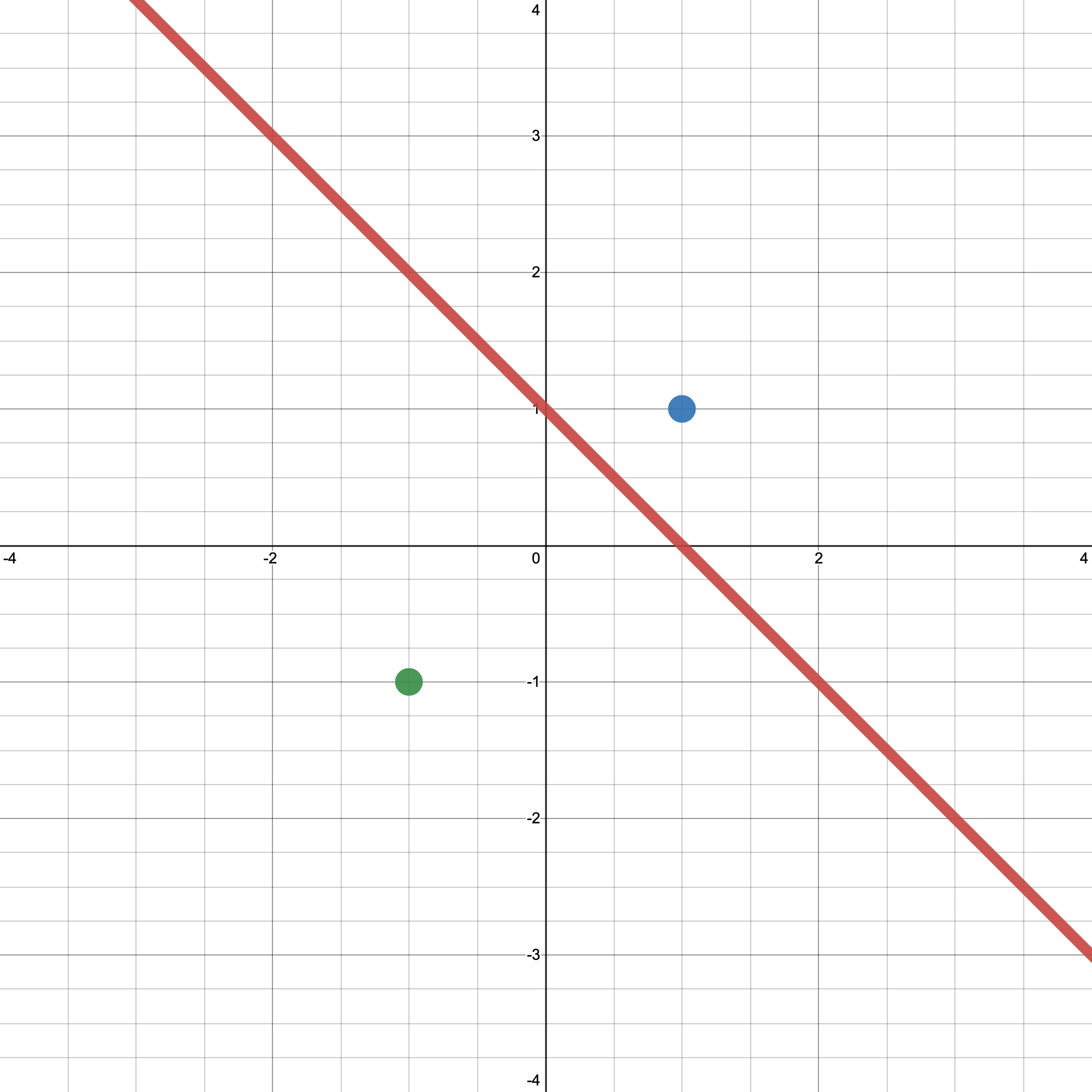
对于$x_1,γ' = y_1(w^T·x_1 + b) = 1 * (1*1 + 1*1 - 1) = 1,γ = \displaystyle \frac{γ'}{\sqrt{1+1}} = \frac{\sqrt{2}}{2}$
对于$x_2,γ' = y_2(w^T·x_2 + b) = -1 * (-1*1 + -1*1 - 1) = 3,γ = \displaystyle \frac{γ'}{\sqrt{1+1}} = \frac{3\sqrt{2}}{2}$
最大边缘
支持向量机SVM(一):基本概念、目标函数的推导的更多相关文章
- [转]支持向量机SVM总结
首先,对于支持向量机(SVM)的简单总结: 1. Maximum Margin Classifier 2. Lagrange Duality 3. Support Vector 4. Kernel 5 ...
- [转] 从零推导支持向量机 (SVM)
原文连接 - https://zhuanlan.zhihu.com/p/31652569 摘要 支持向量机 (SVM) 是一个非常经典且高效的分类模型.但是,支持向量机中涉及许多复杂的数学推导,并需要 ...
- 机器学习之支持向量机—SVM原理代码实现
支持向量机—SVM原理代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9596898.html 1. 解决 ...
- 模式识别之svm()---支持向量机svm 简介1995
转自:http://www.blogjava.net/zhenandaci/archive/2009/02/13/254519.html 作者:Jasper 出自:http://www.blogjav ...
- 机器学习——支持向量机SVM
前言 学习本章节前需要先学习: <机器学习--最优化问题:拉格朗日乘子法.KKT条件以及对偶问题> <机器学习--感知机> 1 摘要: 支持向量机(SVM)是一种二类分类模型, ...
- 以图像分割为例浅谈支持向量机(SVM)
1. 什么是支持向量机? 在机器学习中,分类问题是一种非常常见也非常重要的问题.常见的分类方法有决策树.聚类方法.贝叶斯分类等等.举一个常见的分类的例子.如下图1所示,在平面直角坐标系中,有一些点 ...
- 一步步教你轻松学支持向量机SVM算法之案例篇2
一步步教你轻松学支持向量机SVM算法之案例篇2 (白宁超 2018年10月22日10:09:07) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- OpenCV 学习笔记 07 支持向量机SVM(flag)
1 SVM 基本概念 本章节主要从文字层面来概括性理解 SVM. 支持向量机(support vector machine,简SVM)是二类分类模型. 在机器学习中,它在分类与回归分析中分析数据的监督 ...
- 转:机器学习中的算法(2)-支持向量机(SVM)基础
机器学习中的算法(2)-支持向量机(SVM)基础 转:http://www.cnblogs.com/LeftNotEasy/archive/2011/05/02/basic-of-svm.html 版 ...
- 【机器学习】支持向量机SVM
关于支持向量机SVM,这里也只是简单地作个要点梳理,尤其是要注意的是SVM的SMO优化算法.核函数的选择以及参数调整.在此不作过多阐述,单从应用层面来讲,重点在于如何使用libsvm,但对其原理算法要 ...
随机推荐
- Git使用方法以及出现的bug解决方案
git常用命令 1.本地库初始化: git init 2.设置签名 (1)项目级别(项目里面) git config user.name xxx git config user.email xxx ( ...
- 『忘了再学』Shell基础 — 10、Bash中的特殊符号(二)
提示:本篇文章接上一篇文章,主要说说()小括号和{}大括号的区别与使用. 8.()小括号 ():用于一串命令执行时,()中的命令会在子Shell中运行.(和下面大括号一起说明) 9.{}大括号 {}: ...
- Hadoop安装部署
Hadoop伪分布式搭建 1.准备Linux环境 ①开启网络,ifconfig指令查看ip ②修改主机名为自己名字(hadoop) vim /etc/sysconfig/network NETWORK ...
- Python夺命20问
1.请观看下列代码并回答问题: import collections from random import choice Card = collection.namedtuple('Card', [' ...
- Kotlin 之 let、with、run、apply、also 函数的使用
一.内联拓展函数 let let 扩展函数的实际上是一个作用域函数,当你需要去定义一个变量在一个特定的作用域范围内,let函数的是一个不错的选择:let函数另一个作用就是可以避免写一些判断null的操 ...
- 2021.11.09 P4824 [USACO15FEB]Censoring S与P3121 [USACO15FEB]Censoring G(KMP&&AC自动机)
2021.11.09 P4824 [USACO15FEB]Censoring S与P3121 [USACO15FEB]Censoring G(KMP&&AC自动机) https://w ...
- Ubuntu22.04搭建PWN环境
前言 最近尝试在Ubuntu最新的版本22.04版本上搭建PWN环境,有了之前在kali上搭建的经验,总的来说问题不大.但搭建的时候还是有不少地方出错了,好在搭建的过程中不断的拍摄快照,所以整个过程还 ...
- Maven基础学习笔记
Maven基础学习笔记 下载链接 官网:https://maven.apache.org/ 所有版本:https://archive.apache.org/dist/maven/maven-3/ 阿里 ...
- FreeRTOS --(2)内存管理 heap1
转载自https://blog.csdn.net/zhoutaopower/article/details/106631237 FreeRTOS 提供了5种内存堆管理方案,分别对应heap1/heap ...
- 命令工具 -(1)Vim 文本编辑器学习
关注「开源Linux」,选择"设为星标" 回复「学习」,有我为您特别筛选的学习资料~ 前言 提起 Linux,大家都听说过这句话:Linux 一切皆文件. 配置一个服务就是在修改它 ...