一文搞懂Kafka的基本原理及使用
Kafka的基本原理及使用
一、基本概念及原理
1、Kafka特点
Kafka 是一个分布式的流式平台,流式平台包括以下三个特点:
- 发布和订阅消息(流),类似于一个消息队列或企业消息系统
- 持久化收到的记录流,从而具有容错能力
- 实时处理消息
2、Kafka主要应用场景
- 构建实时的流数据管道,可靠地获取系统和应用程序之间的数据
- 构建实时流的应用程序,对数据流进行转换或反应
3、相关概念
Kafka作为一个集群(Cluster)运行在一个或多个服务器上
Kafka集群存储的消息是以主题(Topic)为类别记录的
每个消息是由一个键,一个值和时间戳构成
基本术语
- Topic:Kafka将消息分门别类,每一类的消息称之为一个主题(Topic)
- Producer和Consumer:发布消息的对象称之为主题生产者(Kafka topic producer),订阅消息并处理发布的消息的对象称之为主题消费者(consumers)。生产者将数据保存到Kafka集群中,消费者从中获取消息进行业务的处理
- Broker:已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker)。 消费者可以订阅一个或多个主题,并从Broker拉数据,从而消费这些已发布的消息
- 分区(Partition):每个Topic都可以分成多个Partition,每个Partition在存储层面是append log文件
- 偏移量(Offset):一个分区对应一个磁盘上的文件,而消息在文件中的位置就称为偏移量(Offset),Offset为一个 long型数字,它可以唯一标记一条消息。由于Kafka并没有提供其他额外的索引机制来存储Offset,文件只能顺序的读写,所以在Kafka中几乎不允许对消息进行“随机读写”
4、核心API
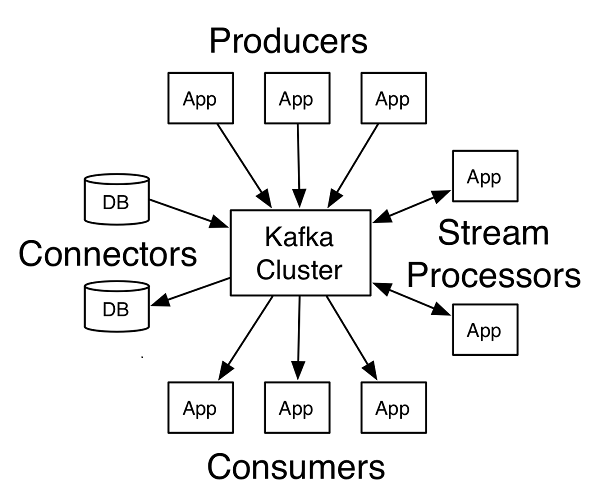
- Producers API:允许应用程序发布记录流至一个或多个Kafka的主题(Topics)
- Consumers API:允许应用程序订阅一个或多个主题,并处理这些主题接收到的记录流
- Streams API:允许应用程序充当流处理器(stream processor),从一个或多个主题获取输入流,并生产一个输出流至一个或多个的主题,能够有效地变换输入流为输出流
- Connector API:允许构建和运行可重用的生产者或消费者,将主题(Topic)连接到现有的应用程序或数据系统。例如,连接到关系数据库的连接器可以获取每个表的变化
5、主题和日志(Topic和Log)
Topic
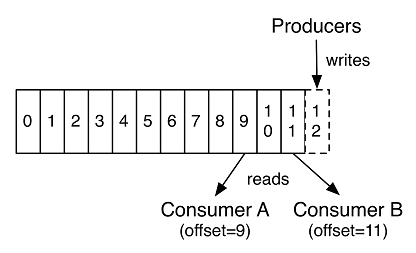
一个Topic可以有由0、1或多个消费者订阅。如下图所示,每个Topic,Kafka集群都会维护一个分区Log,每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(Offset),在每个分区中此偏移量都是唯一的。

Offset
Kafka集群保持所有的消息,直到它们过期(无论消息是否被消费)。消费者所持有的元数据就是偏移量(Offset),即Offset由消费者来控制:当消费者消费消息的时候,偏移量也线性的的增加。消费者可以将偏移量重置为更早的位置,重新读取消息。这种设计使得消费者的操作不会影响其它消费者对此Log的处理。
Kafka中采用分区设计的优点:
- 可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。
- 可以作为并行处理的单元
6、消息系统模式
点对点消息系统
消息持久化到一个队列中,将有一个或多个消费者消费队列中的数据,但是一条消息只能被消费一次。当一个消费者消费了队列中的某条数据之后,该条数据则从消息队列中删除。即使有多个消费者同时消费数据,也能保证数据处理的顺序。
发布-订阅消息系统
消息被持久化到一个topic中。与点对点消息系统不同的是,消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。
7、基本原理
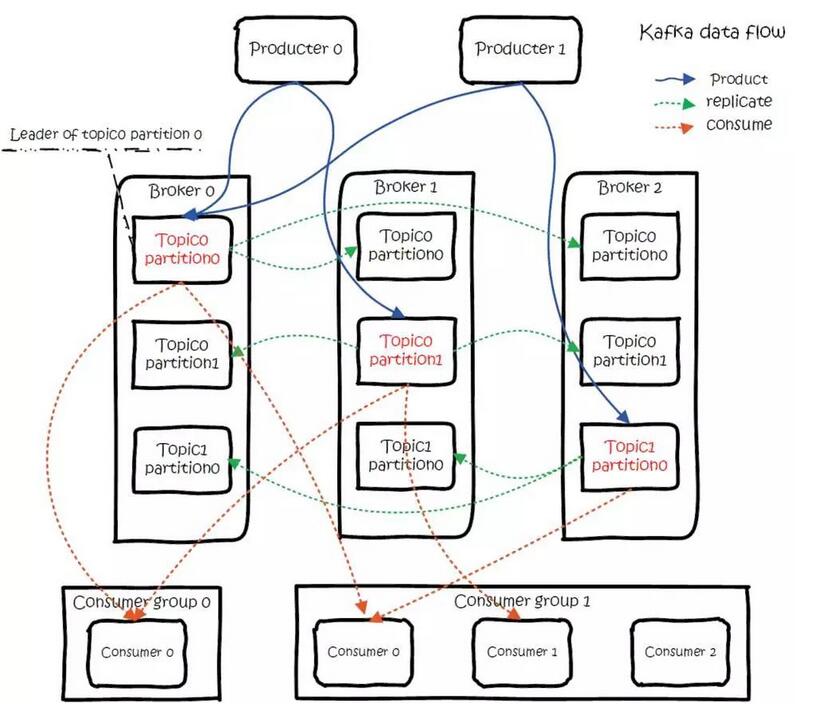
分布式
一个 topic 对应的多个 partition 分散存储到集群中的多个 broker 上,存储方式是一个 partition 对应一个文件,每个 broker 负责存储在自己机器上的 partition 中的消息读写。
副本
每个Partition有一定的副本,备份到多台机器上,以提高可用性。
Kafka副本管理和调度方案:每个Partition选举一个Server 作为Leader,由Leader负责所有对该分区的读写,其他server作为Follower只需要简单的与Leader同步,保持跟进即可。如果原来的Leader失效,会重新选举由其他的Follower来成为新的Leader。( Kafka 使用Zookeeper在 Broker中选出一个Controller,用于Partition分配和Leader选举。Kafka会将Leader分散到不同的Broker上,确保整体的负载均衡 )
数据流程
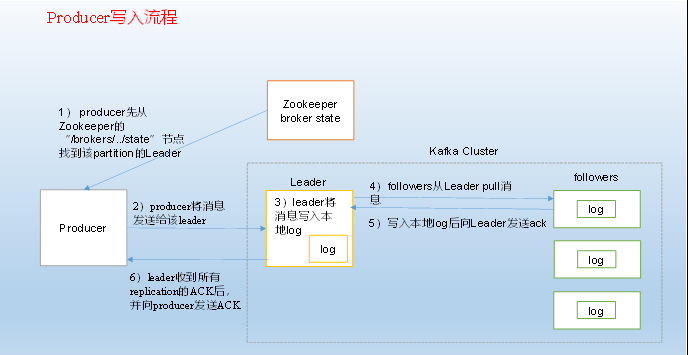
数据生产流程
写入一条数据,需要指定四个参数:Topic、Partition、Key和Value,其中Topic和Value(要写入的数据)是必须要指定的,而Key和Partition是可选的。对于一条记录,先对其进行序列化,然后根据Topic和Partition,放进对应的发送队列中。如果Partition没填,分为两种情况:- Key有值,按照Key进行哈希,相同Key去一个Partition
- Key无值,轮循选出Partition
Producer将会和Topic下所有Partition Leader保持socket连接,消息由Producer直接通过socket发送到Broker。其中Partition Leader的位置注册在Zookeeper中,Producer作为Zookeeper Client,已经注册了watch用来监听Partition Leader的变更事件,因此,可以准确的知道谁是当前的leader。
数据消费流程
消费者不是以单独的形式存在的,每一个消费者属于一个Consumer Group,一个Group包含多个Consumer。订阅Topic是以一个消费组来订阅的,发送到Topic的消息,只会被订阅此Topic的每个Group中的一个Consumer消费。
- 所有的Consumer都具有相同的Group,那么就是一个点对点的消息系统
- 每个Consumer都具有不同的Group,那么就是一个发布-订阅消息系统
一个Partition,只能被消费组里的一个消费者消费,但是可以同时被多个消费组消费,消费组里的每个消费者是关联到一个Partition的,因此,对于一个Topic,同一个Group中不能有多于Partition个数的Consumer同时消费,否则将意味着某些Consumer将无法得到消息。
二、集群架构
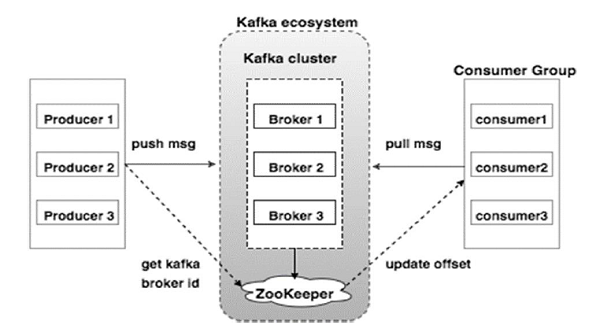
Producer
生产者将数据推送给。 当代理启动时,所有生产者搜索它并自动向该代理发送消息。Kafka生产者不等待来自代理的确认,并且发送消息的速度与代理可以处理的一样快Consumer
Kafka代理是无状态的,消费者必须通过使用分区偏移来维护已经消耗了多少消息。如果消费者确认特定的消息偏移,意味着消费者已经消费了所有先前的消息。消费者可以简单地通过提供偏移值来快退或跳到分区中的任何点。消费者偏移值由ZooKeeper通知
Broker
Kafka集群通常由多个代理组成以保持负载平衡,并使用ZooKeeper来维护它们的集群状态。一个Kafka代理实例可以每秒处理数十万次读取和写入,每个Broker可以处理TB的消息,而没有性能影响
ZooKeeper
ZooKeeper用于管理和协调Kafka代理。ZooKeeper服务主要用于通知生产者和消费者Kafka系统中存在任何新代理或Kafka系统中代理失败。根据Zookeeper接收到关于代理的存在或失败的通知,然后生产者和消费者采取决定并开始与某些其他代理协调他们的任务
三、工作流程
一个消费者订阅数据
生产者将数据发送到指定topic中
数据以partition的方式存储到broker上。Kafka支持数据均衡,例如生产者生成了两条消息,topic有两个partition,那么Kafka将在两个partition上分别存储一条消息
消费者订阅指定topic的数据
当消费者订阅topic中消息时,Kafka将当前的offset发给消费者,同时将offset存储到Zookeeper中
消费者以特定的间隔向Kafka请求数据
当Kafka接收到生产者发送的数据时,Kafka将这些数据推送给消费者
消费者受到Kafka推送的数据,并进行处理
当消费者处理完该条消息后,消费者向broker发送一个该消息已被消费的反馈
当Kafka接到消费者的反馈后,Kafka更新offset包括Zookeeper中的offset。
以上过程一直重复,直到消费者停止请求数据
消费者可以重置offset,从而可以灵活消费存储在Kafka上的数据
消费者组数据消费流程
- 生产者发送数据到指定的topic
- Kafka将数据存储到broker上的partition中
- 假设现在有一个消费者订阅了一个topic,topic名字为“test”,消费者的Group ID为“Group1”
- 此时Kafka的处理方式与只有一个消费者的情况一样
- 当Kafka接收到一个同样Group ID为“Group1”、消费的topic同样为“test"的消费者的请求时,Kafka把数据操作模式切换为分享模式,此时数据将在两个消费者上共享。
- 当消费者的数目超过topic的partition数目时,后来的消费者将消费不到Kafka中的数据。一个partition只能分配给一个消费者,一个消费者可以消费多个partition。
四、使用示例
- Producer:
在创建应用程序之前,首先启动ZooKeeper和Kafka代理,然后使用create topic命令在Kafka代理中创建自己的主题。 之后,创建一个名为 SimpleProducer.java 的java类,然后键入以下代码:
//import util.properties packages
import java.util.Properties;
//import simple producer packages
import org.apache.kafka.clients.producer.Producer;
//import KafkaProducer packages
import org.apache.kafka.clients.producer.KafkaProducer;
//import ProducerRecord packages
import org.apache.kafka.clients.producer.ProducerRecord;
//Create java class named “SimpleProducer"
public class SimpleProducer {
public static void main(String[] args) throws Exception{
// Check arguments length value
if(args.length == 0){
System.out.println("Enter topic name");
return;
}
//Assign topicName to string variable
String topicName = args[0].toString();
// create instance for properties to access producer configs
Properties props = new Properties();
//Assign localhost id
props.put("bootstrap.servers", “localhost:9092");
//Set acknowledgements for producer requests.
props.put("acks", “all");
//If the request fails, the producer can automatically retry,
props.put("retries", 0);
//Specify buffer size in config
props.put("batch.size", 16384);
//Reduce the no of requests less than 0
props.put("linger.ms", 1);
//The buffer.memory controls the total amount of memory available to the producer for buffering.
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
Producer<String, String> producer = new KafkaProducer
<String, String>(props);
// 供send方法以异步方式将消息发送到主题,producer.send(new ProducerRecord<byte[],byte[]>(topic, partition, key1, value1) , callback);
// ProducerRecord - 生产者管理等待发送的记录的缓冲区。public ProducerRecord (string topic, int partition, k key, v value)
for(int i = 0; i < 10; i++){
producer.send(new ProducerRecord<String, String>(topicName, Integer.toString(i), Integer.toString(i)));
}
System.out.println("Message sent successfully");
producer.close();
}
}
S.No 配置设置和说明 1 client.id 标识生产者应用程序 2 producer.type 同步或异步 3 acks acks配置控制生产者请求下的标准是完全的 4 retrie 如果生产者请求失败,则使用特定值自动重试 5 linger.ms 达到linger.ms设置的时间,即使数据没达到batch.size,也将这个批次发送出去 6 key.serializer 序列化器接口的键 7 value.serializer 序列化器接口的值 8 batch.size 当多个消息发送到相同分区时,生产者会将消息打包到一起,以减少请求交互,默认是16KB 9 buffer.memory 控制生产者可用于缓冲的存储器的总量 Consumer:
首先,启动ZooKeeper和Kafka代理。 然后使用名为"SimpleConsumer.java"的Java类创建一个"SimpleConsumer"应用程序,并键入以下代码:
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class SimpleConsumer {
public static void main(String[] args) throws Exception {
if(args.length == 0){
System.out.println("Enter topic name");
return;
}
//Kafka consumer configuration settings
String topicName = args[0].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer
<String, String>(props);
//Kafka Consumer subscribes list of topics here.
consumer.subscribe(Arrays.asList(topicName))
//print the topic name
System.out.println("Subscribed to topic " + topicName);
int i = 0;
//
while (true) {
// poll():最长等待时间(ms)使用预订/分配API之一获取指定的主题或分区的数据。 如果在轮询数据之前未预订主题,这将返回错误。
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
// print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value());
}
}
}
S.No 方法和说明 1 public java.util.Set< TopicPar- tition> assignment()获取由用户当前分配的分区集。 2 public string subscription()订阅给定的主题列表以获取动态签名的分区。 3 public void sub-scribe(java.util.List< java.lang.String> topics,ConsumerRe-balanceListener listener)订阅给定的主题列表以获取动态签名的分区。 4 public void unsubscribe()从给定的分区列表中取消订阅主题。 5 public void sub-scribe(java.util.List< java.lang.String> topics)订阅给定的主题列表以获取动态签名的分区。 如果给定的主题列表为空,则将其视为与unsubscribe()相同。 6 public void sub-scribe(java.util.regex.Pattern pattern,ConsumerRebalanceLis-tener listener)参数模式以正则表达式的格式引用预订模式,而侦听器参数从预订模式获取通知。 7 public void as-sign(java.util.List< TopicPartion> partitions)向客户手动分配分区列表。 8 poll()使用预订/分配API之一获取指定的主题或分区的数据。 如果在轮询数据之前未预订主题,这将返回错误。 9 public void commitSync()提交对主题和分区的所有子编制列表的最后一次poll()返回的提交偏移量。 相同的操作应用于commitAsyn()。 10 public void seek(TopicPartition partition,long offset)获取消费者将在下一个poll()方法中使用的当前偏移值。 11 public void resume()恢复暂停的分区。 12 public void wakeup()唤醒消费者。
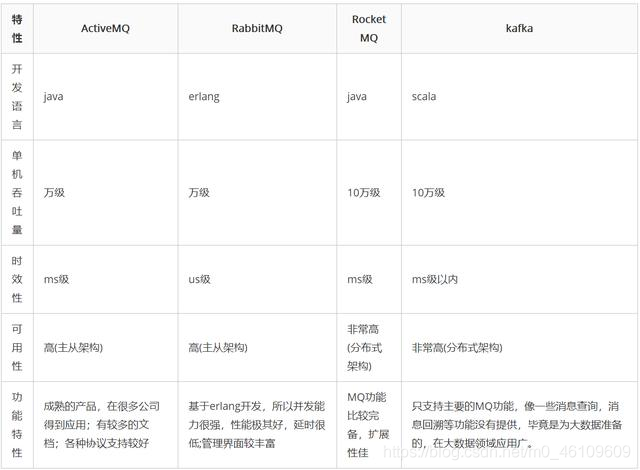
五、与其他消息队列对比
六、相关问题
1、为什么要使用 kafka,为什么要使用消息队列
缓冲和削峰:上游数据时有突发流量,下游可能扛不住,或者下游没有足够多的机器来保证冗余,kafka在中间可以起到一个缓冲的作用,把消息暂存在kafka中,下游服务就可以按照自己的节奏进行慢慢处理。
解耦和扩展性:项目开始的时候,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。
冗余:可以采用一对多的方式,一个生产者发布消息,可以被多个订阅topic的服务消费到,供多个毫无关联的业务使用。
健壮性:消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。
异步通信:很多时候,用户不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。
2、kafka中的 zookeeper 起到什么作用,可以不用zookeeper吗
a、zookeeper 作用
- Broker注册: Broker是分布式部署并且相互之间相互独立,但是需要有一个注册系统能够将整个集群中的Broker管理起来,此时就使用到了Zookeeper
- Topic注册:在Kafka中,同一个Topic的消息会被分成多个分区并将其分布在多个Broker上,这些分区信息及与Broker的对应关系也都是由Zookeeper在维护,由专门的节点来记录
- 生产者负载均衡:由于同一个Topic消息会被分区并将其分布在多个Broker上,因此,生产者需要将消息合理地发送到这些分布式的Broker上,那么如何实现生产者的负载均衡,Kafka支持传统的四层负载均衡,也支持Zookeeper方式实现负载均衡
- 消费者负载均衡:每个消息分区只能被同组的一个消费者进行消费,因此,需要在 Zookeeper 上记录 消息分区 与 Consumer 之间的关系,每个消费者一旦确定了对一个消息分区的消费权力,需要将其Consumer ID 写入到 Zookeeper 对应消息分区的临时节点上
- 消费进度Offset 记录:在消费者对指定消息分区进行消息消费的过程中,需要定时地将分区消息的消费进度Offset记录到Zookeeper上,以便在该消费者进行重启或者其他消费者重新接管该消息分区的消息消费后,能够从之前的进度开始继续进行消息消费
- 消费者注册:每个消费者服务器启动时,都会到Zookeeper的指定节点下创建一个属于自己的消费者节点
b、是否可以不用zookeeper
新的consumer使用了kafka内部的group coordination协议,也减少了对zookeeper的依赖,但是broker依然依赖于zookeeper,zookeeper在kafka中还用来选举controller和检测broker是否存活等等。
3、Kafka中的消息是否会丢失和重复消费
a、消息是否会丢失
Kafka消息发送有两种方式:同步(sync)和异步(async),默认是异步方式,可通过producer.type属性进行配置。Kafka通过配置request.required.acks属性来确认消息的生产:
- 0---表示不进行消息接收是否成功的确认;
- 1---表示当Leader接收成功时确认;
- -1---表示Leader和Follower都接收成功时确认;
综上所述,有6种消息生产的情况,下面分情况来分析消息丢失的场景:
(1)acks=0,不和Kafka集群进行消息接收确认,则当网络异常、缓冲区满了等情况时,消息可能丢失;
(2)acks=1、同步模式下,只有Leader确认接收成功后但挂掉了,副本没有同步,数据可能丢失;
b、消息是否会重复消费
Kafka消息消费有两个consumer接口,Low-level API和High-level API:
Low-level API:消费者自己维护offset等值,可以实现对Kafka的完全控制;
High-level API:封装了对parition和offset的管理,使用简单;
如果使用高级接口High-level API,可能存在一个问题就是当消息消费者从集群中把消息取出来,并提交了新的消息offset值后,还没来得及消费就挂掉了,那么下次再消费时之前没消费成功的消息就消失了;
解决办法:
针对消息丢失:同步模式下,确认机制设置为-1,即让消息写入Leader和Follower之后再确认消息发送成功;异步模式下,为防止缓冲区满,可以在配置文件设置不限制阻塞超时时间,当缓冲区满时让生产者一直处于阻塞状态;
针对消息重复:将消息的唯一标识保存到外部介质中,每次消费时判断是否处理过即可。
一文搞懂Kafka的基本原理及使用的更多相关文章
- 一文搞懂RAM、ROM、SDRAM、DRAM、DDR、flash等存储介质
一文搞懂RAM.ROM.SDRAM.DRAM.DDR.flash等存储介质 存储介质基本分类:ROM和RAM RAM:随机访问存储器(Random Access Memory),易失性.是与CPU直接 ...
- 基础篇|一文搞懂RNN(循环神经网络)
基础篇|一文搞懂RNN(循环神经网络) https://mp.weixin.qq.com/s/va1gmavl2ZESgnM7biORQg 神经网络基础 神经网络可以当做是能够拟合任意函数的黑盒子,只 ...
- 转载来自朱小厮博客的 一文看懂Kafka消息格式的演变
转载来自朱小厮博客的 一文看懂Kafka消息格式的演变 ✎摘要 对于一个成熟的消息中间件而言,消息格式不仅关系到功能维度的扩展,还牵涉到性能维度的优化.随着Kafka的迅猛发展,其消息格式也在 ...
- 一文搞懂 Prometheus 的直方图
原文链接:一文搞懂 Prometheus 的直方图 Prometheus 中提供了四种指标类型(参考:Prometheus 的指标类型),其中直方图(Histogram)和摘要(Summary)是最复 ...
- Web端即时通讯基础知识补课:一文搞懂跨域的所有问题!
本文原作者: Wizey,作者博客:http://wenshixin.gitee.io,即时通讯网收录时有改动,感谢原作者的无私分享. 1.引言 典型的Web端即时通讯技术应用场景,主要有以下两种形式 ...
- 一文搞懂vim复制粘贴
转载自本人独立博客https://liushiming.cn/2020/01/18/copy-and-paste-in-vim/ 概述 复制粘贴是文本编辑最常用的功能,但是在vim中复制粘贴还是有点麻 ...
- 三文搞懂学会Docker容器技术(中)
接着上面一篇:三文搞懂学会Docker容器技术(上) 6,Docker容器 6.1 创建并启动容器 docker run [OPTIONS] IMAGE [COMMAND] [ARG...] --na ...
- 三文搞懂学会Docker容器技术(下)
接着上面一篇:三文搞懂学会Docker容器技术(上) 三文搞懂学会Docker容器技术(中) 7,Docker容器目录挂载 7.1 简介 容器目录挂载: 我们可以在创建容器的时候,将宿主机的目录与容器 ...
- 一文搞懂所有Java集合面试题
Java集合 刚刚经历过秋招,看了大量的面经,顺便将常见的Java集合常考知识点总结了一下,并根据被问到的频率大致做了一个标注.一颗星表示知识点需要了解,被问到的频率不高,面试时起码能说个差不多.两颗 ...
随机推荐
- echarts饼图禁止鼠标悬浮区块突出
禁止悬浮突出,在series内添加hoverAnimation:false即可 代码如下: option = { color:['#3498db','#EEEEEE'], series: [ { na ...
- centos和redhat的区别
CentOS(Community Enterprise Operating System,中文意思是:社区企业操作系统)是Linux发行版之一,它是来自于Red Hat Enterprise Linu ...
- Py点亮
- SpringCloud微服务实战——搭建企业级开发框架(三十九):使用Redis分布式锁(Redisson)+自定义注解+AOP实现微服务重复请求控制
通常我们可以在前端通过防抖和节流来解决短时间内请求重复提交的问题,如果因网络问题.Nginx重试机制.微服务Feign重试机制或者用户故意绕过前端防抖和节流设置,直接频繁发起请求,都会导致系统防重 ...
- Sql语言学习——DDl
DDL:操作数据库.表 1. 操作数据库:CRUD 1. C(Create):创建 * 创建数据库: * create database 数据库名称; * 创建数据库,判断不存在,再创建: * cre ...
- C/C++指针、函数、结构体、共用体
指针 变量与地址 变量给谁用的? 变量是对某一块空间的抽象命名. 变量名就是你抽象出来的某块空间的别名. 指针就是地址.指向某个地址. 指针与指针变量 指针是指向某块地址.指针(地址)是常量. 指针变 ...
- VDO虚拟数据优化
VDOVirtual Data Optimize 虚拟数据优化 是一种通过压缩或删除存储设备上的数据来优化存储空间的技术. VDO 是红帽公司收购了 Permabit 公司后获取的新技术,并与2019 ...
- Go单体服务开发最佳实践
单体最佳实践的由来 对于很多初创公司来说,业务的早期我们更应该关注于业务价值的交付,并且此时用户体量也很小,QPS 也非常低,我们应该使用更简单的技术架构来加速业务价值的交付,此时单体的优势就体现出来 ...
- 基于DSP_CPLD_aP8942A_LM1791的语音控制
语音驱动程序 drv_voice.c 语音服务程序 srv_voice.c 1.先运行初始化函数,主要是设置初始音量,并建立一个软件定时器来,以10ms的周期来调用语音播放函数. 1 void s ...
- Windows平台安装SQLite3数据库
Windows平台安装SQLite3数据库 话不多说,开始! 访问SQLite官网下载资源 在搜索引擎中键入SQLite3关键字寻找官网入口或直接点击此处前往SQLite官网,官网界面如下: 点击页面 ...