Elasticsearch中text与keyword的区别
text类型
1:支持分词,全文检索,支持模糊、精确查询,不支持聚合,排序操作;
2:test类型的最大支持的字符长度无限制,适合大字段存储;
使用场景:
存储全文搜索数据, 例如: 邮箱内容、地址、代码块、博客文章内容等。
默认结合standard analyzer(标准解析器)对文本进行分词、倒排索引。
默认结合标准分析器进行词命中、词频相关度打分。
keyword
1:不进行分词,直接索引,支持模糊、支持精确匹配,支持聚合、排序操作。
2:keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
使用场景:
存储邮箱号码、url、name、title,手机号码、主机名、状态码、邮政编码、标签、年龄、性别等数据。
用于筛选数据(例如: select * from x where status='open')、排序、聚合(统计)。
直接将完整的文本保存到倒排索引中。
Dynamic
dynamic属性:默认值为true,允许动态地向文档类型中加入新的字段。推荐设置为false,禁止向文档中添加字段,这样,文档类型的所有字段必须在索引映射的properties属性中显式定义,在properties字段中未定义的字段都将会ElasticSearch忽略。
dynamic设置为ture:默认值,新增加的字段被添加到索引映射中;
dynamic设置为false:新增加的字段会被忽略;
dynamic设置为strict:当向文档中新增字段时,ElasticSearch引擎抛出异常;
# index
index定义字段的分析类型以及检索方式,控制字段值是否被索引.他可以设置成 true 或者 false。没有被索引的字段将无法搜索
如果是no,则无法通过检索查询到该字段;
如果设置为not_analyzed则会将整个字段存储为关键词,常用于汉字短语、邮箱等复杂的字符串;
如果设置为analyzed则将会通过默认的standard分析器进行分析
# 集群分片
Elasticsearch 有一个硬编码限制,单个分片内的文档总数不得超过 2147483519 个。
一般来说这个限制在日志场景下是不太会触发的,但是如果做 TSDB 用,则需要多加注意!
ES更新到5版本后,取消了 string 数据类型,代替它的是 keyword 和 text 数据类型.那么 text 和keyword有什么区别呢?
# 添加数据
使用bulk往es数据库中批量添加一些document
POST /book/novel/_bulk
{"index": {"_id": 1}}
{"name": "Gone with the Wind", "author": "Margaret Mitchell", "date": "2018-01-01"}
{"index": {"_id": 2}}
{"name": "Robinson Crusoe", "author": "Daniel Defoe", "date": "2018-01-02"}
{"index": {"_id": 3}}
{"name": "Pride and Prejudice", "author": "Jane Austen", "date": "2018-01-01"}
{"index": {"_id": 4}}
{"name": "Jane Eyre", "author": "Charlotte Bronte", "date": "2018-01-02"}
# 查看mapping
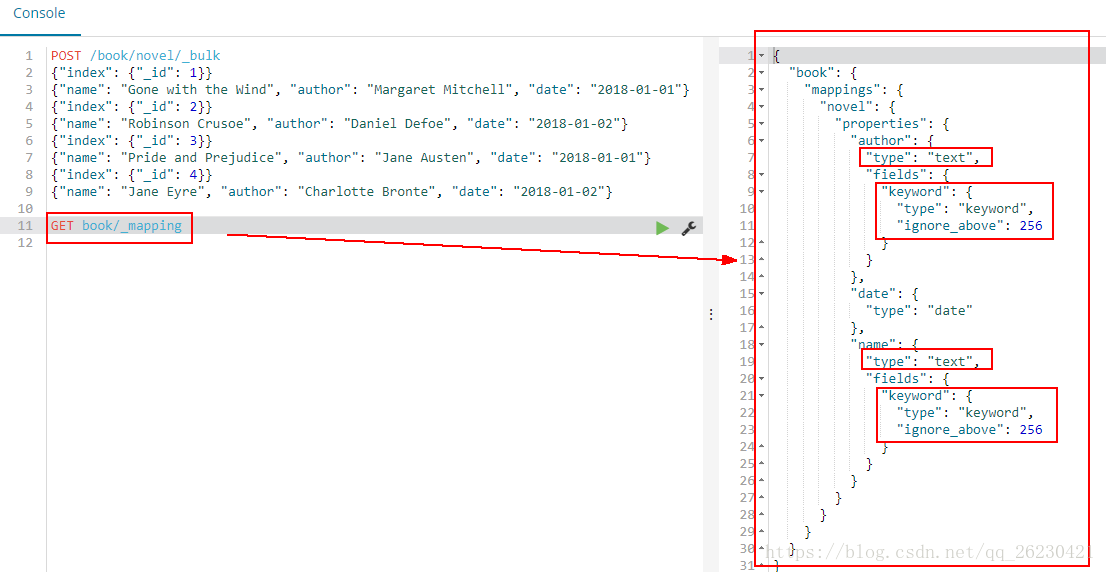
发现name、author的type是text,
还有个field是keyword,keyword的type是keyword:
# 查询
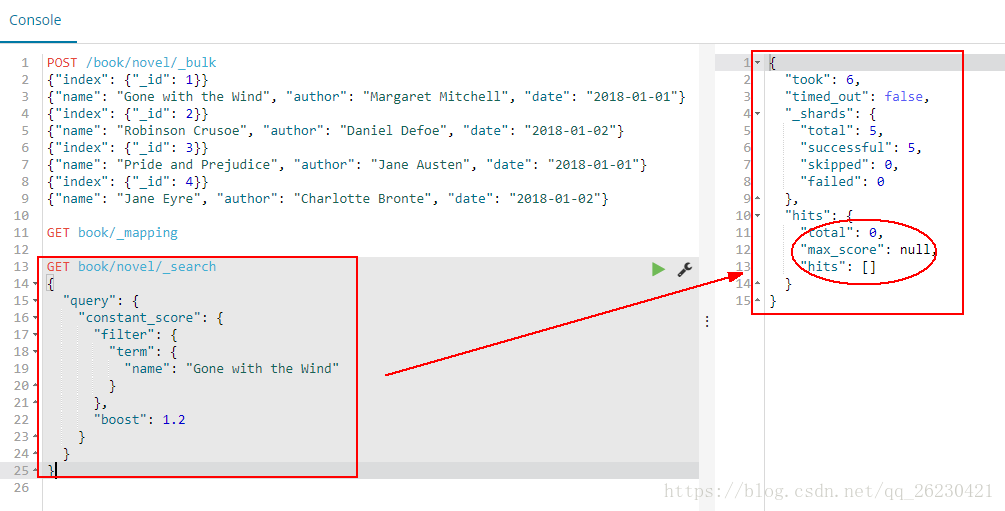
使用term查询某个小说:
GET book/novel/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name": "Gone with the Wind"
}
},
"boost": 1.2
}
}
}
结果是什么也没有查到:
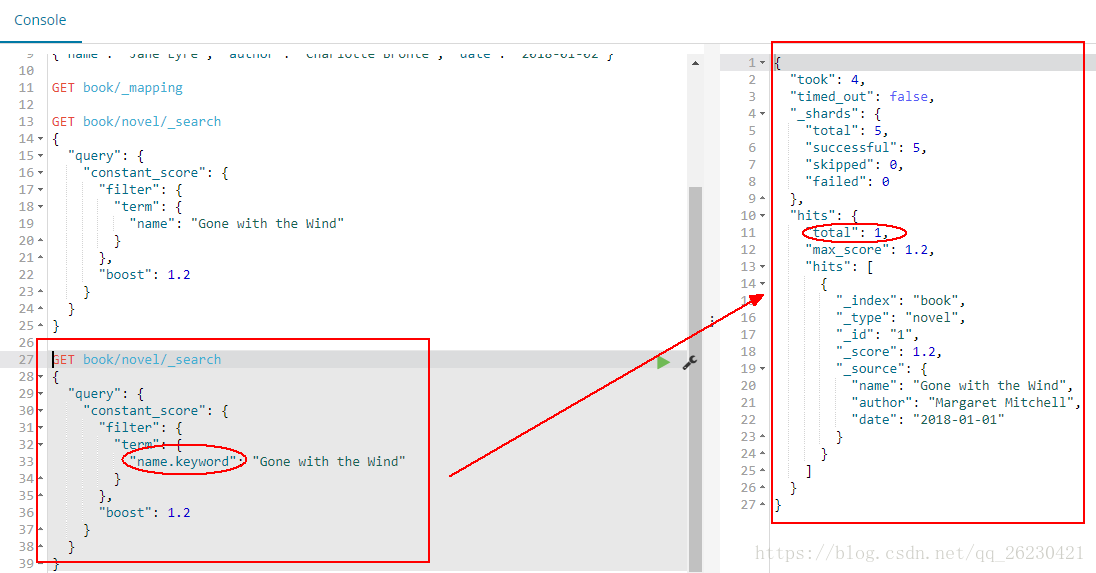
然后使用name的keyword查询:
GET book/novel/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name.keyword": "Gone with the Wind"
}
},
"boost": 1.2
}
}
}
可以查询到一条数据:
# 实验
使用name不能查到,而使用name.keyword可以查到,我们可以通过下面的实验来判断:
使用name进行分词的时候,结果会有4个词出来:
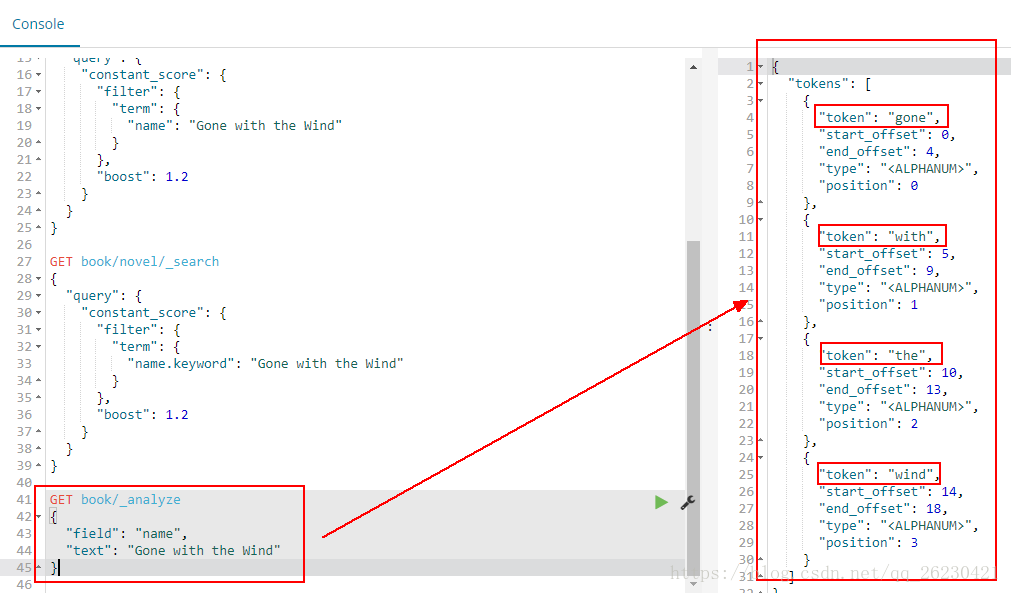
使用name.keyword进行分词的时候,结果只有一个词出来:
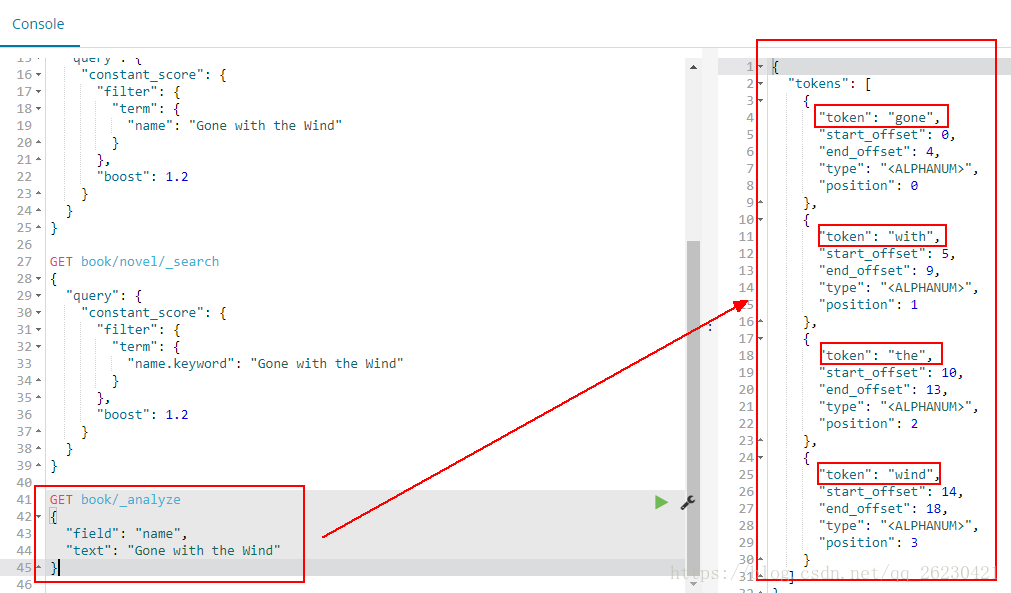
# 结论
text类型:会分词,先把对象进行分词处理,然后再再存入到es中。
当使用多个单词进行查询的时候,当然查不到已经分词过的内容!
keyword:不分词,没有把es中的对象进行分词处理,而是存入了整个对象!
这时候当然可以进行完整地查询!默认是256个字符!
作者:香山上的麻雀
链接:https://www.jianshu.com/p/1189ff372c38
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。Elasticsearch中text与keyword的区别的更多相关文章
- Elasticsearch 中数据类型 text 与 keyword 的区别
随着ElasticSearch 5.X 系列的到来, 同时也迎来了该版本的重大特性之一: 移除了string类型. 这个变动的根本原因是string类型会给我们带来很多困惑: 因为ElasticSea ...
- SQL Server中Text和varchar(max) 区别
SQL Server 2005之后版本:请使用 varchar(max).nvarchar(max) 和 varbinary(max) 数据类型,而不要使用 text.ntext 和 image 数据 ...
- JQuery中text(),html(),val()的区别
这3个都是jquery类库中的语法,分别是: text():获取或者改变指定元素的文本: html():获取或改变指定元素的html元素以及文本: val():获取或者改变指定元素的value值(一般 ...
- elasticsearch中query和filter的区别
参考博客来自: https://mp.weixin.qq.com/s/tiiveCW3W-oDIgxvlwsmXA?utm_medium=hao.caibaojian.com&utm_sour ...
- requests中text和content的区别
# -*- coding: utf-8 -*- __author__ = "nixinxin" import re img_url = "https://f11.baid ...
- jquery中text、html的区别
- ES 15 - Elasticsearch中的数据类型 (text、keyword、date、geo等)
目录 1 核心数据类型 1.1 字符串类型 - string(不再支持) 1.1.1 文本类型 - text 1.1.2 关键字类型 - keyword 1.2 数字类型 - 8种 1.3 日期类型 ...
- 【转】elasticsearch中字段类型默认显示{ "foo": { "type": "text", "fields": { "keyword": {"type": "keyword", "ignore_above": 256} }
官方原文链接:https://www.elastic.co/cn/blog/strings-are-dead-long-live-strings 转载原文连接:https://segmentfault ...
- ES索引Index相关操作&ES数据类型、字符串类型text和keyword区别
1.查看索引以及删除之前的测试索引 1. 查看索引以及索引数量信息 liqiang@root MINGW64 ~/Desktop $ curl -X GET http://127.0.0.1:9200 ...
随机推荐
- Fleet 使用感受
1. 前言 笔者主要使用的编程语言是 Java.平时使用的 IDE 是 JetBrains 公司的 IntelliJ IDEA.有时候也会打开该公司旗下的 PyCharm.DataGrip.WebSt ...
- Python List 中的append 和 extend 的区别
方法的参数不同 append 方法是向原list的末尾添加一个对象(任意对象:如元组,字典,列表等),且只占据一个原list的索引位,添加后无返回值,直接在原列表中添加. list.append(ob ...
- 07 MySQL_SQL数据类型
数据类型 整数类型: int(m) 对应java中的int bigint(m) 对应java中的long m代表显示长度,需要结合 zerofill使用 create table t_int(id i ...
- [mybatis]mybatis日志的使用和分页功能的实现
日志 Mybatis 通过使用内置的日志工厂提供日志功能.内置日志工厂将会把日志工作委托给下面的实现之一: SLF4J Apache Commons Logging Log4j 2 Log4j JDK ...
- Elasticsearch的cmd窗口乱码问题(windows)
elasticsearch 7.6.0 windows版日志乱码问题解决 修改jvm.options,如何重启es即可 新增 -Dfile.encoding=GBK
- Ubu18开机自启动-Systemd
参考链接: https://blog.csdn.net/qq_16268979/article/details/114771854 本文内容为个人测试记录,具体文件目录请以读者自己电脑为准,此处只是提 ...
- WorkflowAsCode 来了,Apache DolphinScheduler 2.0.2 惊喜发布
文章目录 前言 01 新功能 1 WorkflowAsCode 2 企业微信告警方式支持群聊消息推送 02 优化 1 简化元数据初始化流程 2 删除补数日期中的"+1"(天) 03 ...
- vue 将markdown字符串转html、修改主题、生成目录
前言 将 markdown 字符串转成 html 显示出来,同时把目录也提取出来一起显示.可以使用 marked 来读取 markdown 字符串解析成 html marked官网:https://m ...
- 根节点选择器和 html 选择器
CSS 中除了用标签选择器选中<html>标签以外还有一个等价的是:root选择器.CSS 变量是有作用域的,全局变量都可以声明在<html>里. <div class= ...
- ceph 010 clustermap ceph调优
cluster map [ceph: root@clienta /]# ceph mon dump epoch 4 fsid 2ae6d05a-229a-11ec-925e-52540000fa0c ...