【论文解析】MTCNN论文要点翻译
目录
@
0.论文连接
1.前言
MTCNN是一篇关于人脸检测算法效果很不错的论文,落地效果也很好,据我所知有不少公司在用这个算法做人脸检测。
2.论文Abstract翻译
在无约束环境下,人脸的检测与对齐对于不同的姿势,灯光和遮挡是非常有挑战性的。近期的学术研究证明了深度学习方法在这两个任务上能够实现令人钦佩的性能。本文,我们提出了一个深度级联多任务框架,它能够利用人脸检测与对齐的内在相关性来提高他们的性能。尤其是我们的框架利用级联架构,分三个精心设计的深度卷积神经网络通过由粗糙到细致的方式来预测脸部整体和特征点的坐标。另外,我们提出了一种新的在线挖掘困难样本的策略,这样可以更好的提高模型的实际性能。我们的方法实现了卓越的准确性通过最先进的技术来应对挑战面向人脸检测的FDDB和WIDER FACE基准测试AFLW面部对齐基准,同时保持实时性能。
3.论文的主要贡献
- 提出了一种新的基于将脸部检测和对齐的一体化级联CNN框架,并且精心设计了一个轻量级的CNN框架,实现实时性能。
- 提出了一种有效可以在线生成困难样本挖掘的方法来提高性能。
在具有挑战性的基准上进行了大量的实验,通过与人脸对齐和检测上的先进方法的比较来显示本文模型优秀的性能提高。
4.算法流程
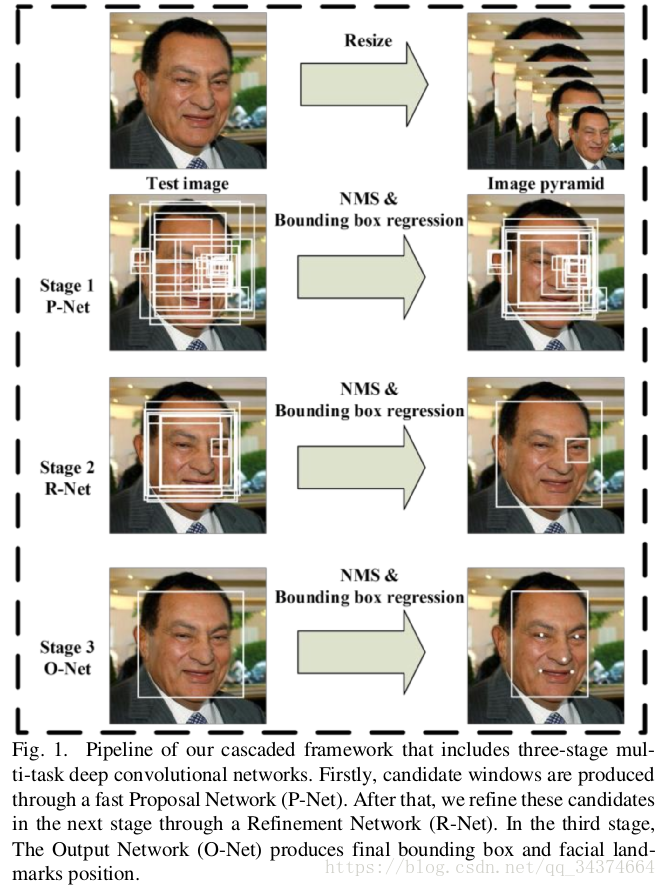
4.1 网络效果图
由图可知整体流程,首先对图片多尺度变换构建图像金字塔,作为网络的输入。接下来就是三层级联卷积网络。4.2 三层网络概述
4.2.1 P-Net
P-Net(Proposal Network)是一个全连接卷积神经网络,他粗略的获取脸部候选框跟边框回归变量,然后候选框通过边框回归变量(边框回归解释)进行校正。最后用NMS算法合并高度重合的候选框。
4.2.2 R-Net
将所有的候选框作为下层网络R-Net(Refine
Network)的输入,这个网络将会进一步拒绝大量的效果不好的候选框,然后同样的通过边框回归变量进行校正,NMS进行合并。4.2.3 O-Net
O-Net与R-Net较为相似,但是在这个网络的目标是通过更多的监督来识别面部的区域。特别的是,这个网络将会输出人脸的五个特征点。
4.3 网络的结构
在论文“A convolutional neural network cascade for face detection”中, 多种CNN被设计成可以做面部检测。但是,他的性能可能被以下几个因素限制:
- 在卷积层中的一些卷积层缺少多样性,那样会限制模型的识别能力。
与其他多类别的目标检测跟分类任务相比,人脸检测是一个具有挑战性的二分类任务,所以他的卷积层可能需要更少的卷积核。为此,我们减少卷积核的数量并且将5x5的卷积核变成3x3,因此在减少计算量同时增加深度并且获得更好的性能。
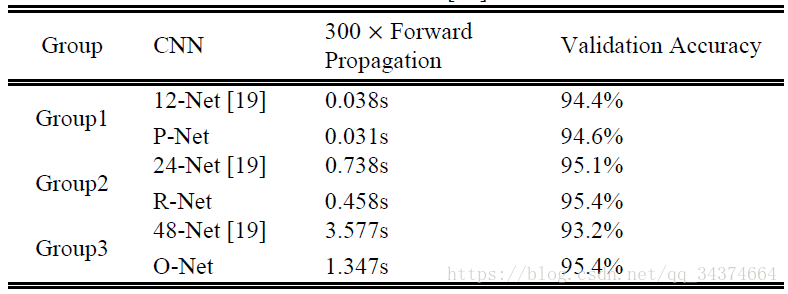
通过这些改善,与在论文“A convolutional neural network cascade for face detection”的网络结构相比,可以在更少的运行时间获得更好的性能。性能对比图如下,
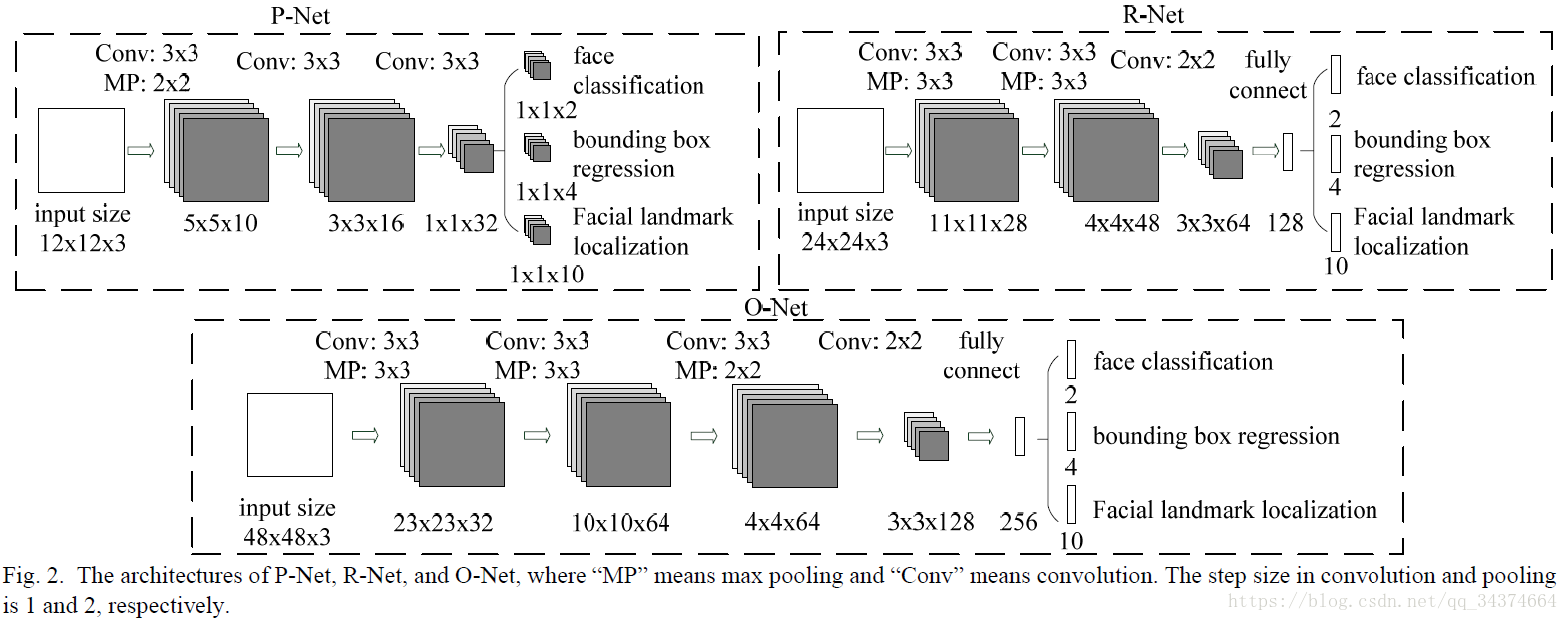
网络结构图如下
同时激活函数用的是PReLU.
4.4 训练
我们利用三项任务来训练我们的CNN检测器:人脸检测,边框回归,人脸特征点位置。
人脸检测:学习目标制定为一个二分类问题,对每个样本\(x_{i}\),我们用交叉熵损失函数:
\[L_{i}^{det} = -(y_{i}^{det}log(p_{i}) + (1-y_{i}^{det}) (1-log(p_{i})))\]
\(p_{i}\)是通过神经网络预测出样本\(x_{i}\)为人脸的概率。\(y_{i}^{det}\)代表ground-truth,$y_{i}^{det} \in $ {0, 1}边框回归:对于每个候选窗口,我们预测它与最近的ground truth之间的offset(例如回归框的左上角坐标以及高跟宽)。学习目标制定为回归问题,损失函数是平方损失函数:
\[L_{i}^{box} = ||\hat y^{box}_{i}-y_{i}^{box}||_{2}^{2}\]
\(\hat y_{i}^{box}\)是从网络中得到的回归目标,$ y_{i}^{box}$是ground-truth坐标,它是四维的,包括左上坐标,高度跟宽度。- 人脸特征点坐标:与边框回归类似,损失函数为: \[L_{i}^{landmark} = ||\hat y^{landmark}_{i} - y_{i}^{landmark}||^{2}_{2}\]
同样,\(\hat y_{i}^{landmark}\)是从网络中得到的特征点坐标, \(y_{i}^{landmark}\)是ground-truth的坐标,有五个坐标,分别是两只眼睛,两个嘴角跟一个鼻子。 - 多源(Multi-source)训练: 因为在每个CNN中有不同的任务,所以在学习过程中会有不同的训练数据集,在训练某个特指任务时,其他任务损失值应该为零,因此一个综合所有任务的损失函数如下:
\[min{\sum_{i = 1}^{N}\sum_{j \in \{det, box, landmark\} }\alpha_{j}\beta_{i}^{j}L_{i}^{j}}\]
其中N代表训练样本的数量,\(a_{j}\)代表每个任务的重要程度,在P-Net跟R-Net中, \(\alpha_{det} = 1, \alpha_{box} = 0.5, \alpha_{landmark} = 0.5\)然而在O-Net中为了人脸特征点坐标更高的准确率,参数设置为\(\alpha_{det} = 1, \alpha_{box} = 0.5, \alpha_{landmark} = 1\),\(\beta_{i}^{j} \in \{0,1\}\)是样本类型的指示器,在这种情况下,可以很自然的使用随机梯度下降来训练这些CNN。 在线挖掘困难样本:不同于传统方式,需要在原始分类器训练完之后进行困难样本挖掘,实现在线操作。在每一小批量样本中,对其按照前向传播所有样本的损失值进行排序,并且选取前70%作为“hard samples”,从而在反向传播中,我们只计算“hard samples”的梯度。这意味着,训练时我们将忽略那些对增强模型性能作用较小的简单样本。实验证明这种策略相对手动选择困难样本有更好的性能。
5 模型性能分析
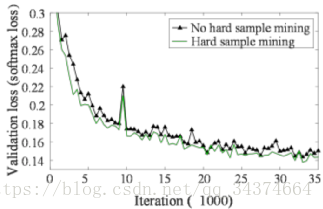
5.1 关于在线挖掘困难样本的性能
为了体现性能,论文训练了两个O-Net,他们的初始参数全部一样,一个进行“online hard sample mining”一个不进行,画出他们的学习曲线如下:
5.2 将人脸检测与对齐联合的性能
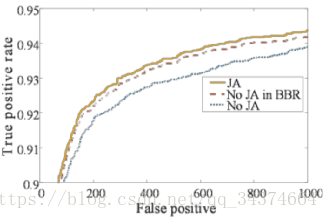
为了测试贡献,同样训练两个相同的O-Net,一个"joint facial landmarks regression",另一个并不进行上述操作,对比其两者的性能,同时对比边框回归的性能。可以发现加入人脸特征点坐标的学习对人脸检测与边框回归都起到了有益的作用,如下图:
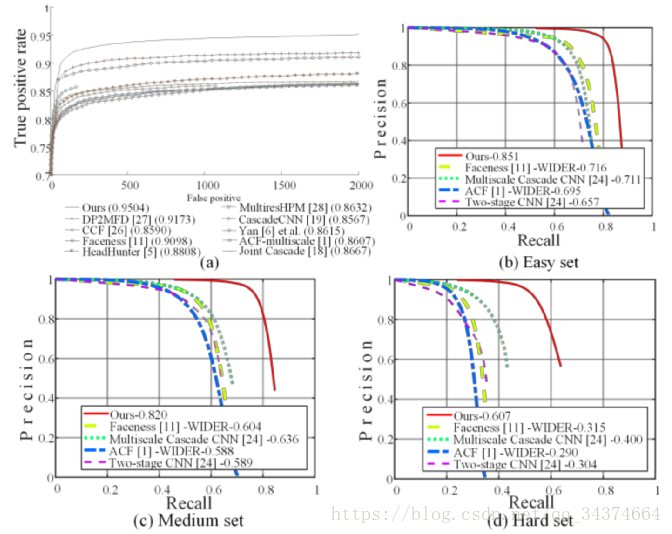
5.3 人脸检测的效果
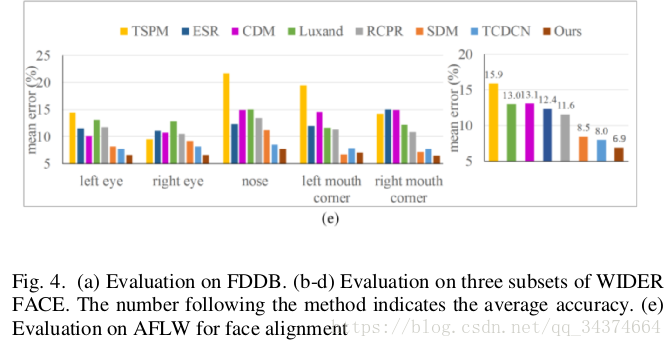
与各算法在各数据集上的对比图:
6 代码阅读[待更新]
7 感悟&&心得
此部分等阅读完代码,彻底理解算法进行补充
【论文解析】MTCNN论文要点翻译的更多相关文章
- [Network Architecture]Mask R-CNN论文解析(转)
前言 最近有一个idea需要去验证,比较忙,看完Mask R-CNN论文了,最近会去研究Mask R-CNN的代码,论文解析转载网上的两篇博客 技术挖掘者 remanented 文章1 论文题目:Ma ...
- 视频教学动作修饰语:CVPR2020论文解析
视频教学动作修饰语:CVPR2020论文解析 Action Modifiers: Learning from Adverbs in Instructional Videos 论文链接:https://a ...
- 无监督域对抗算法:ICCV2019论文解析
无监督域对抗算法:ICCV2019论文解析 Drop to Adapt: Learning Discriminative Features for Unsupervised Domain Adapta ...
- 将视频插入视频:CVPR2019论文解析
将视频插入视频:CVPR2019论文解析 Inserting Videos into Videos 论文链接: http://openaccess.thecvf.com/content_CVPR_20 ...
- Joint Extraction of Entities and Relations论文解析
1. 前言 实体和关系的联合抽取问题作为信息抽取的关键任务,其实现方法可以简单分为两类: 一类是串联抽取方法.传统的串联抽取就是首先进行实体抽取,然后进行关系识别.这种分开的方法比较容易实现,而且各个 ...
- LTMU论文解析
LTMU 第零部分:前景提要 一般来说,单目标跟踪任务可以从以下三个角度解读: A matching/correspondence problem.把其视为前后两帧物体匹配的任务(而不考虑在跟踪过程中 ...
- CVPR2020论文解析:实例分割算法
CVPR2020论文解析:实例分割算法 BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation 论文链接:https://arxiv ...
- 人脸真伪验证与识别:ICCV2019论文解析
人脸真伪验证与识别:ICCV2019论文解析 Face Forensics++: Learning to Detect Manipulated Facial Images 论文链接: http://o ...
- 人体姿态和形状估计的视频推理:CVPR2020论文解析
人体姿态和形状估计的视频推理:CVPR2020论文解析 VIBE: Video Inference for Human Body Pose and Shape Estimation 论文链接:http ...
- 分层条件关系网络在视频问答VideoQA中的应用:CVPR2020论文解析
分层条件关系网络在视频问答VideoQA中的应用:CVPR2020论文解析 Hierarchical Conditional Relation Networks for Video Question ...
随机推荐
- Spring Boot 编写入门程序
1. SpringBoot 入门 快速创建独立运行的Spring项目以及与主流框架集成; 使用嵌入式的Servlet容器,应用无需打成WAR包; starters自动依赖与版本控制; 大量的自动配置, ...
- 【react表格组件】react-virtualized虚拟列表
https://css-tricks.com/rendering-lists-using-react-virtualized/
- MFC中使用用户剪贴板
代码逻辑: 拷贝功能: 1.从编辑控件中获取文本. 2.打开并清空剪贴板.(OpenClipboard,EmptyClipboard) 3.创建一个全局缓冲区.(GlobalAlloc) 4.锁定缓冲 ...
- django中同源策略和跨域解决方案
一 同源策略 1.1何谓同源? 如果两个页面的协议,端口(如果有指定)和域名都相同,则两个页面具有相同的源. 举个例子: 下表给出了相对http://a.xyz.com/dir/page.html同 ...
- 程序猿Web面试之jQuery
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/powertoolsteam/article/details/32325013 又到了一年一度的 ...
- 《Python入门》Windows 7下Python Web开发环境搭建笔记
最近想尝试一下在IBM Bluemix上使用Python语言创建Web应用程序,所以需要在本地搭建Python Web的开发测试环境. 关于Python的版本 进入Python的网站,鼠标移到导航条上 ...
- 001-navicat for oracle 12 破解安装
1.首先软件包和破解文件都需要到我给的百度云盘地址下载,去官网下载的中文版破解不了,至于官网的英文版,我就不清楚了. (1)链接地址. https://pan.baidu.com/s/1jxj4uzg ...
- 开源BBS论坛软件推荐
七款开源BBS论坛软件推荐(1) 本文介绍了七个开源的BBS论坛软件(在英文界一般叫做Forum).可能国内的朋友们比较熟悉Discuz!和PHPwind,但其实我们的选择还是很多的,而且下面介绍的这 ...
- 干货!Jenkins下配置findbugs、pmd及checkstyle实现代码自动检测
配置前提: 对于maven项目来说,需要在pom.xml文件的<build><plugins>添加配置</plugins></build> 网上有些地方 ...
- web前端基础——初识CSS
1 CSS概要 CSS(Cascading Style Sheets)称为层叠样式表,用于美化页面(单纯HTML写的页面只是网页框架和内容的组合,相当于赤裸的人,而CSS则是给赤裸的人穿上华丽的外衣) ...