kafka log文件和offset原理
log与offset
日志存储路径根据配置log.dirs ,日志文件通过 topic-partitionId分目录,再通过log.roll.hours 和log.segment.bytes来分文件,默认是超过7天,或者是1GB大小就分文件,在kafka的术语中,这被称为段(segment )。例如00000000000000033986.log,文件名就是offset,除了数据文件之外,相应的还有一个index文件,例如00000000000000033986.index。记录的是该数据文件的offset和对应的物理位置,正是有了这个index文件,才能对任一数据写入和查看拥有O(1)的复杂度,index文件的粒度可以通过参数log.index.interval.bytes来控制,默认是是每过4096字节记录一条index,太小意味着读取效率更高但是index文件会变大。基于这个特性,可以根据时间找到粗粒度的offset。(0.10.0.1版本之后增加记录了时间戳,粒度更细)
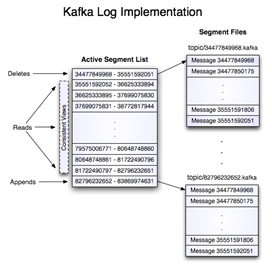
官方展示的log和segment关系
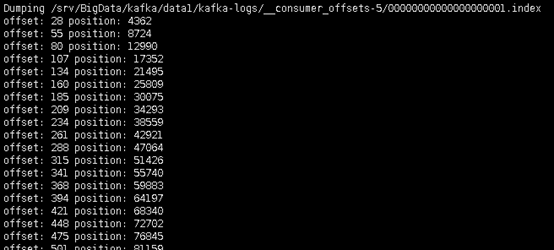
可以通过命令手动查看index文件
# /srv/BigData/kafka/data1/kafka-logs这个路径就是log.dirs,topic-9是topic-partitionId
./kafka-run-class.sh kafka.tools.DumpLogSegments --files /srv/BigData/kafka/data1/kafka-logs/topic-9/00000000000000033986.index
通过log找message流程
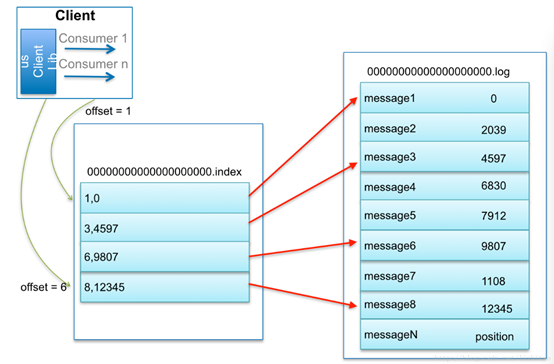
比如:要查找绝对offset为7的Message:
- 用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。
- 打开这个Segment的index文件,也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。
- 打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
// 官方文档
http://kafka.apache.org/0100/documentation.html#log
kafka log文件和offset原理的更多相关文章
- mongodb底层存储和索引原理——本质是文档数据库,无表设计,同时wiredTiger存储引擎支持文档级别的锁,MMAPv1引擎基于mmap,二级索引(二级是文档的存储位置信息『文件id + 文件内offset 』)
MongoDB是面向文档的数据库管理系统DBMS(显然mongodb不是oracle那样的RDBMS,而仅仅是DBMS). 想想一下MySQL中没有任何关系型数据库的表,而由JSON类型的对象组成数据 ...
- Kafka史上最详细原理总结
https://blog.csdn.net/ychenfeng/article/details/74980531 Kafka Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(pa ...
- kafka消息存储与partition副本原理
消息的存储原理: 消息的文件存储机制: 前面我们知道了一个 topic 的多个 partition 在物理磁盘上的保存路径,那么我们再来分析日志的存储方式.通过 ll /tmp/kafka-logs/ ...
- kafka存储机制以及offset
1.前言 一个商业化消息队列的性能好坏,其文件存储机制设计是衡量一个消息队列服务技术水平和最关键指标之一.下面将从Kafka文件存储机制和物理结构角度,分析Kafka是如何实现高效文件存储,及实际应用 ...
- 【转载】Kafka史上最详细原理总结
Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量 ...
- Kafka数据安全性、运行原理、存储
直接贴面试题: 怎么保证数据 kafka 里的数据安全? 答: 生产者数据的不丢失kafka 的 ack 机制: 在 kafka 发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够 ...
- 大数据之Kafka史上最详细原理总结
Kafka Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实 ...
- Kafka(二)设计原理
1.持久性 kafka使用文件存储消息,这就直接决定kafka在性能上严重依赖文件系统的本身特性.且无论任何OS下,对文件系统本身的优化几乎没有可能.因为kafka是对日志进行append操作,因此磁 ...
- Kafka消息文件存储
在对消息进行存储和缓存时,Kafka依赖于文件系统.(Page Cache) 线性读取和写入是所有使用模式中最具可预计性的一种方式,因而操作系统采用预读(read-ahead)和后写(write-be ...
随机推荐
- react native 或 flutter 开发app
react-native react native和原生Android/ios: https://www.oschina.net/news/97466/should-we-use-react-nati ...
- Spark Standalone Mode 单机启动Spark -- 分布式计算系统spark学习(一)
spark是个啥? Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发. Spark和Hadoop有什么不同呢? Spark是基于map reduce算法实现的分布式计算,拥 ...
- redis之数据操作详解
redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorted set ...
- 前端 javascript 变量
变量: python: name = 'alex' JavaScript: name = 'alex' # 全局变量 声明var var name = 'eric' # 局部变量 写全局变量基本好少J ...
- Spark的集群管理器
上篇文章谈到Driver节点和Executor节点,但是如果想要运行Driver节点和Executor节点,就不能不说spark的集群管理器.spark的集群管理器大致有三种,一种是自带的standa ...
- CentOS6.8 yum 安装 mysql5.7.12 完美步骤
一,wget http://dev.mysql.com/get/mysql57-community-release-el6-8.noarch.rpm 二,yum localinstall mysql5 ...
- 1141 PAT Ranking of Institutions[难]
1141 PAT Ranking of Institutions (25 分) After each PAT, the PAT Center will announce the ranking of ...
- Python:6种标准数据类型
原文地址https://www.cnblogs.com/qin1991/p/5910145.html #!/usr/bin/python3 #python的基本语法和数据类型 #python3中 一行 ...
- select 自动选择 检查下拉列表
下面我们来看一下selenium webdriver是如何来处理select下拉框的,以Apple注册页面为例. https://appleid.apple.com/cgi-bin/WebObject ...
- FileLoadTools
/** * Created by dev013 on 9/9/14. */ var FileLoadTools = (function () { var my = {}; var htmlFile = ...