Hadoop入门简介
一、Hadoop简介
1.1、Hadoop主要进行分布式存储和分布式计算
1.1-1、HDFS:分布式文件系统
1.1-2、MapReduce:并行计算框架
1.2、Hadoop用来做什么?
搭建大型的数据仓库
搜索引擎、日志分析、数据挖掘
1.3、优势:
高扩展、低成本、成熟的生态圈
二、Hadoop核心
2.1、HDFS
2.1.1 简介
文件被分成块进行存储(默认块的大小是64MB),HDFS两个重要节点NameNode和DataNode
1)NameNode:管理节点,存储源文件
(1)存储文件与数据块的映射表
(2)存储数据块与DataNode的映射表
2)DataNode:数据节点
用于存放数据块
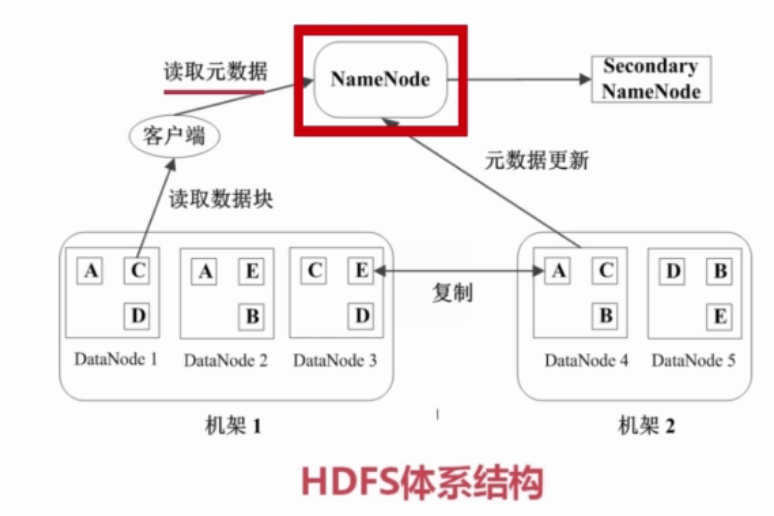
2.1.3 HDFS的数据存储和容错
1)对每个数据块存储3份,2份在同一机架,1份在另一机架
2)心跳检测,DataNode定期向NameNode发送心跳消息。
3)二级NameNode(对NameNode的数据进行同步备份,),NameNode故障以后,切换到二级NameNode
2.1.4 HDFS文件读取
1)读取文件
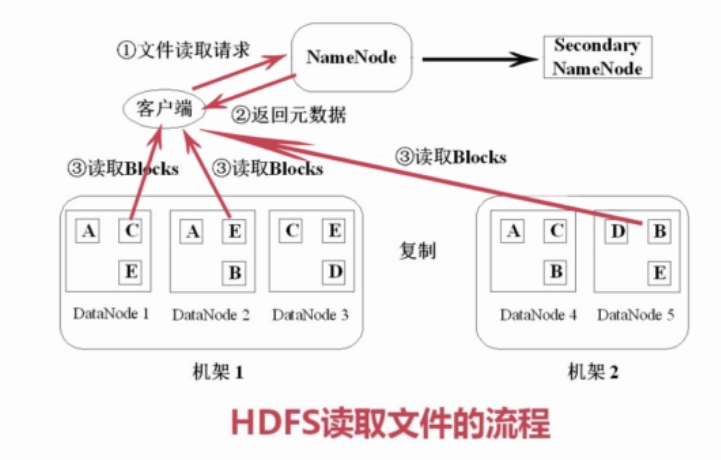
(1) 客户端向NameNode请求数据
(2) NameNode查询源数据,回复客户端,文件包括哪些块,这些块分别位于哪个DataNode
(3)客户端分别对DataNode读取块,将block组装成源文件
2)写文件
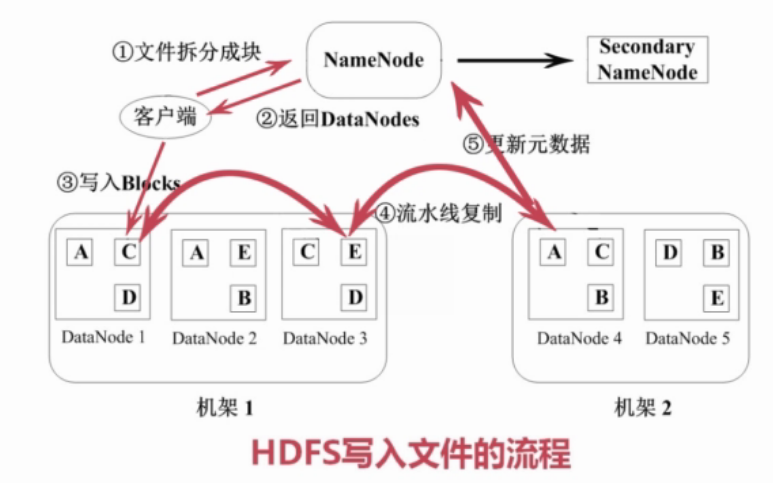
(1)客户端将文件拆分成块,发送给NameNode
(2)NameNode发挥给客户端一系列可用的DataNode
(3)客户端将数据写入到DataNode,
(4)DataNode对数据进行流水线复制,保留三份
(5)更新源数据,DataNode向NameNode汇报数据
2.1.5 HDFS的特点
1) 数据冗余,硬件容错(三备份)
2) 流式数据访问(1次写入,多次读取,写入后无法修改)
3) 适合存储大文件,(小文件对NameNode的负载压力大)
2.1.6 HDFS适应性和局限性
1) 适合数据批量读写,吞吐量高。不适合交互式应用,低延时很满足(例如数据库)
2) 适合一次写入,多次读取,顺序写入。不支持多用户并发写相同的文件。
2.2、MapReduce
2.2.1 简介
MapReduce(一个大任务分成小的子任务,并行执行后,合并结果)
Map:大任务拆分成多个子任务
Reduce:并行计算后,合并结果
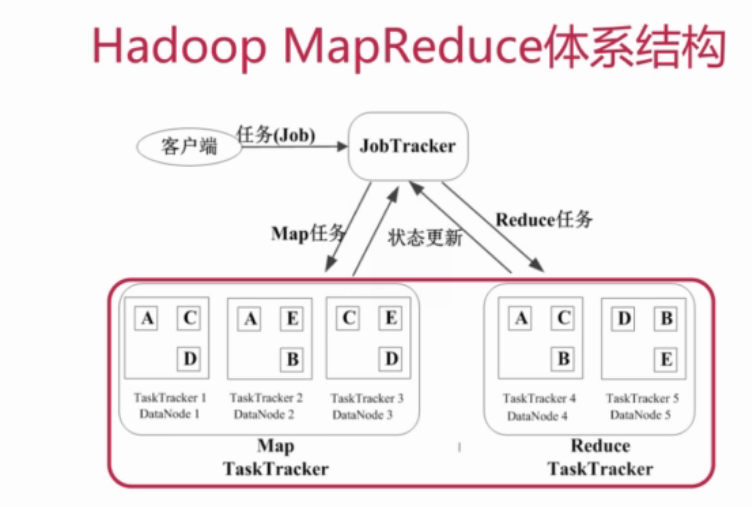
2.2.2 MapReduce运行流程
1、基本概念
-Job & Task(一个Job分成多个task,task分为MapTask和ReduceTask)(例如统计日志中每个IP出现的次数,这就是一个Job)
-JobTracker:作业调度、分配任务、监控任务执行进度、监控TaskTracker的状态
-TaskTracker:执行任务、向JobTracker汇报任务状态
一般配置的时候,TaskTracker与HDFS的DataNode配置在同一节点。
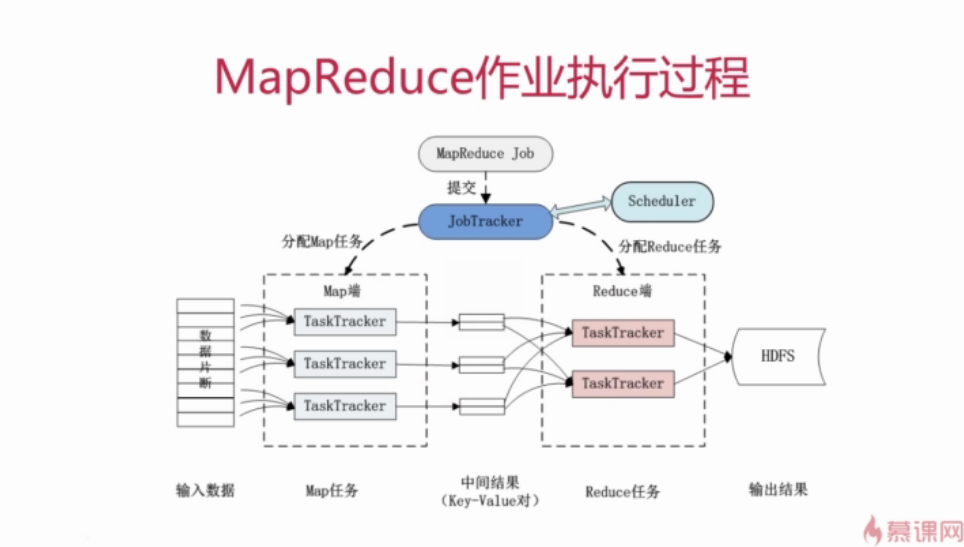
2.2.3 MapReduce的容错机制
1、重复执行(般重复执行4次以后就会放弃)
2、推测执行:对于一个执行特别慢的TaskTracker(预测可能出现故障),在另一台机器上面重新开一个TaskTracker,执行相同的计算,两者谁先执行完,用谁的数据
2.2.4开发Hadoop应用程序
(未完待续)
Hadoop入门简介的更多相关文章
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- Hadoop入门学习笔记---part1
随着毕业设计的进行,大学四年正式进入尾声.任你玩四年的大学的最后一次作业最后在激烈的选题中尘埃落定.无论选择了怎样的选题,无论最后的结果是怎样的,对于大学里面的这最后一份作业,也希望自己能够尽心尽力, ...
- Linux系统入门简介<1>
linux系统入门简介 我们为什么要学习Linux? 在介绍Linux的历史前,我想先针对大家如何对Linux的发音说一下.我发现我身边的朋友对Linux的发音大致有这么几种: "里那克斯& ...
- [转帖]Flink(一)Flink的入门简介
Flink(一)Flink的入门简介 https://www.cnblogs.com/frankdeng/p/9400622.html 一. Flink的引入 这几年大数据的飞速发展,出现了很多热门的 ...
- Hadoop入门学习笔记---part4
紧接着<Hadoop入门学习笔记---part3>中的继续了解如何用java在程序中操作HDFS. 众所周知,对文件的操作无非是创建,查看,下载,删除.下面我们就开始应用java程序进行操 ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- Hadoop入门学习笔记---part2
在<Hadoop入门学习笔记---part1>中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱.不够系统化,不够简洁.经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建ha ...
- 初识Hadoop入门介绍
初识hadoop入门介绍 Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不适用我们的项目,但是我会继续研究下去,技多不压身. < ...
- 掌握 Ajax,第 1 部分: Ajax 入门简介
转:http://www.ibm.com/developerworks/cn/xml/wa-ajaxintro1.html 掌握 Ajax,第 1 部分: Ajax 入门简介 理解 Ajax 及其工作 ...
随机推荐
- tomcat7 1000并发量配置 tomcat7配置优化
修改tomcat/conf/server.xml配置文件. <Executor name="tomcatThreadPool" namePrefix="catali ...
- WCF中配置文件解析
WCF中配置文件解析[1] 2014-06-14 WCF中配置文件解析 参考 WCF中配置文件解析 返回 在WCF Service Configuration Editor的使用中,我们通过配置工具自 ...
- hdu1051(LIS | Dilworth定理)
这题根据的Dilworth定理,链的最小个数=反链的最大长度 , 然后就是排序LIS了 链-反链-Dilworth定理 hdu1051 #include <iostream> #inclu ...
- 函数lock_rec_add_to_queue
在原来的type_mode基础上,加上LOCK_REC /*********************************************************************// ...
- 使用tdcss.js轻松制作自己的style guide
http://jakobloekke.github.io/tdcss.js/ 在前端开发中,如果能够有一个style guide对于设计来说就显得专业稳定,一致性.在上述链接中,有一个tdcss.js ...
- SPOJ ARCTAN (数论) Use of Function Arctan
详细的题解见这里. 图片转自上面的博客 假设我们已经推导出来x在处取得最小值,并且注意到这个点是位于两个整点之间的,所以从这两个整数往左右两边枚举b就能找到b+c的最小值. 其实只用往一边枚举就够了, ...
- HDU 1512 Monkey King
左偏树.我是ziliuziliu,我是最强的 #include<iostream> #include<cstdio> #include<cstring> #incl ...
- cocoStudio UI编辑器 学习总结
一.控件 控件基类 UIWidget:所有UI控件的基类 addChild:添加UIWidget类型的节点 addRenderer:添加CCNode类型的节点 所有UIWidget,都可以设置成触摸s ...
- 支持向量机之Hinge Loss 解释
Hinge Loss 解释 SVM 求解使通过建立二次规划原始问题,引入拉格朗日乘子法,然后转换成对偶的形式去求解,这是一种理论非常充实的解法.这里换一种角度来思考,在机器学习领域,一般的做法是经验风 ...
- nodejs开发阶段利器supervisor
在开始学习nodejs时,往往一般写代码,一边看效果.先停止node,再重新运行.非常耗时. 这时supervisor派上了用场. 安装 推荐使用npm,本人一直使用局部安装,这样可以将全部文件安装在 ...