ID3算法 决策树的生成(2)
决策树的生成,采用ID3算法(也包含了C4.5算法),使用python实现,更新了tree的保存和图示。
介绍摘自李航《统计学习方法》。
5.2.3 信息增益比
信息增益值的大小是相对于训练数据集而言的,并没有绝对意义。在分类问题困难时,也就是说在训练数据集的经验熵大的时候,信息增益值会偏大。反之,信息增益值会偏小。使用信息增益比(information gain ratio)可以对这一问题进行校正。这是特征选择的另一准则。
定义5.3(信息增益比) 特征A对训练数据集D的信息增益比gR(D,A)定义为其信息增益g(D,A)与训练数据集D的经验熵H(D)之比:

5.3.2 C4.5的生成算法
C4.5算法与ID3算法相似,C4.5算法对ID3算法进行了改进。C4.5在生成的过程中,用信息增益比来选择特征。
算法5.3(C4.5的生成算法)
输入:训练数据集D,特征集A,阈值 ε;
ε;
输出:决策树T。
(1)如果D中所有实例属于同一类Ck,则置T为单结点树,并将Ck作为该结点的类,返回T;
(2)如果A=Ø,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类,返回T;
(3)否则,按式(5.10)计算A中各特征对D的信息增益比,选择信息增益比最大的特征Ag;
(4)如果Ag的信息增益比小于阈值,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类,返回T;
(5)否则,对Ag的每一可能值ai,依Ag=ai将D分割为子集若干非空Di,将Di中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
(6)对结点i,以Di为训练集,以A-{Ag}为特征集,递归地调用步(1)~步(5),得到子树Ti,返回Ti。
# coding:utf-8
import matplotlib.pyplot as plt
import numpy as np
import pylab def createDataSet(): #贷款申请样本数据表
dataset = [["青年", "否", "否", "一般", "拒绝"],
["青年", "否", "否", "好", "拒绝"],
["青年", "是", "否", "好", "同意"],
["青年", "是", "是", "一般", "同意"],
["青年", "否", "否", "一般", "拒绝"],
["中年", "否", "否", "一般", "拒绝"],
["中年", "否", "否", "好", "拒绝"],
["中年", "是", "是", "好", "同意"],
["中年", "否", "是", "非常好", "同意"],
["中年", "否", "是", "非常好", "同意"],
["老年", "否", "是", "非常好", "同意"],
["老年", "否", "是", "好", "同意"],
["老年", "是", "否", "好", "同意"],
["老年", "是", "否", "非常好", "同意"],
["老年", "否", "否", "一般", "拒绝"],
]
labels = ["年龄", "有工作", "有房子", "信贷情况"]
return dataset, labels def getList(dataset,index=-1):#返回每层列表
alist=[i[index] for i in dataset]
aset=list(set(alist))
acount=[alist.count(aset[j]) for j in range(len(aset))]
return alist,aset,acount def getdH(account): #计算H(D)
t=np.sum(account)
return np.sum([-float(a)/t*np.log2(float(a)/t) for a in account]) def getdaH(acount,ad): #计算H(D,A)
t=np.sum(acount)
return np.sum([[0 if j==0 else -a*float(j)/t/a*np.log2(float(j)/a) for j in b] for a,b in zip(acount,ad)]) def gethaD(acount): #计算Ha(D)
t=np.sum(acount)
return np.sum([ -float(a)/t*np.log2(float(a)/t) for a in acount]) def getaH(dataset,index,c4_5=0): #计算g(D,A),若c4_5=1则采用信息增益比
dlist,dset,dcount= getList(dataset,-1)
hd=getdH(dcount)
alist,aset,acount=getList(dataset,index)
ad=[[[dlist[i] for i in range(len(dlist)) if dataset[i][index]==j].count(k) for k in dset] for j in aset]
if c4_5:
return 0 if gethaD(acount)==0 else (hd-getdaH(acount,ad))/gethaD(acount)
else:
return hd-getdaH(acount,ad) def ID3(dataset,labels,tree=[]):#ID3算法
dlist,dset,dcount= getList(dataset,-1)
if len(dset)<2 :
tree.append([dset[0],0])
return
adlist=[[getaH(dataset,i),i] for i in range(len(dataset[0])-1)]
t1= max(adlist,key=lambda x: x[0])
tree.append([labels[t1[1]],2])
alist,aset,acount=getList(dataset,t1[1])
for a in aset:
tree.append([a,1])
ID3([i for i in dataset if i[t1[1]]==a],labels,tree)
return tree def showT(tree):#根据Tree列表绘制图像
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
pylab .mpl.rcParams['font.sans-serif'] = ['SimHei']
fig1 = plt.figure(1, (6, 6))
ax = fig1.add_axes([0, 0, 1, 1], frameon=False, aspect=1.)
x,y=0.5,0.85
for i in range(len(tree)):
if tree[i][1]==2:
fig1.text(x,y, tree[i][0],ha="center",size=21,bbox=dict(boxstyle="square", fc="w", ec="k"))
ax.arrow(x,y-0.02, 0.09,-0.11, head_width=0.01, head_length=0.02, fc='k', ec='k')
ax.arrow(x,y-0.02, -0.09,-0.11, head_width=0.01, head_length=0.02, fc='k', ec='k')
x+=0.05
y-=0.1
if i>1:tree[i-2][1]-=1
elif tree[i][1]==1:
fig1.text(x+0.05,y, tree[i][0],ha="center",size=21)
x+=0.05
y-=0.1
else:
fig1.text(x,y, tree[i][0],ha="center",size=21,bbox=dict(boxstyle="square", fc="w", ec="k"))
x-=0.25
y+=0.1
j=i-2
while tree[j][1]==0:
j=j-2
x+=0.1
y+=0.2
tree[j][1]-=1
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
plt.draw()
plt.show() dataset,labels=createDataSet()
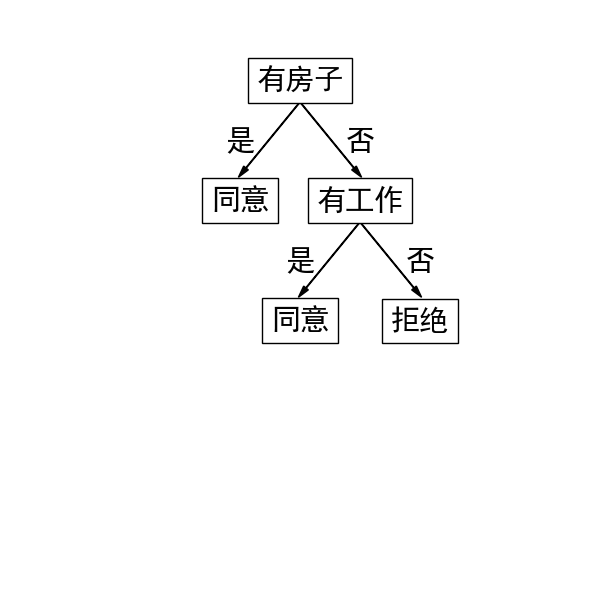
tree= ID3(dataset,labels) #[["有房子",2],["否",1],["有工作",2],["否",1],["拒绝",0],["是",1],["同意",0],["是",1],["同意",0]]
showT(tree)
ID3算法 决策树的生成(2)的更多相关文章
- ID3算法 决策树的生成(1)
# coding:utf-8 import matplotlib.pyplot as plt import numpy as np import pylab def createDataSet(): ...
- ID3算法 决策树 C++实现
人工智能课的实验. 数据结构:多叉树 这个实验我写了好久,开始的时候从数据的读入和表示入手,写到递归建树的部分时遇到了瓶颈,更新样例集和属性集的办法过于繁琐: 于是参考网上的代码后重新写,建立决策树类 ...
- Python 实现基于信息熵的 ID3 算法决策树模型
版本说明 Python version: 3.6.6 |Anaconda, Inc.| (default, Jun 28 2018, 11:21:07) [MSC v.1900 32 bit (Int ...
- 决策树---ID3算法(介绍及Python实现)
决策树---ID3算法 决策树: 以天气数据库的训练数据为例. Outlook Temperature Humidity Windy PlayGolf? sunny 85 85 FALSE no ...
- 02-21 决策树ID3算法
目录 决策树ID3算法 一.决策树ID3算法学习目标 二.决策树引入 三.决策树ID3算法详解 3.1 if-else和决策树 3.2 信息增益 四.决策树ID3算法流程 4.1 输入 4.2 输出 ...
- 决策树笔记:使用ID3算法
决策树笔记:使用ID3算法 决策树笔记:使用ID3算法 机器学习 先说一个偶然的想法:同样的一堆节点构成的二叉树,平衡树和非平衡树的区别,可以认为是"是否按照重要度逐渐降低"的顺序 ...
- 数据挖掘之决策树ID3算法(C#实现)
决策树是一种非常经典的分类器,它的作用原理有点类似于我们玩的猜谜游戏.比如猜一个动物: 问:这个动物是陆生动物吗? 答:是的. 问:这个动物有鳃吗? 答:没有. 这样的两个问题顺序就有些颠倒,因为一般 ...
- 决策树 -- ID3算法小结
ID3算法(Iterative Dichotomiser 3 迭代二叉树3代),是一个由Ross Quinlan发明的用于决策树的算法:简单理论是越是小型的决策树越优于大的决策树. 算法归 ...
- 决策树-预测隐形眼镜类型 (ID3算法,C4.5算法,CART算法,GINI指数,剪枝,随机森林)
1. 1.问题的引入 2.一个实例 3.基本概念 4.ID3 5.C4.5 6.CART 7.随机森林 2. 我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款? ...
随机推荐
- 《用C++语言编写一个程序,求PI的值》
//编写一个C++程序求PI的值 /* PI=16arctan(1/5)-4arctan(1/239) 其中arctan用如下形式的极数计算: arctan=x-(x^3/3)+(x^5/7)-(x^ ...
- SVG 2D入门2 - 图形绘制
基本形状 SVG提供了很多的基本形状,这些元素可以直接使用,这一点比canvas好多了.废话不说了,直接看例子,这个最直接: <svg width="200" heigh ...
- golang vim环境搭建
主要使用到的是golang的vim插件vim-go, 安装方法: (1)配置好自己的GOPATH和GOROOT: (2)在GOPATH目录下建立 src.pkg.main.bin四个目录: (3)安装 ...
- Java三大主流开源工作流引擎技术分析
首先,这个评论是我从网上,书中,搜索和整理出来的,也许有技术点上的错误点,也许理解没那么深入.但是我是秉着学习的态度加以评论,学习,希望对大家有用,进入正题! 三大主流工作流引擎:Shark,oswo ...
- 通过AssetsLibrary框架访问所有相片
该框架下有几个类,ALAssetsLibrary,ALAssetsGroup,ALAsset,ALAssetsFilter,ALAssetRepresentation. ALAssetsLibrary ...
- ZJOI 仓库建设 (斜率DP)
f[i]=min(f[j]+w[j,i])+c[i]; j∈[0,i-1] w[j,i]=p[j+1]*(x[i]-x[j+1])+...+p[i]*(x[i]-x[i]); 最裸的DP是n^2的, ...
- nno_setup制作升级包必须面临的几个问题 2
这两天的时间一直在制作应用程序的升级包,期间碰到一些问题这里一并记录下来,相信这是制作升级包必须面临和解决的问题: 1. 升级包安装程序如何不再产生新的安装.卸载程序 Inno_setup中AppId ...
- 【转】Paxos算法深入分析
http://blog.csdn.net/anderscloud/article/details/7175209 在分布式系统设计领域,Paxos可谓是最重要一致性的算法.Google的大牛们称 ...
- MySQL数据库备份和还原的常用命令小结
备份MySQL数据库的命令 mysqldump -hhostname -uusername -ppassword databasename > backupfile.sql 备份MySQL数据库 ...
- tracking 问题解决
1.dir,或者C++函数读文件名,不推荐.搞乱了名字 2. matio读写矩阵