hadoop1.2.1配置文件
1)core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>Hadoop.tmp.dir</name>
<value>/home/hadoop/HadoopData/tmp</value>
</property>
</configuration>
hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它,并且NameNode的元数据备份等信息也会放在此这个目录下,如果不配置,其默认路径是/tmp,而/tmp是系统的临时目录,系统重启时往往会被清空,所以需要自定义一个持久化的数据目录。如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中。
fs.default.name参数意义就是Namenode的地址和RPC端口。
2)hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
dfs.replication表示为了保证数据的可靠性而设置块的复制数量(默认为3)
dfs.name.dir表示存储NameNode元数据的目录(默认值是${hadoop.data.dir}/dfs/name,这个是名称节点上的路径)
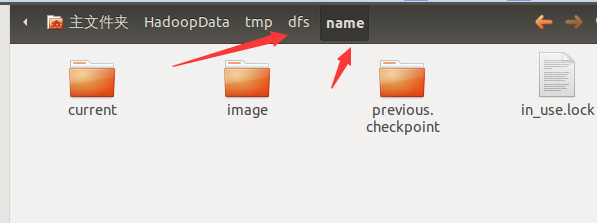
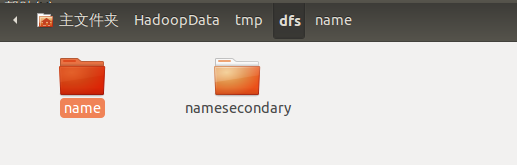
dfs.data.dir表示数据块的datanode中存储的目录((默认值是${hadoop.data.dir}/dfs/data,这个是数据节点上的路径)
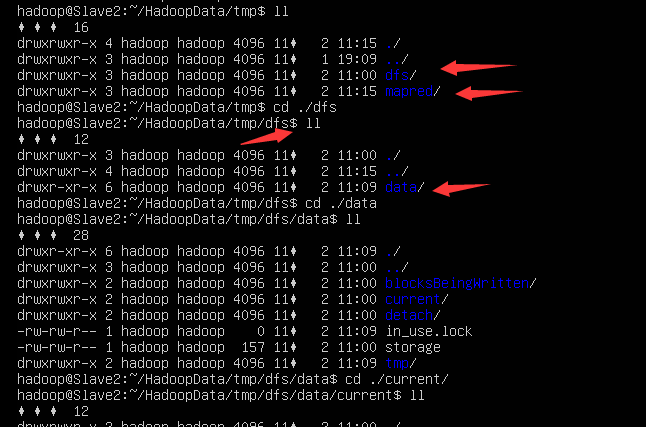
DataNode节点存储数据块的位置(以Slave2为例):有dfs和mapred目录,其中dfs存储用于MR计算的数据节点块,mapred存放中间计算结果(比如map阶段spill的数据)
3)mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>Master:</value>
</property>
</configuration>
mapred.job.tracker表示RPC地址和端口号。并且,此文件中不能有空白行出现。
hadoop1.2.1配置文件的更多相关文章
- Hadoop1.2.1 配置文件详解
首先我们先回顾一下Hadoop的一些概念: Apache Hdoop 1.x 组成 NameNode(元数据服务器) Secondary NameNode(辅助元数据服务器) JobTracker(任 ...
- Hadoop1.x安装配置文件及参数说明
一.常用文件及参数说明Core-site.xml 配置Common组件的属性 hdfs-site.xml 配置hdfs参数,比如备份数目,镜像存放路径 Mapred-sit ...
- hadoop1.0.4升级到hadoop2.2 具体流程步骤
hadoop1.x 升级到hadoop2.2 本文參考了博客:http://blog.csdn.net/ajax_jquery/article/details/27311671,对一些地方做了改动. ...
- hadoop 配置安装
1. 下载hadoop 压缩包, 拷贝到 /usr/hadoop目录下 tar -zxvf hadoop-2.7.1.tar.gz, 比如: 127.0.0.1 localhost 19 ...
- 本地调试hbase
需求说明 如果要本地调试Hbase程序,那么可以用本地连接集群的方式 配置文件 在maven里,配置文件cluster.properties放在target/classes里 cluster.prop ...
- Ubuntu环境下Hadoop1.2.1, HBase0.94.25, nutch2.2.1各个配置文件一览
/×××××××××××××××××××××××××××××××××××××××××/ Author:xxx0624 HomePage:http://www.cnblogs.com/xxx0624/ ...
- Hadoop1 Centos伪分布式部署
前言: 毕业两年了,之前的工作一直没有接触过大数据的东西,对hadoop等比较陌生,所以最近开始学习了.对于我这样第一次学的人,过程还是充满了很多疑惑和不解的,不过我采取的策略是还是先让环 ...
- Hadoop-1.2.1 升级到Hadoop-2.6.0 HA
Hadoop-1.2.1到Hadoop-2.6.0升级指南 作者 陈雪冰 修改日期 2015-04-24 版本 1.0 本文以hadoop-1.2.1升级到hadoop-2.6.0 Z ...
- 安装hadoop集群服务器(hadoop1.2.1)
摘要:hadoop,一个分布式系统基础架构,可以充分利用集群的威力进行高速运算和存储.本文主要介绍hadoop的安装与集群服务器的配置. 准备文件: ▪ VMware11.0.0 ▪ Cen ...
随机推荐
- ETL之增量抽取方式
1.触发器方式 触发器方式是普遍采取的一种增量抽取机制.该方式是根据抽取要求,在要被抽取的源表上建立插入.修改.删除3个触发器,每当源表中的数据发生变化,就被相应的触发器将变化的数据写入一个增量日志表 ...
- linux内核设计与实现学习笔记-模块
模块 1.概念: 如果让LINUX Kernel单独运行在一个保护区域,那么LINUX Kernel就成为了“单内核”. LINUX Kernel是组件模式的,所谓组件模式是指:LINUX K ...
- 使用Handler和Timer+Timertask实现简单的图片轮播
布局文件就只放了一个简单的ImageView,就不展示了. 下面是Activity package com.example.administrator.handlerthreadmessagedemo ...
- hdu 2034 人见人爱A-B
题目连接 http://acm.hdu.edu.cn/showproblem.php?pid=2034 人见人爱A-B Description 参加过上个月月赛的同学一定还记得其中的一个最简单的题目, ...
- Linux下cron的使用
cron是一个linux下的定时执行工具,可以在无需人工干预的情况下运行作业.由于Cron 是Linux的内置服务,但它不自动起来,可以用以下的方法启动.关闭这个服务: /sbin/service c ...
- 安装MSITVPN连接的时候弹出:需要(未知)上的文件'MSITVPN.bmp。
使用 msitvpn 连接microsoft 公司内网,在安装msitvpn的时候突然弹出一个对话框提示需要msitvpn.bmp 文件,找了很久都没找到解决问题方案. 最后只能猜测是不是和用户的权限 ...
- ggplot2 学习笔记 (持续更新.....)
1. 目前有四种主题 theme_gray(), theme_bw() , theme_minimal(),theme_classic() 2. X轴设置刻度 scale_x_continuous(l ...
- Android -- Webview自适应屏幕
第一种 WebSett ...
- cnblogs用户体验
在使用博客园的这段时间内,我们感觉有优点也有缺点,下面谈谈我们的看法: 1.是什么样的用户?有什么样的心理?对cnblogs的期望值是什么? 我们是学生用户,使用cnblogs主要是提交作业记录自己的 ...
- My97DatePicker控制开始时间和结束时间区间
开始时间: <input type="text" placeholder=" -请选择- " id="kssj" name=" ...