比特币源码分析--深入理解区块链16.Base58编码和解码
Base58是比特币中使用的一种独特编码方式,它主要用于比特币的钱包地址,在前面文章已经介绍过如何通过椭圆曲线方程算法,通过私钥来生成相应的公钥,钱包地址就是通过公钥计算得来,在后面的章节中将详细介绍如何通过公钥生成钱包地址。由于钱包地址在编码时使用了Base58编码方式,因此本章主要介绍Base58编码和解码的算法。
在比特币的区块浏览器中,我们常常可以看到类似下面这样的地址:
bc1qnsnqdhr2de0lq7fsca79uq5me38a7arwv5t9u2
my5fH6MBbGqSwmPWvphm94QTTHdSpCBte1
上面就是比特币中钱包地址的样式,它们是采用Base58编码后的字符串。Base58顾名思义最多只有58个字符。如我们常用的字符0~9,A~Z, a~z共10+26+26=62个。由于数字0和大写字母O,大写字母I和小写字母l相似,容易引起混淆,所以Base58字符内容其实就是在62个字符中排除了这4个字符后剩下的。它按下面的顺序排列,序号从0~57:
"123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz"
Base58编码符号表
Base58字符串按照顺序放在一个表格里如下所示:
|
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
|||
|
0 |
1 |
16 |
H |
32 |
Z |
48 |
q |
|||
|
1 |
2 |
17 |
J |
33 |
a |
49 |
r |
|||
|
2 |
3 |
18 |
K |
34 |
b |
50 |
s |
|||
|
3 |
4 |
19 |
L |
35 |
c |
51 |
t |
|||
|
4 |
5 |
20 |
M |
36 |
d |
52 |
u |
|||
|
5 |
6 |
21 |
N |
37 |
e |
53 |
v |
|||
|
6 |
7 |
22 |
P |
38 |
f |
54 |
w |
|||
|
7 |
8 |
23 |
Q |
39 |
g |
55 |
x |
|||
|
8 |
9 |
24 |
R |
40 |
h |
56 |
y |
|||
|
9 |
A |
25 |
S |
41 |
i |
57 |
z |
|||
|
10 |
B |
26 |
T |
42 |
j |
|||||
|
11 |
C |
27 |
U |
43 |
k |
|||||
|
12 |
D |
28 |
V |
44 |
m |
|||||
|
13 |
E |
29 |
W |
45 |
n |
|||||
|
14 |
F |
30 |
X |
46 |
o |
|||||
|
15 |
G |
31 |
Y |
47 |
p |
编码从0~57共58个编码。因此要将数据进行Base58编码,首先应该计算数据的编码,然后根据编码查找对应的字符,最后得出的字符串就是Base58编码的结果。
编码从0~57共58个编码。因此要将数据进行Base58编码,首先应该计算数据的编码,然后根据编码查找对应的字符,最后得出的字符串就是Base58编码的结果。
设计Base58主要的目的
- 避免混淆。
- 在某些字体下,数字0和字母大写O,以及字母大写I和字母小写l会非常相似。
- 不使用"+"和"/"的原因是非字母或数字的字符串作为账号较难被接受。
- 没有标点符号,通常不会被从中间分行。
- 大部分的软件支持双击选择整个字符串。
避免混淆,易于阅读和方便计算机使用是其设计的主要目的。因此在需要使用字符串标记身份或唯一识别码的应用场合,使用base58不失为一个好的选择。
Base58编码算法
计算机中所有数据均可以使用字节(byte)来表示,一个字节长度为8个二进制位,因此计算机中最基本的字节码最多个,编码从0~255,常用的ASCII表就列出了编码对应的字符。因此一个ASCII字节可用8位二制来表示可写成:
,而Base58最多可用
位表示,因此经过Base58编码后的长度是原始数据长度的
倍。
Base58编码的基本思想将常用的字节码(256进制)转换成Base58,相当于将256进制转换成58进制。但不能直接将256进制转换为58进制,中间必须通过10进制中转,相当于
256进制转10进制,10进制转58进制。
它们的转换算法同样可以按照二进制到10进制转换思想来进行。
我们先重温一下十进制与二进制的转换
二进制转换为十进制:
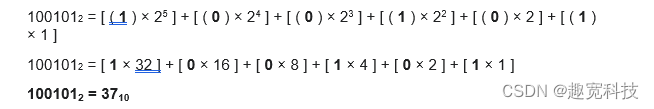
依照该规则,将256进制转换为10进制,是以256作为底数进行的。
十进制转换为二进制:
整数部分,把十进制转成二进制一直分解至商数为0。读余数从下读到上,即是二进制位的整数部分数字。
将59.25(10) 转成二进制:
整数部分:
59 ÷ 2 = 29 ... 1
29 ÷ 2 = 14 ... 1
14 ÷ 2 = 7 ... 0
7 ÷ 2 = 3 ... 1
3 ÷ 2 = 1 ... 1
1 ÷ 2 = 0 ... 1
小数部分,则用其乘2,取其整数部分的结果,再用计算后的小数部分依此重复计算,算到小数部分全为0为止,之后读所有计算后整数部分的数字,从上读到下。
小数部分:
0.25 × 2 = 0.5
0.50 × 2 = 1.0
所以:
而十进制转换为58进制,被除数就是58。
base58的编码过程是:
- 将要转换的数据转换为字节数组
- 计算前置字节码是0的个数,因为0没必要参与转换,其结果是0。
- 将256进制转换为10进制
- 将10进制转换为58进制。
- 得到一个58进制的数组,将第二步0的个数添加到该数组末尾。n个0就添加n个0到数组末尾。
- 反转整个数组。
- 查表,将base58编码转换成字符。
这里的第3步如果转换的字节数组很长,那么以256为底数的指数将会非常庞大,需要使用大数,但实际上可以优化算法,没必要一次性将整个原始数组全部转换为10进制后才转换为58进制,可采取逐个转换为58机制的策略来进行,这样可以避免使用大整数,从而提高运算效率。
我们将“Abc”转换为base58为例说明运算过程:
|
字符 |
ASCII码 |
||
|
A |
65 |
|
4259840 |
|
b |
98 |
|
25088 |
|
c |
99 |
|
99 |
|
4285027 |
|
计算 |
商 |
余数 |
|
|
73879 |
45 |
|
|
1273 |
45 |
|
|
21 |
55 |
|
|
0 |
21 |
所以最后结果是21, 55, 45, 45,查表得base58编码:Nxnn
Bitcoin中算法是这样的:
std::string EncodeBase58(Span<const unsigned char> input)
{// Skip & count leading zeroes.int zeroes = 0;int length = 0;while (input.size() > 0 && input[0] == 0) {input = input.subspan(1);zeroes++;}// Allocate enough space in big-endian base58 representation.int size = input.size() * 138 / 100 + 1; // log(256) / log(58), rounded up.std::vector<unsigned char> b58(size);// Process the bytes.while (input.size() > 0) {int carry = input[0];int i = 0;// Apply "b58 = b58 * 256 + ch".for (std::vector<unsigned char>::reverse_iterator it = b58.rbegin(); (carry != 0 || i < length) && (it != b58.rend()); it++, i++) {carry += 256 * (*it);*it = carry % 58;carry /= 58;}assert(carry == 0);length = i;input = input.subspan(1);}// Skip leading zeroes in base58 result.std::vector<unsigned char>::iterator it = b58.begin() + (size - length);while (it != b58.end() && *it == 0)it++;// Translate the result into a string.std::string str;str.reserve(zeroes + (b58.end() - it));str.assign(zeroes, '1');while (it != b58.end())str += pszBase58[*(it++)];return str;
}
在上面得代码中,我们可以看到给base58容器分配的大小是138/100+1,这个数字也是base58编码后是原的大小的1.37倍左右。另外在转换为10进制的过程中,并没有一次性计算所有的字节的和,而是采取边计算10进制,边计算58进制的过程。
Base58解码算法
Base58解码是编码的逆运算过程:
- 首先获得base58字符对应的编码
- 通过编码计算其10进制
- 将10进制转换为256进制。
在根据base58字符串获得其编码的过程中,如果使用查表遍历算法话,时间复杂度最高是,可以不通过查表来完成:建立一个大小是256数组,里面对应的是base58字符串的编码,数组序号就是字符的ASCII编码,比如z的ASCII码是112,那么数组序号112的内容就是z的base编码57。这样可以每个base58字符运算一次就能找到其编码。
继续上面的例子,将“Nxnn”解码,过程是:
|
字符 |
Base58 |
||
|
N |
21 |
|
4097352 |
|
x |
55 |
|
185020 |
|
n |
45 |
|
2610 |
|
n |
45 |
|
45 |
|
4285027 |
|
计算 |
商 |
余数 |
|
|
16738 |
99 |
|
|
65 |
98 |
|
|
0 |
65 |
其256进制的结果是65, 98, 99, 查ASCII表得:Abc。
比特币源码分析--深入理解区块链16.Base58编码和解码的更多相关文章
- 比特币源码分析--C++11和boost库的应用
比特币源码分析--C++11和boost库的应用 我们先停下探索比特币源码的步伐,来分析一下C++11和boost库在比特币源码中的应用.比特币是一个纯C++编写的项目,用到了C++11和bo ...
- Android源码分析-全面理解Context
前言 Context在android中的作用不言而喻,当我们访问当前应用的资源,启动一个新的activity的时候都需要提供Context,而这个Context到底是什么呢,这个问题好像很好回答又好像 ...
- ReentrantReadWriteLock源码分析及理解
本文结构 读写锁简介:介绍读写锁.读写锁的特性以及类定义信息 公平策略及Sync同步器:介绍读写锁提供的公平策略以及同步器源码分析 读锁:介绍读锁的一些常用操作和读锁的加锁.解锁的源码分析 写锁:介绍 ...
- ReentrantLock源码分析与理解
在上面一篇分析ThreadExecutedPool的文章中我们看到线程池实现源码中大量使用了ReentrantLock锁,那么ReentrantLock锁的优势是什么?它又是怎么实现的呢? Reent ...
- Java I/O系列(二)ByteArrayInputStream与ByteArrayOutputStream源码分析及理解
1. ByteArrayInputStream 定义 继承了InputStream,数据源是内置的byte数组buf,那read ()方法的使命(读取一个个字节出来),在ByteArrayInputS ...
- Java I/O系列(一)InputStream与OutputStream源码分析及理解
1. InputStream 定义 字节输入流,是一个抽象类,核心是通过read()方法,从数据源中读取一个个字节出来,另有skip,mark功能 核心源码理解 源码: public abstract ...
- cowboy源码分析(一)
前段时间导读了ranch的源码,具体见ranch 源码分析(一), 现在整理了下ranch框架下经典应用cowboy. 源码地方:https://github.com/ninenines/cowboy ...
- 《深入理解Spark:核心思想与源码分析》(第2章)
<深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 <深入理解Spark:核心思想与源码分析> ...
- Spring AOP 源码分析 - 拦截器链的执行过程
1.简介 本篇文章是 AOP 源码分析系列文章的最后一篇文章,在前面的两篇文章中,我分别介绍了 Spring AOP 是如何为目标 bean 筛选合适的通知器,以及如何创建代理对象的过程.现在我们的得 ...
- 深入理解python虚拟机:调试器实现原理与源码分析
深入理解python虚拟机:调试器实现原理与源码分析 调试器是一个编程语言非常重要的部分,调试器是一种用于诊断和修复代码错误(或称为 bug)的工具,它允许开发者在程序执行时逐步查看和分析代码的状态和 ...
随机推荐
- slab分配器正式被弃用,slub成为分配器唯一选择
在使用slab分配器进行内存分配时,可能会出现以下缺点: 内存碎片化.由于slab分配器需要将内存分成大小相同的块,如果分配不均衡或者对象大小不同,就容易导致内存碎片化. 性能下降.Slab分配器将内 ...
- 对于ChannelNet的一点理解
主要是为了个人理解,做个笔记 1.Pytorch代码 2.论文出处 3.详细介绍 这篇论文在2018年发出来,而ShuffleNet是从2017年由旷视发出来.起初了解shufflenet的提出,主要 ...
- 数据库周刊60丨3月国产数据库排行榜出炉;日本银行数据迁移失败致使业务宕机;阿里云RDS PG13发布;亚健康Oracle数据库故障定位;Redis最佳实践;MySQL查询优化……
热门资讯 1.2021年3月国产数据库排行榜:雏凤声清阿里三连 绝代双骄华为合璧 [摘要]2021年3月国产数据库流行度排行榜已出炉,在本月排行的前十名中,TiDB 仍然以领先第二名135分 的优势稳 ...
- .Net 反射和特性
学习:.net 反射简单介绍 - WebEnh - 博客园 (cnblogs.com) 反射就是通过反射程序集从而获取相关信息 十月的韩流 使用了特性就必定会使用反射 var res = obj.Ge ...
- KubeSphere 在互联网电商行业的应用实践
来自社区用户(SRE运维手记)投稿 背景 在云原生的时代背景下,Kubernetes 已经成为了主流选择.然而,Kubernetes 的原生操作复杂性和学习曲线较高,往往让很多团队在使用和管理上遇到挑 ...
- 云原生周刊:ingress2gateway 发布 | 2023.10.30
开源项目推荐 m9sweeper m9sweeper 是一个免费且简单的 Kubernetes 安全平台.它将行业标准的开源实用程序集成到一站式 Kubernetes 安全工具中,该工具可以帮助大多数 ...
- KubeSphere 边缘节点 IP 冲突的分析和解决思路分享
在上一篇监控问题排查的文章中,笔者分析了 KubeSphere 3.1.0 集成 KubeEdge 中的边缘监控原理和问题排查思路,在介绍 EdgeWatcher 组件时提到了"边缘节点的内 ...
- 手把手教会你使用Markdown【从入门到精通一篇就够了】
目录 一.Markdown是什么 二.Markdown优点 三.Markdown的基本语法 3.1 标题 3.2 字体 3.3 换行 3.4 引用 3.5 链接 3.6 图片 3.7 列表 3.8 分 ...
- QT creator中cmake管理项目,如何引入外部库(引入Eigen库为例)
在Eigen的官网下载压缩包[点我进入] 解压到当前项目的根目录(当然你也可以自己选择目录) 在当前项目的CMakeLists.txt任意位置加入这句话include_directories(${CM ...
- ansible开局配置-openEuler
ansible干啥用的就不多介绍了,这篇文章主要在说ansible的安装.开局配置.免密登录. ansible安装 查看系统版本 cat /etc/openEuler-latest 输出内容如下: o ...