SQL优化——深分页&排序
问题背景
在开发 Web 应用或处理数据库查询时,分页是一项常见需求。然而,当面对深度分页(即页码较大,偏移量较高的分页情况)时,性能问题往往接踵而至。比如对一些需要拉特定的页面查询、范围导出、范围计算等业务需求,都会涉及大量的深分页查询的SQL,不当的SQL会导致执行超时,页面响应显著上升等问题。本文重点讨论Mysql下以Innodb为存储引擎时,深分页造成性能恶化的根因以及一般解决方案。
为什么Limit在offset很大时性能会变差?
假设当前存在一张item表,单表有千万级数据,其核心字段有id, item_code, item_name, type, sub_type, biz_type, status等,并且在
type, sub_type, biz_type三个字段上存在索引, id上存在默认的主键索引当执行SQL
-- SQL1 -> 3ms; 如果把候选列设置为* -> 4ms
Select id, item_code, type, sub_type
From item
where type = 'normal'
order by id ASC
limit 0, 20;
-- SQL2 2300ms; 如果把候选列设置为* -> 3700ms
Select id, item_code, type, sub_type
From item
where type = 'normal'
order by id ASC
limit 1000000, 20;
-- SQL3 500ms; 只查找主键和覆盖索引上的东西
Select id, type
From item
where type = 'normal'
order by id ASC
limit 1000000, 20;
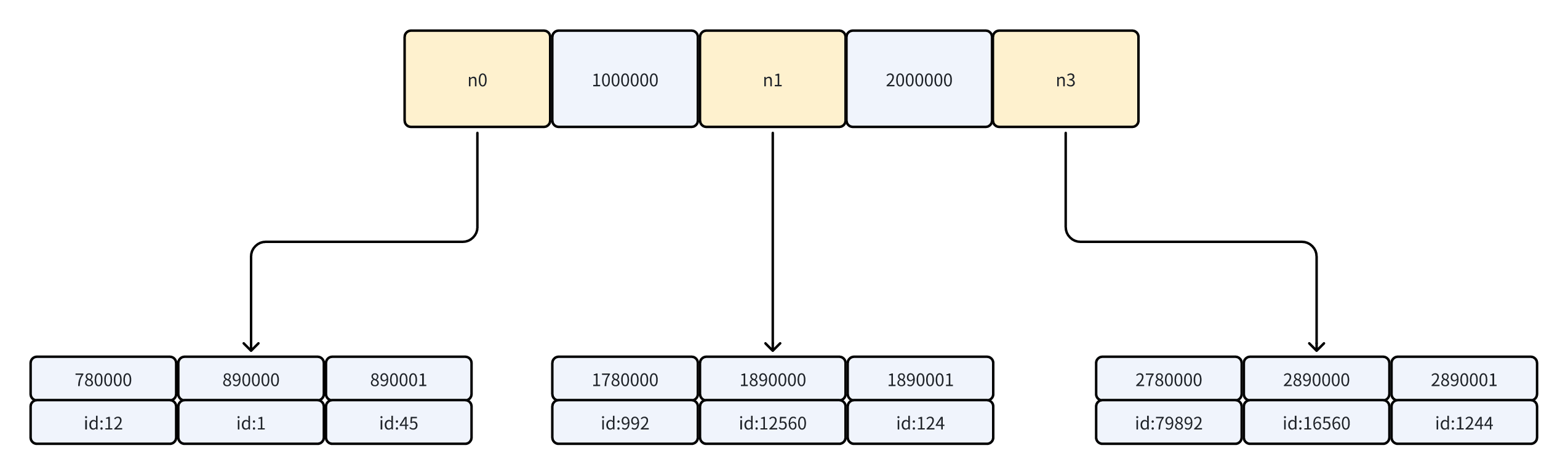
不必要的回表
我们都知道innodb采用B+树作为索引(如上图),在普通索引的条件下,非叶子阶段上存储了索引列值的比较锚点,叶子节点上存储索引列值到主键id的pair。在普通索引上查询到叶子节点并获取对应的主键后,若SQL中需要获取索引列以外的值,则需要到主键索引上,利用先前定位到的主键进行回表操作,获取完整的数据。
SQL2和SQL3的对比正好是是否需要触发回表的对比,可以发现执行时间差了4倍以上。通过执行两者的执行计划,也可以发现,在SQL3的extra信息中,会有Using Index的信息,这代表命中了覆盖索引,不需要额外进行回表。
同时对比SQL1和SQL2,两者只有在offset的部分存在区别,所以当offset变大时,会导致回表后需要扫描记录数显著增加(这也说明limit的执行逻辑是在回表之后,但是where条件执行是会在索引或者回表时就应用的,那么有办法把limit的操作前置到where中呢?)
延迟关联
-- 500ms
Select id, item_code, type, sub_type
From item
INNER JOIN (
Select id
From item
where type = 'normal'
order by id ASC
limit 1000000, 20
) t1 using (id);
子查询
-- 500ms
Select id, item_code, type, sub_type
From item
where id >= (
Select id
From item
where type = 'normal'
order by id ASC
limit 1000000, 1
) limit 20;
两种方式都非常类似,都是通过避免回表,拿到数据的主键id,再通过join 或者id直接比较的方式,跳过了无意义的回表扫描。(相当于通过人为的方式将limit操作前置到回表之前了)
禁止跳页
还有一种简单的方式就是,需要客户端传入上一次调用的last_id,然后在where条件里加上last_id的条件即可。但是这种做法使得客户端无法进行跳页访问了,只能连续的进行上一页或者下一页操作。(批处理或者导出的场景还是非常适用的)
关于OrderBy的影响
上述的SQL当order by 条件发生变化时,SQL的执行效率也会发生巨大的变化,甚至比limit本身影响更大。因为order By会决定mysql优化器的索引选择,以及会触发FileSort(即在内存中开辟专属空间进行排序)。
-- SQL5 9000 ms
Select id, item_code, type, sub_type
From item
where type = 'normal'
order by item_code ASC
-- 此处基于item_code排序
limit 0, 20;
全字段排序
可以看到SQL5仅仅是换了一个排序条件,并且查询计划显示命中的索引仍与先前一致,但是执行时间却来到了夸张的9000ms,相比SQL1,多了近20倍,为什么会产生这样的结果呢?可以先了解一下OrderBy的基本执行逻辑:
初始化sort_buffer, 放入字段id, item_code, type, sub_type
从type索引中找到符合type = 'normal'的记录,获取id
根据id,从主键索引中获取id, item_code, type, sub_type,放入sort_buffer
重复2~3,直到没有符合type = 'normal'的记录
sort_buffer根据item_code进行排序
排序结果取前20行返回
当排序的数据过大时,会启用外部排序(临时文件归并排序)
- 这里可能会有些疑问,为什么要把不排序的字段也放到sort_buffer中?是因为排完序后,可以直接从排序的结果集中取出完整的Select所需要的字段。
部分字段排序
- 那如果是Select *呢?并且表的字段非常多,是否会过度浪费sort_buffer的资源,导致触发外部排序呢?是的,但是Mysql中存在一个配置,max_length_for_sort_data,当所放字段大于这个值时,就不会把所有select的字段放入sort_buffer,而是选择排完序之后,再次进行回表,得到完整的数据:
初始化sort_buffer, 放入字段id, item_code
从type索引中找到符合type = 'normal'的记录,获取id
根据id,从主键索引中获取id, item_code,放入sort_buffer
重复2~3,直到没有符合type = 'normal'的记录
sort_buffer根据item_code进行排序
排序结果取前20行, 得到对应的id,从聚簇索引中回表,得到完整的数据
通常来说,Mysql规格够大时,不建议使用这种排序方式,因为会额外回表。
覆盖索引跳过排序
如果此时存在type, item_code的覆盖索引,则无需额外排序,即可返回结果集,执行效率是最高的。
但是如果type的条件变为in呢?
-- SQL5 9000 ms
Select id, item_code, type, sub_type
From item
where type in ('normal', 'abnormal')
order by item_code ASC
-- 此处基于item_code排序
limit 0, 20;
答案是,需要排序。因此这种情况下推荐在业务代码中,将其拆为两句 type = 'normal' 和 type = 'abnormal'的SQL,然后业务代码中自行实现归并排序即可。
参考文献
MySQL实战45讲
从根儿上理解Mysql
SQL优化——深分页&排序的更多相关文章
- MySQL 千万数据库深分页查询优化,拒绝线上故障!
文章首发在公众号(龙台的技术笔记),之后同步到博客园和个人网站:xiaomage.info 优化项目代码过程中发现一个千万级数据深分页问题,缘由是这样的 库里有一张耗材 MCS_PROD 表,通过同步 ...
- 系统优化怎么做-SQL优化
大家好,这里是「聊聊系统优化 」,并在下列地址同步更新 博客园:http://www.cnblogs.com/changsong/ 知乎专栏:https://zhuanlan.zhihu.com/yo ...
- 没内鬼,来点干货!SQL优化和诊断
SQL优化与诊断 Explain诊断 Explain各参数的含义如下: 列名 说明 id 执行编号,标识select所属的行.如果在语句中没有子查询或关联查询,只有唯一的select,每行都将显示1. ...
- SQL优化案例—— RowNumber分页
将业务语句翻译成SQL语句不仅是一门技术,还是一门艺术. 下面拿我们程序开发工程师最常用的ROW_NUMBER()分页作为一个典型案例来说明. 先来看看我们最常见的分页的样子: WITH CTE AS ...
- C#拼接SQL语句,SQL Server 2005+,多行多列大数据量情况下,使用ROW_NUMBER实现的高效分页排序
/// <summary>/// 单表(视图)获取分页SQL语句/// </summary>/// <param name="tableName"&g ...
- C# SQL优化 及 Linq 分页
每次写博客,第一句话都是这样的:程序员很苦逼,除了会写程序,还得会写博客!当然,希望将来的一天,某位老板看到此博客,给你的程序员职工加点薪资吧!因为程序员的世界除了苦逼就是沉默.我眼中的程序员大多都不 ...
- SQL通用优化方案(where优化、索引优化、分页优化、事务优化、临时表优化)
SQL通用优化方案:1. 使用参数化查询:防止SQL注入,预编译SQL命令提高效率2. 去掉不必要的查询和搜索字段:其实在项目的实际应用中,很多查询条件是可有可无的,能从源头上避免的多余功能尽量砍掉, ...
- 正确使用索引(sql优化),limit分页优化,执行计划,慢日志查询
查看表相关命令 - 查看表结构 desc 表名- 查看生成表的SQL show create table 表名- 查看索引 show index from 表名 使用索引和不使用索引 由 ...
- 查询效率提升10倍!3种优化方案,帮你解决MySQL深分页问题
开发经常遇到分页查询的需求,但是当翻页过多的时候,就会产生深分页,导致查询效率急剧下降. 有没有什么办法,能解决深分页的问题呢? 本文总结了三种优化方案,查询效率直接提升10倍,一起学习一下. 1. ...
- 浅谈SQL优化入门:3、利用索引
0.写在前面的话 关于索引的内容本来是想写的,大概收集了下资料,发现并没有想象中的简单,又不想总结了,纠结了一下,决定就大概写点浅显的,好吧,就是懒,先挖个浅坑,以后再挖深一点.最基本的使用很简单,直 ...
随机推荐
- 顺序表(python)
文章目录 1.创建顺序表 2.按址查找元素的位置 3.增加元素 3.1在头部增加元素 3.2在尾部增加元素 3.3在中间任意位置增加元素 4.删除元素 4.1删除第一个元素 4.2删除指定的元素 5. ...
- att&ck学习笔记2
一.环境搭建 靶场下载地址:http://vulnstack.qiyuanxuetang.net/vuln/detail/3/ DC IP:10.10.10.10OS:Windows 2012应用:A ...
- Linux基础-学会使用命令帮助
概述 使用 whatis 使用 man 查看命令程序路径 which 总结 参考资料 概述 Linux 命令及其参数繁多,大多数人都是无法记住全部功能和具体参数意思的.在 linux 终端,面对命令不 ...
- 【总结】线性dp的几种重要模型
当前点定义 \(f[i]\) :走到第 \(i\) 个点的方案数 / 最值. \(f[i][j]\) :走到第 \(i\) 个点,选了 \(j\) 个的答案. 依据题目的限制个数可以继续添加维数,也可 ...
- C++进阶知识汇总
知识来源:https://www.imooc.com/learn/1305 二进制在计算机中的意义: 计算机如何存负整数: 原码:符号位变为1 反码:除符号位其余取反 补码:=反码+1 是-7的表示方 ...
- 第三篇:低功耗模组Air724UG硬件设计手册
今天我们分享最后一篇. 3.20 省电功能 根据系统需求,有两种方式可以使模块进入到低功耗的状态.对于AT版本使用"AT+CFUN"命令可以使模块 进入最少功能状态. 具体的功 ...
- 总结:OI题目中常见的三种距离
设 \(A(x_1, y_1), B(x_2, y_2)\). 欧几里得距离 \[|AB| = \sqrt{(x_2 - x_1)^2 + (y_2 - y_1)^2} \] 一般模型:在一个坐标系上 ...
- apache做负载均衡器 配置
将Apache作为LoadBalance前置机分别有三种不同的部署方式,分别是: 1 )轮询均衡策略的配置 进入Apache的conf目录,打开httpd.conf文件,在文件的末尾加入: Proxy ...
- Java框架 —— MyBatis
MyBatis 简介 持久层框架,半自动映射,支持自定义SQL.高级映射.存储过程,免除了JDBC代码.参数设置.获取结果集的工 作,可以通过XML或注解方式配置.映射接口,以及实体类在数据库中的记 ...
- Reviewbot 开源 | 这些写 Go 代码的小技巧,你都知道吗?
Reviewbot 是七牛云开源的一个项目,旨在提供一个自托管的代码审查服务, 方便做 code review/静态检查, 以及自定义工程规范的落地. 自从上了 Reviewbot 之后,我发现有些 ...