【实战】基于 Tauri 和 Rust 实现基于无头浏览器的高可用网页抓取
一、背景
在 Saga Reader 的早期版本中,存在对网页内容抓取成功率不高的问题。主要原因是先前采用的方案为后台进程通过 reqwest 直接发起 GET 请求获取网站 HTML 的方案,虽然仿真了Header内容,但仍然会被基于运行时的反爬机制(如 Browser指纹交叉验证、运行时行为识别、动态渲染等)所屏蔽。这导致我们无法稳定、可靠地获取内容,影响应用的可用性。
为了解决这一痛点,我们优化了更新机制。利用 Tauri 提供的 WebView(在此场景下作为无头浏览器使用)来模拟真实用户访问,并注入定制化的 JavaScript 脚本来精确抓取所需的 DOM 内容。这种方法能够有效对抗大多数常见的反爬虫策略,显著提升抓取成功率。
同时,我们也希望应用能够在系统启动时自动在后台执行 Feed 更新任务,而无需立即显示主窗口,从而提供更流畅的“静默更新”体验。
关于Saga Reader
基于Tauri开发的开源AI驱动的智库式阅读器(前端部分使用Web框架),能根据用户指定的主题和偏好关键词自动从互联网上检索信息。它使用云端或本地大型模型进行总结和提供指导,并包括一个AI驱动的互动阅读伴读功能,你可以与AI讨论和交换阅读内容的想法。
这个项目我5月刚放到Github上(Github - Saga Reader),欢迎大家关注分享。码农开源不易,各位好人路过请给个小星星Star。
核心技术栈:Rust + Tauri(跨平台)+ Svelte(前端)+ LLM(大语言模型集成),支持本地 / 云端双模式
关键词:端智能,边缘大模型;Tauri 2.0;桌面端安装包 < 5MB,内存占用 < 20MB。
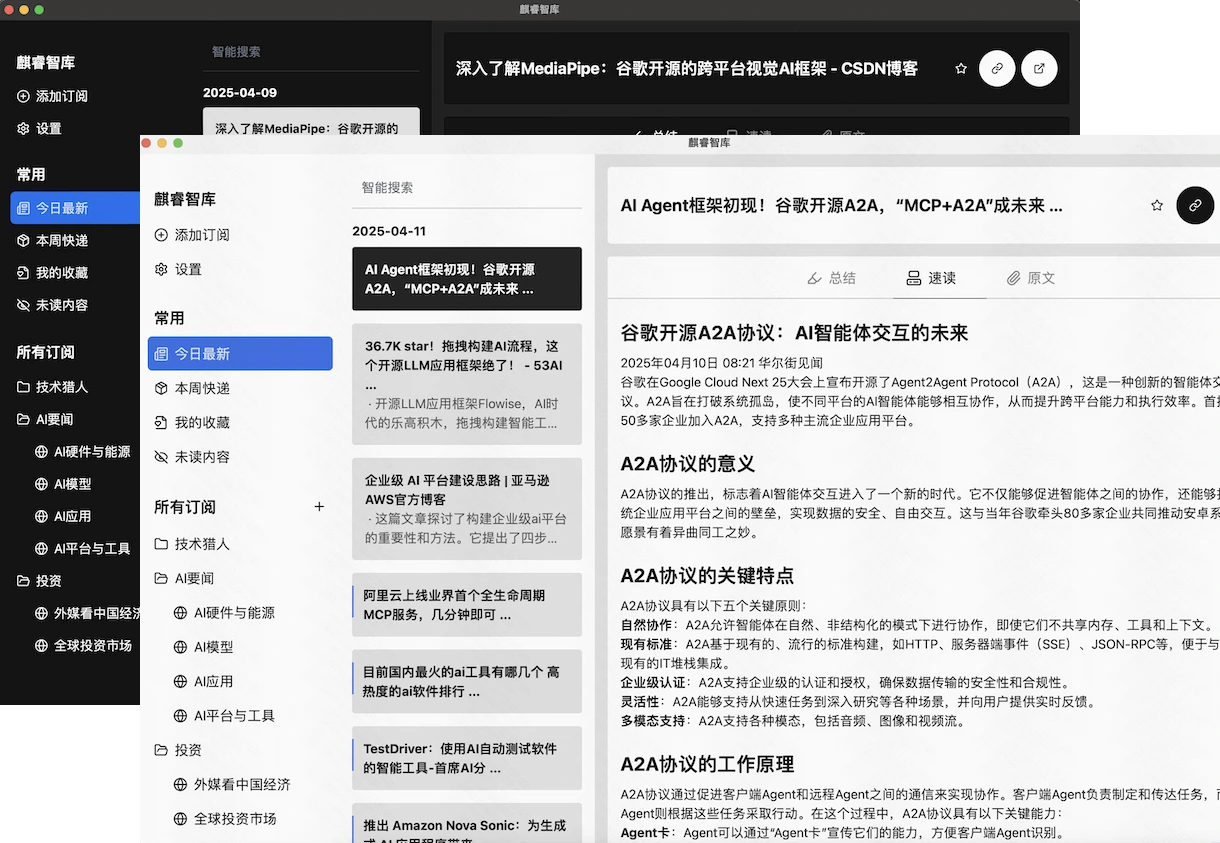
运行截图
二、架构概览
新方案的整体架构围绕 Tauri 应用的核心组件构建,旨在实现高效、可靠的后台 Feed 更新和内容抓取。主要组件及其交互如下:
主进程 (Rust Backend):
- 应用生命周期管理: 控制应用的启动、后台运行、窗口显隐及退出。
- Feed 更新调度器 (
feeds_update.rs): 核心的后台任务模块,负责定时唤醒、管理 Feed 更新队列、并发控制。 - 无头 WebView 管理: 为每个 Feed 源创建和管理一个隐藏的 WebView 实例。
- JavaScript 注入与通信: 通过 WebView API 向加载的页面注入抓取脚本,并接收脚本返回的数据。
- 文件锁 (
feeds_schedule_update.lock):确保同一时间只有一个应用实例在执行 Feed 更新调度。 - 状态管理与前端接口: 维护后台任务状态,并通过 Tauri 的
invoke和事件机制与前端 Svelte UI 通信。 - 配置与环境 (
env.rs,tauri.conf.json): 读取配置,判断运行模式(例如,是否后台启动)。
Tauri WebView (Headless Instance):
- 网页加载: 加载目标 Feed 源的 URL。
- JavaScript 执行环境: 执行注入的抓取脚本,模拟用户交互(如果需要),解析 DOM。
抓取脚本 (JavaScript):
- DOM 解析: 负责在 WebView 加载的页面中定位和提取所需的 Feed 内容(如文章列表、标题、链接、日期、正文摘要等)。
- 数据格式化: 将提取的数据整理成结构化格式,返回给 Tauri 主进程。
Svelte 前端 UI (
tasks.svelte.ts, etc.):- 用户界面: 展示 Feed 内容、更新状态、提供用户操作入口。
- 与后端通信: 通过 Tauri API 调用后端命令、监听后端事件,实现数据同步和交互。
数据存储 (Implicit):
- 抓取到的 Feed 数据最终会被存储(例如,在本地数据库或文件中),供用户阅读。
交互流程简介:应用启动时,主进程根据配置判断是否进入后台更新模式。Feed 更新调度器定时触发,为每个 Feed 创建无头 WebView 实例,加载对应网页,注入抓取脚本。脚本执行后将数据返回主进程,主进程处理数据并更新前端 UI(如果可见)或存储数据。
三、核心技术实现与亮点
1. 应用主进程的后台化与主窗口延迟显示
新版本不再依赖单独的守护进程,而是让应用主进程本身支持后台运行。这主要通过以下方式实现:
- 配置文件修改:在 中,将主窗口的
visible属性设置为false:"windows": [
{
"label": "main",
"visible": false, // 默认不显示主窗口
...
}
]
- 启动逻辑调整:在 的
app_setup和run_event_loop函数中处理应用启动和事件循环。app_setup负责初始化,而run_event_loop中的RunEvent::Reopen事件处理允许用户在应用已后台运行时,通过点击 Dock 图标或其他方式重新打开主窗口。is_daemon_mode函数(位于 )用于判断当前是否应以“守护进程”模式(即后台模式)启动,这可能基于命令行参数或特定环境变量。- 在 的
run函数中,会根据is_daemon_mode的结果来决定是否立即显示窗口或执行其他后台初始化逻辑。
代码分析:
修改 tauri.conf.json 是最直接的方式来控制窗口的初始可见性。Rust 代码层面,app_setup 钩子在 Tauri 应用初始化时运行,适合执行一些全局设置。run_event_loop 则处理应用运行期间的各种事件,特别是 RunEvent::Reopen,它使得即使用户关闭了所有窗口(在 macOS 上应用通常不会退出),或者应用以不可见模式启动,也能响应用户的重新打开请求,显示主窗口。
2. 基于 Tauri 无头 WebView 的智能抓取
这是解决反爬虫问题的关键。我们利用 Tauri 的 WebView 来加载和执行 JavaScript,模拟真实用户环境。
- 创建隐藏 WebView:虽然 Tauri 的底层Tao和Wry并没有实现
headless机制,但我们可以在应用层创建一个程序化控制的、不实际显示给用户的 WebView 窗口。这个窗口加载目标网页。 - JavaScript 注入与执行:一旦页面加载完成(或达到某个特定状态,如 DOMContentLoaded),通过 Tauri 的
window.eval()或webview.execute_script()方法注入自定义的 JavaScript 代码。这个脚本被设计用来:- 定位元素:使用
document.querySelector,document.querySelectorAll等标准 DOM API 找到包含 Feed 条目、标题、链接、日期、摘要等的 HTML 元素。 - 提取数据:获取这些元素的
innerText,href等属性。 - 处理动态内容:如果内容是动态加载的,脚本可能需要等待特定条件或模拟某些用户操作(如点击“加载更多”)来获取完整数据。
- 返回结果:将提取并结构化的数据通过
Promise或 Tauri 的 IPC 机制返回给 Rust 后端。
- 定位元素:使用
代码分析:
核心逻辑位于 "feeds_update.rs":
// 伪代码,示意 feeds_update.rs 中的逻辑
async fn fetch_feed_content(app_handle: &AppHandle, url: &str, script: &str) -> Result<Vec<Article>> {
// 1. 创建一个新的、可能不可见的 WebView 窗口
let webview_window = tauri::WindowBuilder::new(app_handle, "headless_feed_fetcher", tauri::WindowUrl::External(url.parse()?))
.visible(false) // 确保窗口不可见
.build()?;
// 2. 等待页面加载完成 (这里可能需要更复杂的逻辑,如监听事件)
// tokio::time::sleep(Duration::from_secs(5)).await; // 简化的等待
// 3. 注入并执行抓取脚本
let result_json = webview_window.eval(script).await?;
// 4. 解析脚本返回的 JSON 数据
let articles: Vec<Article> = serde_json::from_str(&result_json)?;
// 5. 关闭 WebView 窗口
webview_window.close()?;
Ok(articles)
}
这种方式的优势在于,抓取是在一个完整的浏览器环境中进行的,能够处理 JavaScript 渲染的页面,执行网站自身的脚本,从而大大降低被识别为爬虫的概率。
3. 高效的 Feed 更新调度
Feed 更新调度确保了所有 Feed 源能够定期、高效且不冲突地进行更新。其流程大致如下:
- 启动调度器:应用启动时(如果不是已有实例在运行调度),在 中初始化一个 Tokio 定时任务 (
tokio::time::interval),例如每隔一段时间(如 30 分钟)触发一次。 - 获取 Feed 列表:调度器触发时,从数据源(如数据库)获取所有需要更新的 Feed 源列表。
- 并发更新:为了提高效率,可以使用
tokio::spawn为每个 Feed 源(或分批)启动一个异步任务来进行抓取。可以使用Semaphore或类似机制来限制并发数量,防止一次性创建过多 WebView 实例导致资源耗尽。 - 单个 Feed 更新过程:
- 调用上述“基于 Tauri 无头 WebView 的智能抓取”逻辑。
- 获取抓取结果(文章列表或错误信息)。
- 处理结果:将新文章存入数据库,更新 Feed 源的最后更新时间等状态。
- 记录日志,处理错误(如重试机制)。
- 状态通知:通过 Tauri 事件系统或更新 Svelte Store (
app/src/routes/main/stores/tasks.svelte.ts),将更新进度、成功/失败状态通知给前端 UI(如果可见)。 - 循环等待:完成一轮更新后,调度器等待下一个
interval触发。
代码分析:
在 中,FeedsUpdate 结构体和其 run 或类似方法是核心。run 方法内部会包含一个循环,由 tokio::time::interval(duration).tick().await驱动。关键的数据结构和模式:
Arc<Mutex<State>>: 用于在异步任务间安全共享可变状态(如配置、数据库连接池)。tokio::spawn: 用于并发执行每个 Feed 的抓取任务。JoinHandle: 用于管理并发任务,可以等待其完成或处理其结果。- 错误处理: 每个抓取任务都需要有健壮的错误处理,例如使用
Result<T, E>,并记录详细错误信息。
// 伪代码,示意 feeds_update.rs 中的调度逻辑
pub struct FeedsUpdater {
app_handle: AppHandle,
// ...其他依赖,如数据库连接池
}
impl FeedsUpdater {
pub async fn run_schedule(&self, interval_duration: Duration) {
let mut interval = tokio::time::interval(interval_duration);
loop {
interval.tick().await;
log::info!("Feed update cycle started.");
let feeds_to_update = self.get_feeds_from_db().await;
let mut tasks = vec![];
for feed in feeds_to_update {
let app_handle_clone = self.app_handle.clone();
// 假设有 get_fetch_script_for_feed(&feed) 方法
let fetch_script = self.get_fetch_script_for_feed(&feed);
tasks.push(tokio::spawn(async move {
match fetch_feed_content(&app_handle_clone, &feed.url, &fetch_script).await {
Ok(articles) => {
// 处理文章,存入数据库
log::info!("Successfully fetched {} articles for {}", articles.len(), feed.name);
}
Err(e) => {
log::error!("Failed to fetch feed {}: {}", feed.name, e);
}
}
}));
}
for task in tasks {
let _ = task.await; // 等待所有抓取任务完成
}
log::info!("Feed update cycle finished.");
}
}
}
4. 状态共享与前端交互
后台任务的状态(如“正在更新 Feed X”、“更新完成”、“错误:无法连接到 Y”)需要反馈给用户。这通过以下方式实现:
- Svelte Stores (): Rust 后端可以通过 Tauri 的
app_handle.emit_all("event-name", payload)发送事件,Svelte 前端监听这些事件并更新对应的 Store。Store 的变化会自动触发 UI 的重新渲染。// tasks.svelte.ts
import { writable } from 'svelte/store';
import { listen } from '@tauri-apps/api/event'; export const updateTasks = writable([]); // [{ id: 'feed_id', status: 'updating', message: '...' }] listen('feed-update-status', (event) => {
const newStatus = event.payload;
updateTasks.update(tasks => {
// 更新或添加任务状态
const index = tasks.findIndex(t => t.id === newStatus.id);
if (index !== -1) {
tasks[index] = { ...tasks[index], ...newStatus };
return [...tasks];
}
return [...tasks, newStatus];
});
});
- Tauri
invoke: 前端也可以主动调用 Rust 后端注册的命令(使用invoke('command_name', args))来获取当前状态或触发特定操作。
代码分析:
这种发布-订阅模式(Rust 发射事件,JS 监听)和请求-响应模式(JS 调用 invoke)是 Tauri 应用前后端通信的标准方式。tasks.svelte.ts 中的 Svelte store 充当了前端状态的单一数据源,简化了状态管理和 UI 更新。
5. 文件锁机制防止重复启动 (feeds_schedule_update.lock)
为了确保在任何时候只有一个 Saga Reader 实例在执行 Feed 更新调度(特别是在应用可以多实例运行或意外崩溃后重启的场景),引入了文件锁机制。这个锁文件通常位于应用的数据目录或一个可预知的位置。
- 获取锁:应用启动时,在初始化 Feed 更新调度器之前,会尝试以独占方式创建或打开这个锁文件。例如,在 Rust 中可以使用
fs_extra::flock::LockOptions或类似的库。 - 处理锁状态:
- 如果成功获取锁,则当前实例负责执行 Feed 更新调度。应用退出时需要释放锁。
- 如果获取锁失败(例如,文件已被其他进程锁定),则表示已有另一个实例在运行调度。当前实例就不再启动调度逻辑,但应用的其他功能(如 UI)可以正常运行。
代码分析:
在 或其调用者(如 的 app_setup)中,会有类似逻辑:
// 伪代码,示意文件锁逻辑
use std::fs::OpenOptions;
use std::path::PathBuf;
use fs2::FileExt; // 假设使用 fs2 crate
fn try_acquire_lock(lock_file_path: &PathBuf) -> Option<std::fs::File> {
let file = OpenOptions::new()
.read(true)
.write(true)
.create(true)
.open(lock_file_path)
.ok()?;
match file.try_lock_exclusive() {
Ok(_) => Some(file), // 成功获取锁
Err(_) => None, // 获取锁失败
}
}
// 在 app_setup 或启动调度器前
let lock_file_path = app_handle.path_resolver().app_data_dir().unwrap().join("feeds_schedule_update.lock");
if let Some(_lock_file_guard) = try_acquire_lock(&lock_file_path) {
// 成功获取锁,启动 Feed 更新调度器
// _lock_file_guard 会在作用域结束时自动释放锁 (RAII)
tokio::spawn(async move { feeds_updater.run_schedule().await; });
} else {
log::info!("Another instance is already running the feed update schedule.");
}
这确保了后台任务的唯一性,避免了资源竞争和数据不一致的问题。
四、结果与收益
新方案的实施带来了显著的成效:
- 大幅提升 Feed 抓取成功率:通过模拟真实浏览器环境和执行 JavaScript,新方案能够有效应对此前
reqwest直接 GET HTML 时遇到的反爬虫问题,不再轻易被识别为爬虫或触发对方网站的验证机制,从而确保了绝大多数 Feed 源都能成功抓取到最新内容。 - 更优的用户体验:后台静默更新和主窗口的按需显示,减少了对用户的干扰,使得 Feed 阅读体验更加流畅。
- 更健壮的更新机制:重构后的调度逻辑和错误处理更为完善,保证了更新任务的稳定性和可靠性。
五、总结与展望
本次围绕 Feed 更新的重构,核心在于引入了基于 Tauri 无头 WebView 和 JavaScript 注入的智能抓取方案,并优化了应用的后台运行与任务调度机制。这不仅解决了困扰已久的抓取成功率问题,也为 Saga Reader 未来的功能扩展(如更复杂的网页内容提取、自动化任务等)打下了坚实的基础。
未来,我们还可以进一步探索:
- 可配置的抓取脚本:允许用户或社区为特定网站贡献和定制抓取规则。
- 资源消耗优化:针对无头 WebView 的资源占用进行持续监控和优化。
- 更智能的调度策略:例如根据 Feed 更新频率、用户阅读习惯等动态调整更新计划。
涉及的核心代码文件
| 项目源码地址:https://github.com/sopaco/saga-reader
simulator:headless式抓取网页的实现。feeds_update.rs: Feed 更新调度、核心抓取逻辑(与 WebView 交互)、文件锁。app/src-tauri/src/lib.rs: 应用启动、后台模式处理、窗口管理、调度器初始化。
六、关于这个项目的一系列技术文章
- 开源我的一款自用AI阅读器,引流Web前端、Rust、Tauri、AI应用开发
- 【实战】深入浅出 Rust 并发:RwLock 与 Mutex 在 Tauri 项目中的实践
- 【实战】Rust与前端协同开发:基于Tauri的跨平台AI阅读器实践
- 揭秘 Saga Reader 智能核心:灵活的多 LLM Provider 集成实践 (Ollama, GLM, Mistral 等)
- Svelte 5 在跨平台 AI 阅读助手中的实践:轻量化前端架构的极致性能优化
- Svelte 5状态管理实战:基于Tauri框架的AI阅读器Saga Reader开发实践
- Svelte 5 状态管理全解析:从响应式核心到项目实战
【实战】基于 Tauri 和 Rust 实现基于无头浏览器的高可用网页抓取的更多相关文章
- 基于Casperjs的网页抓取技术【抓取豆瓣信息网络爬虫实战示例】
CasperJS is a navigation scripting & testing utility for the PhantomJS (WebKit) and SlimerJS (Ge ...
- 基于docker+etcd+confd + haproxy构建高可用、自发现的web服务
基于docker+etcd+confd + haproxy构建高可用.自发现的web服务 2016-05-16 15:12 595人阅读 评论(0) 收藏 举报 版权声明:本文为博主原创文章,未经博主 ...
- (转)基于Redis Sentinel的Redis集群(主从&Sharding)高可用方案
转载自:http://warm-breeze.iteye.com/blog/2020413 本文主要介绍一种通过Jedis&Sentinel实现Redis集群高可用方案,该方案需要使用Jedi ...
- 基于Redis Sentinel的Redis集群(主从Sharding)高可用方案(转)
本文主要介绍一种通过Jedis&Sentinel实现Redis集群高可用方案,该方案需要使用Jedis2.2.2及以上版本(强制),Redis2.8及以上版本(可选,Sentinel最早出现在 ...
- 【Docker】基于docker+etcd+confd + haproxy构建高可用、自发现的web服务
各个工具介绍 (1)Docker:Docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux机器上,也可以实现虚拟化,docker ...
- 基于Redis Sentinel的Redis集群(主从&Sharding)高可用方案
本文主要介绍一种通过Jedis&Sentinel实现Redis集群高可用方案,该方案需要使用Jedis2.2.2及以上版本(强制),Redis2.8及以上版本(可选,Sentinel最早出现在 ...
- 基于corosync+pacemaker+drbd+LNMP做web服务器的高可用集群
实验系统:CentOS 6.6_x86_64 实验前提: 1)提前准备好编译环境,防火墙和selinux都关闭: 2)本配置共有两个测试节点,分别coro1和coro2,对应的IP地址分别为192.1 ...
- Tachyon Cluster: 基于Zookeeper的Master High Availability(HA)高可用配置实现
1.Tachyon简介 Tachyon是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,就像Spark和 MapReduce那样.通过利用信息继承,内存侵入,Tachyon ...
- 基于Mysql 5.7 GTID 搭建双主Keepalived 高可用
实验环境 CentOS 6.9 MySQL 5.7.18 Keepalived v1.2.13 拓扑图 10.180.2.161 M1 10.180.2.162 M2 10.180.2.200 VIP ...
- 基于zookeeper(集群)+LevelDB的ActiveMq高可用集群安装、配置、测试
一. zookeeper安装(集群):http://www.cnblogs.com/wangfajun/p/8692117.html √ 二. ActiveMq配置: 1. ActiveMq集群部署 ...
随机推荐
- IDA Pro分析dll在exe中的表现
尝试分析隐式加载和显式加载的dll在exe中进行反汇编时的表现. 1. 测试条件 (1)动态库 testdll1 导出函数 int add(int, int) 和 int add2(int, in ...
- 接口介绍以及定义和使用--java进阶day02
1.接口介绍 日常生活中有很多接口,比如手机数据线的接口和手机充电器的接口 我们转换视角,站在设计者的角度思考接口,接口体现出规则,手机的接口大小和数据线的接口大小必须一致,各种接口的大小都要一致,都 ...
- Windows 鼠标右键失效
突然有一天...小邋遢他变了... 哦不是...鼠标右键/键盘菜单键莫名其妙失效了. 解决办法 运行 regedit 打开注册表编辑器 依次展开 HKEY_CURRENT_USER\Software\ ...
- 【AI工具实战】一招解决英文视频困境,四步用AI搞定全中文字幕,你也可以!(文末附工具下载)
"AI时代最大的红利,是让每个人都有机会成为那个"想到就能做到"的创造者." AI粉嫩特攻队,2025年4月5日. 故事源于一个我想看的国外视频.本想点开视频准 ...
- Sql查询(Select)语句实例
span { color: rgba(255, 0, 0, 1) } Select 结构: 句子结构: Select 列名 [all/distinct] from 表名 where 条件 group ...
- Avalonia跨平台实战(二),Avalonia相比WPF的便利合集(一)
本话讲的是Avalonia中相比于WPF更方便的一些特性 布局 布局方面没什么好说的,和WPF没什么区别,Grid,StckPanel...这些,不熟悉的话可以B站上找一下教程 xml树 在WPF中我 ...
- MySQL 的存储引擎有哪些?它们之间有什么区别?
MySQL 的存储引擎及其区别 MySQL 提供多种存储引擎,不同存储引擎在数据存储方式.索引支持.事务处理等方面各具特点.以下列出常用的存储引擎及其主要区别. 1. 常见存储引擎 (1)InnoDB ...
- 2025dsfz集训Day7: KMP与Trie树
Day7: KMP与Trie树 \[Designed\ By\ FrankWkd\ -\ Luogu@Lwj54joy,uid=845400 \] 特别感谢 此次课的主讲 - Kwling KMP算法 ...
- CF1546B题解
看了题面,一道简单的假交互题 题目传送门,另一个传送门 读好题目很重要 AquaMoon 有 nnn 个长度为 mmm 的字符串,其中 nnn 是奇数. 然后她选取 n−1n-1n−1 个字符串,将它 ...
- php获取前一天,前一个月,前半年,前一年的时间戳
#获取前一小时strtotime("-1 hour") #获取前一天strtotime("-1 day") #获取前一周strtotime("-1 w ...