LLM 上下文长度详细介绍
1、概述
在《Token:大语言模型的“语言乐高”,一切智能的基石》与《LLM 输出配置 (LLM output configuration)》这两篇博文中介绍了LLM Token、最大输出长度、温度、Top-K、Top-P概念,这篇文章介绍下LLM 上下文长度。
2、上下文长度
2.1 上下文长度介绍
“上下文长度” 在技术领域实际上有一个专有的名词:Context Window,以 DeepSeek 为例:
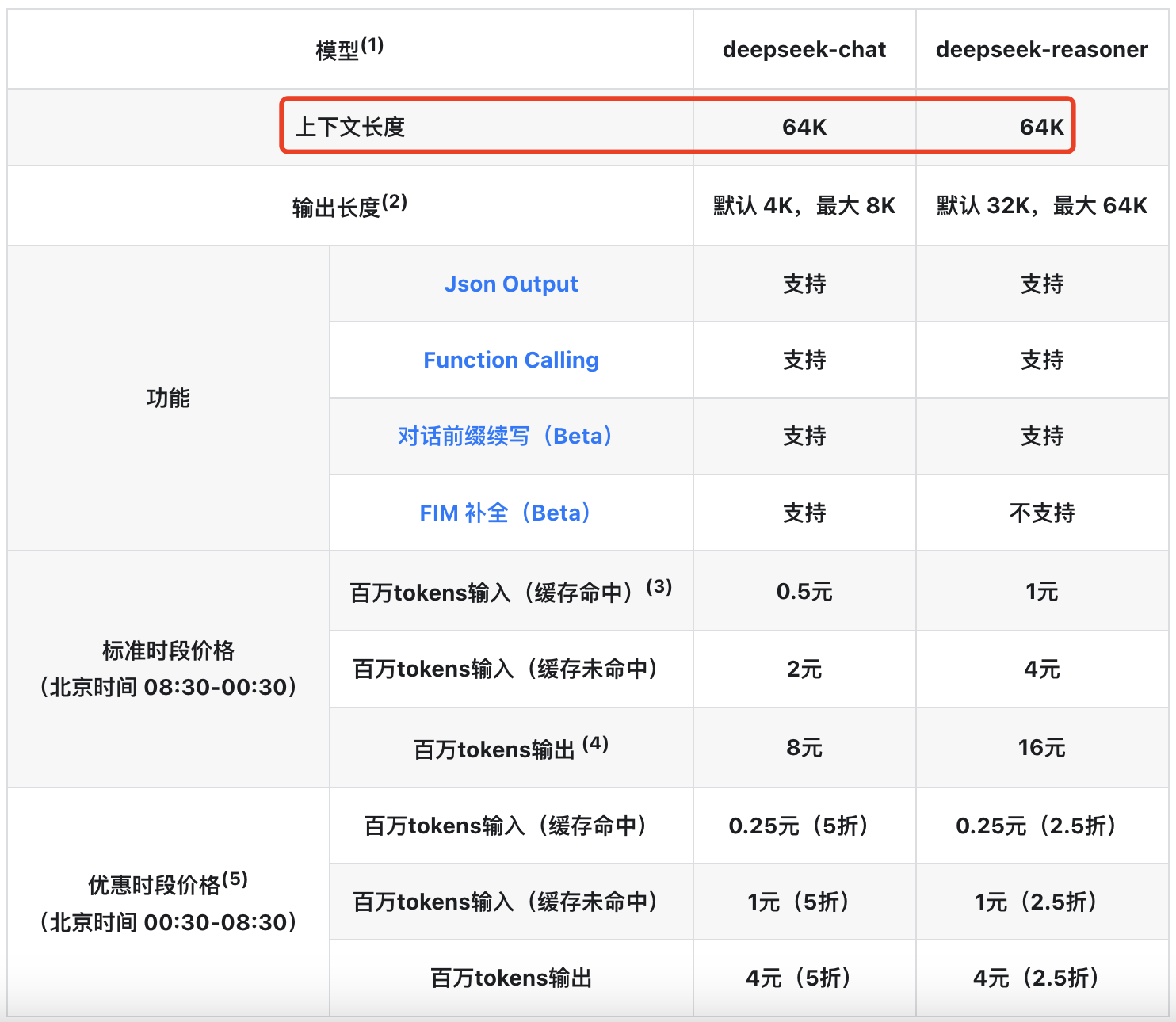
可以看到无论是推理模型还是对话模型 Context Window 都是 64K ,这个 64K 意味着什么呢 ?请继续往下看。
如果我们要给 Context Window 下一个定义,那么应该是这样:
LLM 的 Context Window 指模型在单次推理过程中可处理的全部 token 序列的最大长度,包括:
- 输入部分(用户提供的提示词、历史对话内容、附加文档等)
- 输出部分(模型当前正在生成的响应内容)
这里我们解释一下,比如当你打开一个 DeepSeek 的会话窗口,开启一个新的会话,然后你输入内容,接着模型给你输出内容。这就是一个单次推理 过程。在这简单的一来一回的过程中,所有内容(输入+输出)的文字(tokens)总和不能超过 64K(约 6 万多字)。
你可能会问,那输入多少有限制吗?
有。《LLM 输出配置 (LLM output configuration)》这篇博文中,我们介绍了 “输出长度”,我们知道DeepSeek V3模型最长输出长度 8K,那么输入内容的上限就是:64K- 8K = 56K。
总结来说在一次问答中,你最多输入 5 万多字,模型最多给你输出 8 千多字。
你可能还会问,那多轮对话呢?每一轮都一样吗?
不一样。这里我们要稍微介绍一下多轮对话的原理。
2.2 多轮对话
仍然以 DeepSeek 为例,假设我们使用的是 API 来调用模型。
多轮对话发起时,服务端不记录用户请求的上下文,用户在每次请求时,需将之前所有对话历史拼接好后,传递给对话 API。
以下是个示例代码:
from openai import OpenAI client = OpenAI(
# 直接调用DeepSeek API需要充值,这里使用阿里云百炼提供的DeepSeek V3模型进行演示
api_key="sk-1f005aa94357418ca6dc2fddaxxxxxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
) # Round 1
messages = [{"role": "user", "content": "世界上最高的山是什么,只回答结果不用详细介绍?"}]
response = client.chat.completions.create(
model="deepseek-v3",
messages=messages
) messages.append(response.choices[0].message)
print(f"Messages Round 1: {messages}") # Round 2
messages.append({"role": "user", "content": "第二高的呢?"})
response = client.chat.completions.create(
model="deepseek-v3",
messages=messages
) messages.append(response.choices[0].message)
print(f"Messages Round 2: {messages}")
在第一轮请求时,传递给 API 的 messages 为:
[
{"role": "user", "content": "世界上最高的山是什么?"}
]
输出结果:
Messages Round 1: [{'role': 'user', 'content': '世界上最高的山是什么,只回答结果不用详细介绍?'}, ChatCompletionMessage(content='珠穆朗玛峰。', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None)]
在第二轮请求时:
- 要将第一轮中模型的输出添加到 messages 末尾
- 将新的提问添加到 messages 末尾
最终传递给 API 的 messages 为:
[
{'role': 'user', 'content': '世界上最高的山是什么,只回答结果不用详细介绍?'},
ChatCompletionMessage(content='珠穆朗玛峰。', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None),
{'role': 'user', 'content': '第二高的呢?'}
]
输出结果:
[{'role': 'user', 'content': '世界上最高的山是什么,只回答结果不用详细介绍?'}, ChatCompletionMessage(content='珠穆朗玛峰。', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None), {'role': 'user', 'content': '第二高的呢?'}, ChatCompletionMessage(content='乔戈里峰。', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None)]
所以多轮对话其实就是:把历史的记录(输入+输出)后面拼接上最新的输入,然后一起提交给大模型。
那么在多轮对话的情况下,实际上并不是每一轮对话的 Context Window 都是 64K,而是随着对话轮次的增多 Context Window 越来越小。比如第一轮对话的输入+输出使用了 32K,那么第二轮就只剩下 32K 了,原理正如上文我们分析的那样。
到这里你可能还有疑问 :不对呀,如果按照你这么说,那么我每轮对话的输入+输出 都很长的话,那么用不了几轮就超过模型限制无法使用了啊。可是我却能正常使用,无论多少轮,模型都能响应并输出内容。
这是一个非常好的问题,这个问题涉及下一个概念,我把它叫做 “上下文截断”
2.3 上下文截断
在我们使用基于大模型的产品时(比如 DeepSeek、腾讯元宝),服务提供商不会让用户直接面对硬性限制,而是通过 “上下文截断” 策略实现“超长文本处理”。(提升用户体验)
举例来说:模型原生支持 64K,但用户累计输入+输出已达 64K ,当用户再进行一次请求(比如输入有 2K)时就超限了,这时候服务端仅保留最后 64K tokens 供模型参考,前 2K 被丢弃。对用户来说,最后输入的内容被保留了下来,最早的输入(甚至输出)被丢弃了。
这就是为什么在我们进行多轮对话时,虽然还是能够得到正常响应,但大模型会产生 “失忆” 的状况。没办法,Context Window 就那么多,记不住那么多东西,只能记住后面的忘了前面的。
这里请注意,“上下文截断” 是工程层面的策略,而非模型原生能力 ,我们在使用时无感,是因为服务端隐藏了截断过程。(提升用户体验)
2.4 技术原理
为什么要有这些限制呢?从技术的角度讲比较复杂,我们简单说一下,感兴趣的可以顺着关键词再去探索一下。
在模型架构层面,上下文窗口是硬性约束,由以下因素决定:
- 位置编码的范围:Transformer 模型通过位置编码(如 RoPE、ALiBi)为每个 token 分配位置信息,其设计范围直接限制模型能处理的最大序列长度。
- 自注意力机制的计算方式:生成每个新 token 时,模型需计算其与所有历史 token(输入+已生成输出) 的注意力权重,因此总序列长度严格受限。KV Cache 的显存占用与总序列长度成正比,超过窗口会导致显存溢出或计算错误。
3、上下文长度典型场景与应对策略
既然知道了最大输出长度和上下文长度的概念,也知道了它们背后的逻辑和原理,那么我们在使用大模型工具时就要有自己的使用策略,这样才能事半功倍。
(1)短输入 + 长输出
- 场景:输入 1K tokens,希望生成长篇内容。
- 配置:设置 max_tokens=63,000(需满足 1K + 63K ≤ 64K)。
- 风险:输出可能因内容质量检测(如重复性、敏感词)被提前终止。
(2)长输入 + 短输出
- 场景:输入 60K tokens 的文档,要求生成摘要。
- 配置:设置 max_tokens=4,000(60K + 4K ≤ 64K)。
- 风险:若实际输出需要更多 tokens,需压缩输入(如提取关键段落)。
(3)多轮对话管理
规则:历史对话的累计输入+输出总和 ≤ 64K(超出部分被截断)。
示例:
- 第1轮:输入 10K + 输出 10K → 累计 20K
- 第2轮:输入 30K + 输出 14K → 累计 64K
- 第3轮:新输入 5K → 服务端丢弃最早的 5K tokens,保留最后 59K 历史 + 新输入 5K = 64K。
4、总结
- 上下文窗口(如 64K)是模型处理单次请求的硬限制,输入+输出总和不可突破;
- 服务端通过上下文截断历史 tokens,允许用户在多轮对话中突破 Context Window限制,但牺牲长期记忆。(注意:“上下文截断” 是工程层面的策略,而非模型原生能力 ,我们在使用时无感,是因为服务端隐藏了截断过程。(提升用户体验))
LLM 上下文长度详细介绍的更多相关文章
- 上下文Context详细介绍
1.先看看它的继承结构,下图可以看出Context首先是一个抽象类,继承了Object,Activity,Service,Application都继承了它 2.API中对它的描述: @1Context ...
- linux awk 内置函数详细介绍(实例)
这节详细介绍awk内置函数,主要分以下3种类似:算数函数.字符串函数.其它一般函数.时间函数 一.算术函数: 以下算术函数执行与 C 语言中名称相同的子例程相同的操作: 函数名 说明 atan2( y ...
- linux awk 内置函数详细介绍(实例)
这节详细介绍awk内置函数,主要分以下3种类似:算数函数.字符串函数.其它一般函数.时间函数 一.算术函数: 以下算术函数执行与 C 语言中名称相同的子例程相同的操作: 函数名 说明 atan2( y ...
- 模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理、分类及应用
模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理.分类及应用 lqfarmer 深度学习研究员.欢迎扫描头像二维码,获取更多精彩内容. 946 人赞同了该文章 Atte ...
- linux配置网卡IP地址命令详细介绍及一些常用网络配置命令
linux配置网卡IP地址命令详细介绍及一些常用网络配置命令2010-- 个评论 收藏 我要投稿 Linux命令行下配置IP地址不像图形界面下那么方 便,完全需要我们手动配置,下面就给大家介绍几种配置 ...
- Java 集合系列05之 LinkedList详细介绍(源码解析)和使用示例
概要 前面,我们已经学习了ArrayList,并了解了fail-fast机制.这一章我们接着学习List的实现类——LinkedList.和学习ArrayList一样,接下来呢,我们先对Linked ...
- Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例
概要 这一章,我们对HashMap进行学习.我们先对HashMap有个整体认识,然后再学习它的源码,最后再通过实例来学会使用HashMap.内容包括:第1部分 HashMap介绍第2部分 HashMa ...
- Java 集合系列11之 Hashtable详细介绍(源码解析)和使用示例
概要 前一章,我们学习了HashMap.这一章,我们对Hashtable进行学习.我们先对Hashtable有个整体认识,然后再学习它的源码,最后再通过实例来学会使用Hashtable.第1部分 Ha ...
- web.xml 详细介绍(转)
web.xml 详细介绍 1.启动一个WEB项目的时候,WEB容器会去读取它的配置文件web.xml,读取<listener>和<context-param>两个结点. 2.紧 ...
- Android manifest之manifest标签详细介绍
AndroidManifest详细介绍 本文主要对AndroidManifest.xml文件中各个标签进行说明.索引如下: 概要PART--01 manifest标签PART--02 安全机制和per ...
随机推荐
- JMeter BeanShell 获取 HTTP Request 中的 Name
场景:添加 JMeter log 输出,想输入自定义请求的名称 // 获取 response body prev.getResponseDataAsString(); // 获取 HTTP Reque ...
- Ubuntu 下查看 ip
博客地址:https://www.cnblogs.com/zylyehuo/ ip a
- Docker,vs2019下 使用.net core创建docker镜像 遇到的一些问题
步骤主要分为以下几步: 1.创建docker for linux 的.netcore 项目(vs 自动创建了dockerfile 如果没有需要自己创建在根目录下) 2.编译项目到指定目录下 3.b ...
- Object类--equals方法--java进阶day05
1.equals方法 2.equals方法的逻辑 如图,我们发现调用equals方法将两个属性一样的变量进行比较时,返回的还是false 为了了解清楚equals方法的逻辑,我们ctrl 鼠标右键点击 ...
- 0x02 数据结构
目录 数据结构 链表与邻接表 单链表 双链表 栈与队列 单调栈与队列 KMP KMP算法 Trie字典树 并查集 朴素并查集 维护Size的并查集 维护到祖宗节点距离的并查集 堆 哈希表 拉链法 开放 ...
- java一个校验对象是否为null的豪华大礼包
自写的校验所有类型是否为null的工具类, 懒人福音,嘎嘎好用. 1 /** 2 * 一个校验对象是否为null的豪华大礼包 3 * 可以校验:Collection,Map,String,Enumer ...
- mysql 的group by 满足的规则要求
GROUP BY满足的规则: 所有select 字段,除了聚合函数中的字段,都必须出现在GROUP BY 中. 例如:SELECT name,age,max(salary) FROM t_employ ...
- 🎀Markdown介绍与语法
简介 Markdown是一种轻量级的标记语言,由John Gruber于2004年创建.它的设计目标是让人们能够使用易读易写的纯文本格式编写文档,并且可以通过工具将其转换为结构化的HTML(超文本标记 ...
- mysql、PikaDB的使用方法和优化策略
Mysql 字段选择 尽量选用INT,BIGINT,4字节8字节的消耗小于varchar.字符串选择VARCHAR增加拓展性. 时间应使用时间戳BIGINT存储,不使用DATETIME. 不使用BLO ...
- App自动化的元素定位
一.Appium定位步骤 打开appium,输入本地IP,点击启动服务器 1.点击启动检查器会话 2.配置所需功能,点击启动会话 二.App页面元素 App页面元素分为布局和控件两种 1.布局 Fra ...