为什么别人用 DevPod 秒启 DeepSeek-OCR,你还在装环境?
60 秒启动开发环境,即刻运行前沿 OCR 模型——DevPod 正在重塑 AI 开发工作流, 当环境不再是障碍,创新才真正开始
一、痛点剖析:传统 AI 开发为何举步维艰?
随着大模型技术的迅猛发展,AI 应用开发正加速从传统软件工程范式向 AI 原生架构 演进。在这一浪潮中,OCR(光学字符识别) 作为连接视觉世界与数字文本的关键桥梁,其战略价值日益凸显——无论是文档智能处理、办公自动化、科研数据提取,还是金融报告解析,OCR 都已成为不可或缺的核心能力。
正是在这一背景下,DeepSeek OCR 应运而生。这个由 DeepSeek-AI 团队最近推出的开源模型,不仅是一个高精度的端到端 OCR 系统,更是一次对 “视觉-文本压缩”新范式 的探索:
利用视觉模态对长文本进行高效压缩,仅需少量视觉 token 即可还原数千字的原始内容。
实验表明:
- 压缩比 < 10× 时,识别精度高达 97%;
- 即便在 20× 高压缩比下,仍能维持约 60% 的准确率。
这一能力使其在历史文献数字化、长上下文压缩、大模型训练数据生成等前沿场景中展现出巨大潜力。
然而,要真正释放 DeepSeek OCR 的技术优势,开发者首先必须跨越一道高门槛:复杂的运行环境依赖——包括高分辨率图像处理、多模态模型推理、GPU 加速支持等。在传统开发模式下,繁琐的环境配置已成为阻碍先进模型快速落地的“拦路虎”。
真实开发中的三大典型困境:
- 场景 1:新工程师的“一天环境配置”困局
一位经验丰富的 AI 工程师入职新团队,本想快速投入开发,却耗费数小时甚至一天解决 Python 版本冲突、CUDA 安装失败、依赖包不兼容等问题,最终发现团队的环境文档早已过时。 - 场景 2:数据科学家的“模型试用困境”
想快速验证 DeepSeek OCR 在项目中的效果,却卡在依赖安装环节——PyTorch 与 CUDA 版本不匹配导致推理失败,半天过去仍未跑通。 - 场景 3:团队协作的“环境一致性噩梦”
三位开发者本地环境略有差异,代码各自能跑,但一部署到测试环境就频繁报错。排查发现竟是 NumPy 版本差异引发的浮点精度问题,修复时间甚至超过开发本身。
这些场景共同揭示了传统 AI 开发模式的系统性缺陷:效率低下、资源浪费、协作成本高昂。
根源剖析:三大结构性短板
| 维度 | 问题表现 |
|---|---|
| 环境一致性危机 | “在我机器上能跑”魔咒频现;依赖冲突、文档滞后;版本差异引发隐蔽 Bug |
| 资源利用效率低下 | GPU 闲置、存储压力大;缺乏弹性伸缩,资源利用率长期低于 30% |
| 开发体验断崖式下滑 | 大量时间耗在环境搭建而非核心逻辑;调试成本高,协作效率低 |
核心结论:传统 AI 开发模式已成为制约创新的系统性瓶颈。唯有重构开发基础设施,才能释放 AI 原生时代的真正生产力。
二、DevPod:基于 Serverless 的 AI 开发环境
面对上述挑战,阿里云 DevPod 依托 云原生 + Serverless 架构,为 DeepSeek OCR 提供 开箱即用、高性能、低成本 的云端开发环境,真正实现 “60 秒启动,即刻推理” 的高效体验。
DevPod 的三大核心优势
1. 云原生环境标准化
- 环境一致性保障:通过预构建容器镜像,确保从开发到生产的全生命周期环境一致,彻底终结“环境漂移”。
- 依赖预装与优化:PyTorch、Transformers、CUDA 等 DeepSeek OCR 所需依赖已预先安装并调优,无需手动配置,真正做到“即开即用”。
2. 按需付费
- 秒级启停:只为实际使用的计算与存储资源付费,避免 GPU 闲置浪费。
3. 开箱即用的 AI 工具链
- VSCode Web IDE:支持代码高亮、Git 集成、插件扩展,媲美本地开发体验。
- Jupyter Notebook:交互式调试、数据可视化、实验记录一体化。
- 终端环境:完整 Linux 命令行,支持 pip、脚本执行、系统监控。
- 预置模型服务:DeepSeek OCR 模型已预下载至持久化存储,启动即推理。
DevPod vs 传统开发模式对比
| 维度 | 传统本地开发 | 云端虚拟机 | DevPod |
|---|---|---|---|
| 环境配置时间 | 2–8 小时 | 30–60 分钟 | 60 秒 |
| 资源利用率 | <30% | 60–80% | >90% |
| 成本效率 | 低(固定成本) | 中(按小时计费) | 高(按使用量计费) |
| 环境一致性 | 差 | 中 | 优 |
| 协作效率 | 差 | 中 | 优 |
DevPod 不仅是工具升级,更是开发范式的跃迁。
三、实战指南:60 秒搭建 DeepSeek OCR 开发环境
第一步:准备工作
- 阿里云账号:已完成实名认证。
- 访问FunModel 控制台。
- 完成 RAM 角色授权(确保 DevPod 可访问必要云资源)。
提示:若使用旧版控制台,请点击右上角“新版控制台”切换。
第二步:创建 DevPod 环境
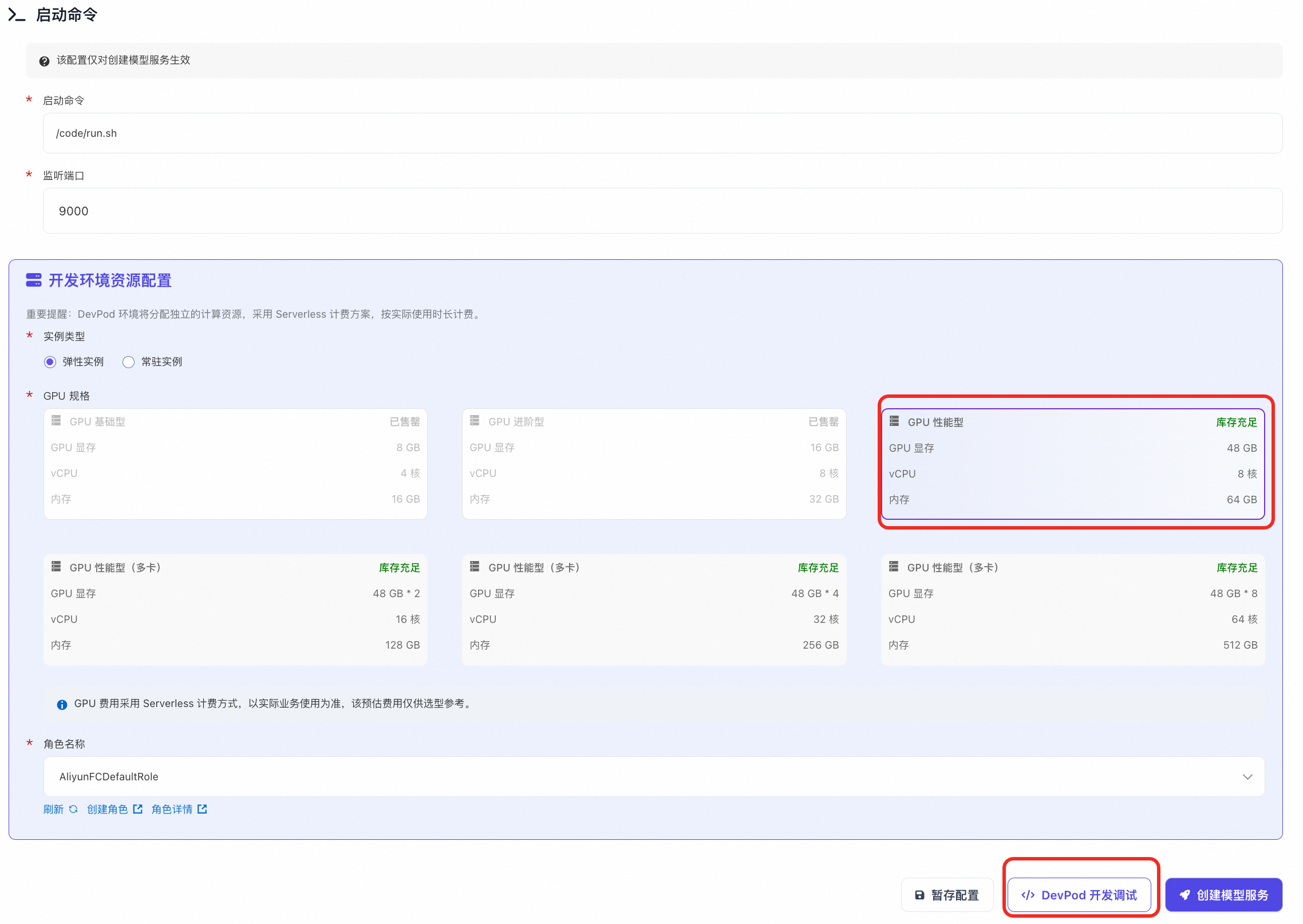
- 点击 “自定义开发” → 选择 “自定义环境”。
- 配置关键参数:
- 镜像地址:
- 中国大陆:
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:deepseek-ocr-v1 - 海外地区:
serverless-registry.ap-southeast-1.cr.aliyuncs.com/functionai/devpod-presets:deepseek-ocr-v1
- 中国大陆:
- 模型命名:如
deepseek-ocr-dev - 模型来源:
deepseek-ai/DeepSeek-OCR(ModelScope 链接) - 实例规格:推荐 GPU 性能型(适用于 OCR 推理)
- 镜像地址:
- 点击 “DevPod 开发调试” 启动环境(️ 不要点“创建模型服务”)。
系统将自动:
- 拉取镜像
- 下载模型: 约 1 分钟(内置加速)
- 配置 CUDA 与 GPU
- 初始化 VSCode / Jupyter / 终端
排除下载将近 7G 模型文件的耗时,整个过程 60 秒内完成。

四、深度实践:在 DevPod 中运行 DeepSeek OCR
环境架构说明
- 持久化存储:
/mnt/{模型名称},如/mnt/deepseek-ocr-dev(NAS 挂载,重启不丢失) - 临时工作区:/workspace(容器内临时目录,DevPod 删除后清空,停止时不删除)
- 模型缓存:已预加载至 NAS,推理秒级启动
支持两种主流推理框架
请先在 WebIDE 中打开终端:
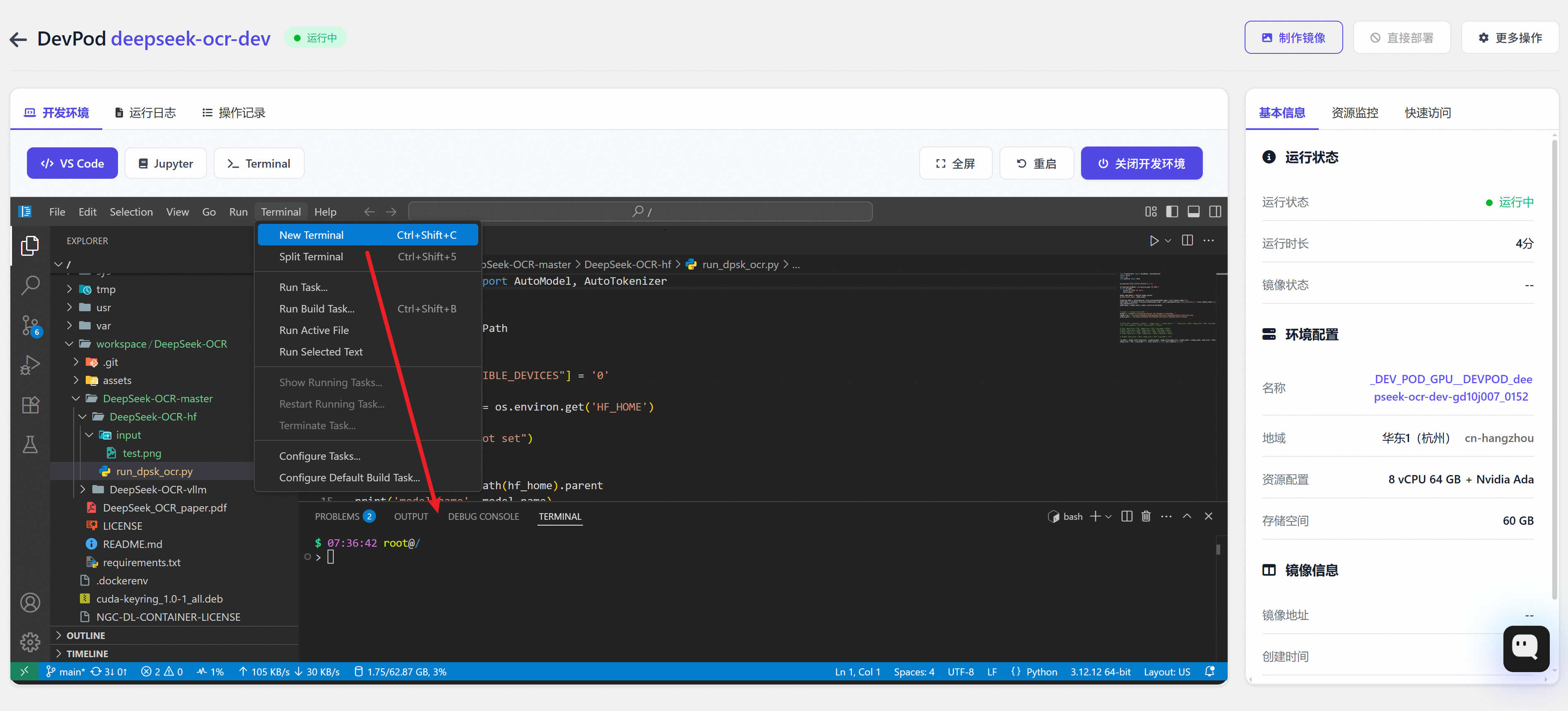
方式一:HuggingFace Transformers(快速实验)
cd /workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-hf
python run/dpsk/ocr.py
- 输出路径:
./output/ - 替换图片:修改
input/test.png - 自定义逻辑:编辑
run/dpsk/ocr.py
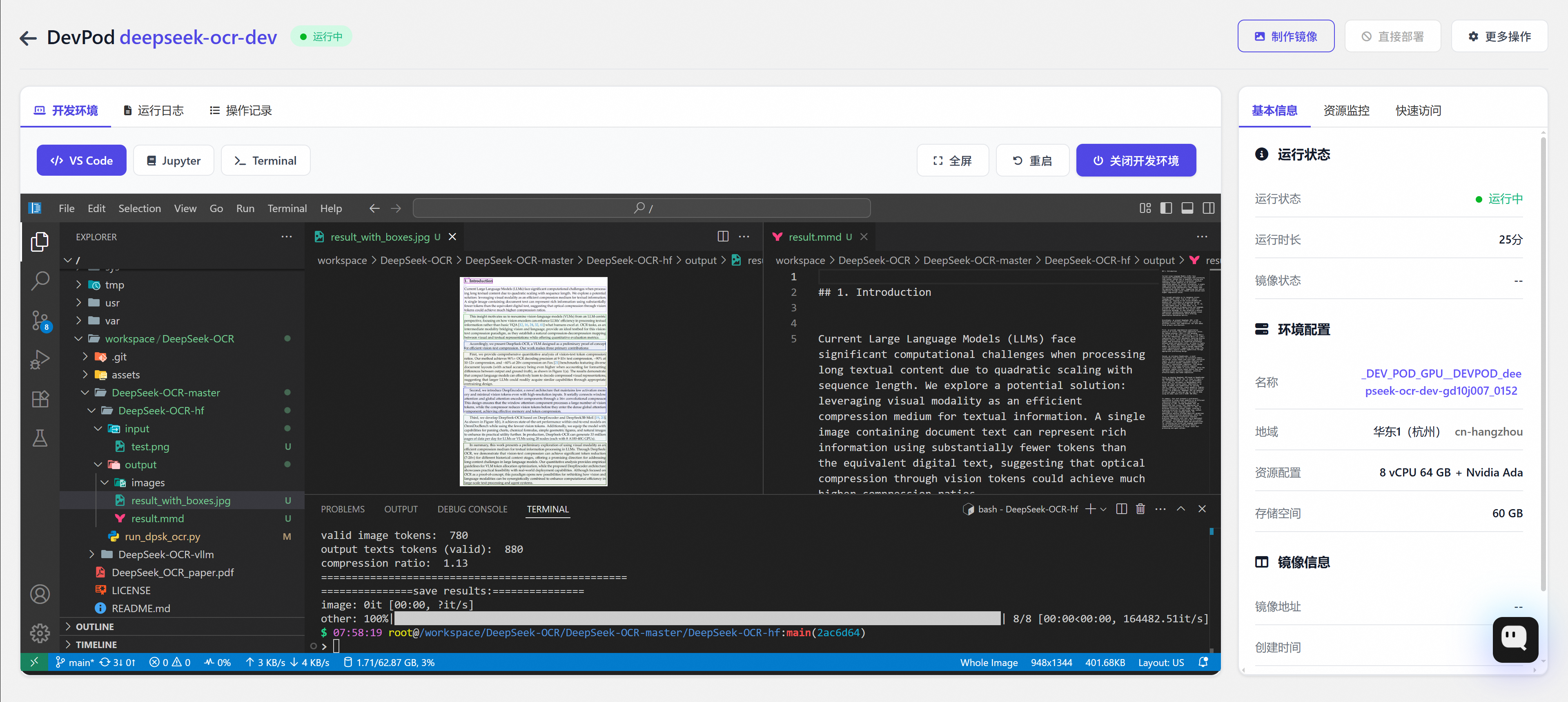
方式二:vLLM(高性能推理)
支持 单图、PDF、批量图像 处理。
单图推理:
python
# /workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py
INPUT_PATH = '/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/input_image/test.png'
OUTPUT_PATH = '/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/output_run_dpsk_ocr_image'
bash
cd /workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm
python run/dpsk/ocr/image.py

PDF 处理:
python
# /workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py
INPUT_PATH = '/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/input_pdf/test.pdf'
OUTPUT_PATH = '/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/output_run_dpsk_ocr_pdf'
bash
cd /workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm
python run/dpsk/ocr/pdf.py
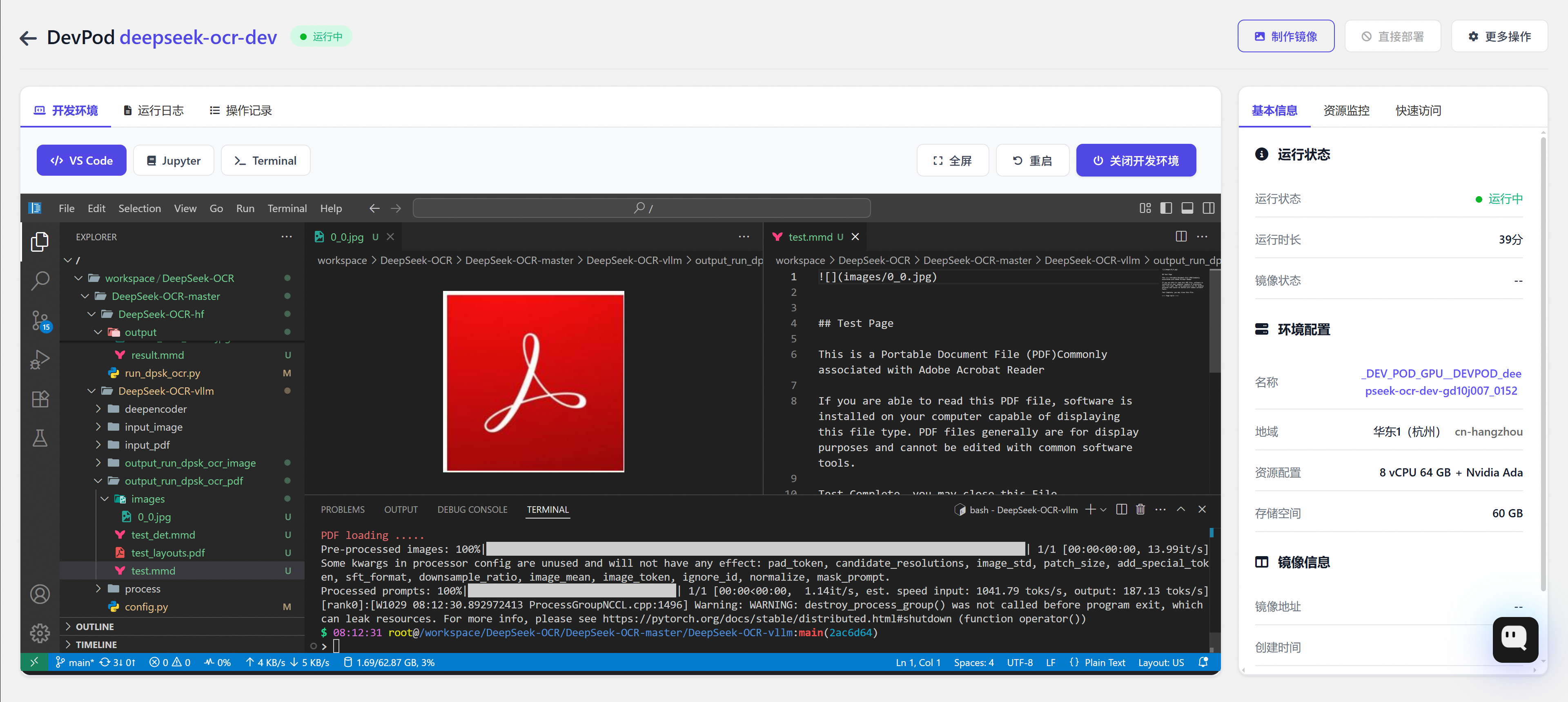
批量图像处理:
python
# /workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py
INPUT_PATH = '/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/input_image/'
OUTPUT_PATH = '/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/output_run_dpsk_ocr_eval_batch/'
bash
cd /workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm
python run/dpsk/ocr/eval/batch.py
操作建议
- 添加更多图像:将待处理图片放入
input/image/目录即可自动纳入批处理流程。- 调整批处理逻辑:如需控制并发数、跳过已处理文件或添加日志记录,可修改
run/dpsk/ocr/eval/batch.py。

五、范式转变:DevPod 重塑 AI 开发工作流
DevPod 的意义远不止“省去环境配置”——它正在推动 AI 开发从"手工作坊”走向“现代工程”。
1. 从“配置环境”到“专注创造”
你不再需要关心:
- CUDA 是否兼容?
- PyTorch 版本是否匹配?
- 依赖是否冲突?
所有这些,已在预构建镜像中完成优化。60 秒后,你已在写核心逻辑。
2. 标准化与可复用的开发基座
- 所有定制(包安装、环境变量等)可通过 镜像快照 保存。
- 一键分享给团队成员,彻底解决“环境漂移”。
- 镜像可直接用于后续训练或生产部署,打通 开发 → 调试 → 部署 全链路。
3. 数据与代码高效协同
- 热数据(代码、小数据集):存于 NAS
- 冷数据(原始图像、PDF):对接 OSS 对象存储
- 灵活的存储策略,兼顾开发效率与扩展性。
4. 面向未来的 AI 原生工作流
DevPod 将“环境”视为 工程资产 而非临时附属品,将“资源”转化为 按需使用的服务,将“协作”建立在 标准化基座 之上。
这不仅提升效率,更是一种工程文化的进化:开发更敏捷、协作更顺畅、交付更可靠。
总结:DevPod,开启 AI 原生开发新时代
在 DevPod 的赋能下,开发者可以:
- 60 秒启动:告别数小时环境配置
- 环境一致:消除“在我机器上能跑”的经典难题
- 成本优化:资源利用率 >90%,按需付费
- 高效协作:统一环境,提升团队交付质量
当每一个新项目都能在几分钟内拥有一个“正确”的起点,创新的门槛便真正降低了。 展望未来,DevPod 将持续深化与阿里云 AI 生态的整合,为开发者提供更智能、更个性化的开发体验。我们期待,DevPod 能成为 AI 原生时代的“基础设施底座”,助力每一位开发者 从想法到落地,快人一步。
参考
为什么别人用 DevPod 秒启 DeepSeek-OCR,你还在装环境?的更多相关文章
- 别人都在用数据分析软件,你还在用excel做数据分析?
之前听朋友吐槽过,他们是上千人的企业,但做数据分析居然还是靠手动上传数据,而且还是用的excel做的.但其实excel并不是企业做数据分析的好工具. 数据分析是指用适当的统计分析方法对收集来的大量数据 ...
- 如何编写自己的Linux安全检查脚本?
因为本人工作中要涉及到很多东西,审计(日志.数据神马的).源代码审计.渗透测试.开发一大堆东西,有些东西,越是深入去做,越会发现,没有工具或脚本,工作起来是有多么的坑. 工作的这段时间,自己写了几个工 ...
- [转自老马的文章]用MODI OCR 21种语言
作者:马健邮箱:stronghorse_mj@hotmail.com发布:2007.12.08更新:2012.07.09按照<MODI中的OCR模块>一文相关内容进行修订2012.07.0 ...
- 采用OCR识别自动识别财务报表
一. 财务报表有什么作用 财务报表又叫会计报表,包含:资产负债表.损益表.现金流量表三表.财务报表对企业经营状况有重要的参考意义: n 全面系统地揭示企业一定时期的财务状况.经营成果 ...
- 用MODI OCR 21种语言
作者:马健邮箱:stronghorse_mj@hotmail.com发布:2007.12.08更新:2012.07.09按照<MODI中的OCR模块>一文相关内容进行修订2012.07.0 ...
- OCR(光学字符识别)技术简介
OCR技术起源 OCR最早的概念是由德国人Tausheck最先提出的,1966年他们发表了第一篇关于汉字识别的文章,采用了模板匹配法识别了1000个印刷体汉字.早在60.70年代,世界各国就开始有OC ...
- 浅谈OCR之Onenote 2010
原文:浅谈OCR之Onenote 2010 上一次我们讨论了Tesseract OCR引擎的用法,作为一款老牌的OCR引擎,目前已经开源,最新版本3.0中更是加入了中文OCR功能,再加上Google的 ...
- 从别人的代码中学习golang系列--01
自己最近在思考一个问题,如何让自己的代码质量逐渐提高,于是想到整理这个系列,通过阅读别人的代码,从别人的代码中学习,来逐渐提高自己的代码质量.本篇是这个系列的第一篇,我也不知道自己会写多少篇,但是希望 ...
- 在Oracle中快速创建一张百万级别的表,一张十万级别的表 并修改两表中1%的数据 全部运行时间66秒
万以下小表做性能优化没有多大意义,因此我需要创建大表: 创建大表有三种方法,一种是insert into table selec..connect by.的方式,它最快但是数据要么是连续值,要么是随机 ...
- 如何临时发布部署Cocos小游戏到Linux服务器,让别人能在微信打开
两个星期前,我们发布了第一个小游戏教程: 教程:制作一个小游戏送给喜欢的TA(不会编程也能学会哦) 上周有好几位小伙伴在b站催更,呃,作为小透明,收到催更信息后还是很激动的!竟然有同学在看我们的小教程 ...
随机推荐
- $refs、$parent、$children的使用
$refs 作用 获取对应组件实例,如果是原生dom,那么直接获取的是该dom.获取之后我们可以使用它的属性和方法. 使用方法: // 我们需要获取实例ref (dom) <my-compone ...
- C++中调用QML对象
所有的QML对象类型,包括QML引擎内部实现或者实现第三方库,都是QObject子类,都允许QML引擎使用Qt元对象系统动态实例化任何QML对象类型. 在启动QML时,会初始化一个QQmlEngine ...
- MethodImplOptions.AggressiveInlining如果一个昂贵的参数没有被使用,它能阻止它被评估吗?
内联在这里没有帮助 你现在的代码是 void Log(string message, LogLevel logLevel) { if (logLevel >= chosenLogLevel) C ...
- 解决webstorm不能识别vue的@路径引用
vue3版本: 新建一个webpack.config.js文件中加入如下内容: module.exports = { resolve: { alias: { "@": requir ...
- BGP-LS原理及基本功能测试方法
BGP-LS产生的原因 BGP Link State是一种新型的收集网络拓扑信息的技术. 传统网络拓扑信息收集方式是路由器使用IGP(OSPF或IS-IS)协议收集网络拓扑信息,不同网络域中的IGP协 ...
- JavaFX 常见UI控件使用
UI 控件介绍 JavaFX 提供了一套丰富的用户界面控件,这些控件可以用来创建现代的.交互式的图形用户界面(GUI).JavaFX 控件是 JavaFX 库中预定义的组件,它们封装了创建用户界面元素 ...
- 2025年中国代码托管平台榜单:Gitee位居榜首,得益于本土优势与生态繁荣
Gitee领跑中国代码托管市场:本土化优势与全球化视野的双重奏 在数字经济蓬勃发展的今天,代码托管平台已成为企业数字化转型的重要基础设施.中国代码托管市场正以惊人的速度扩张,预计到2025年市场规模将 ...
- 稳定币落地前夜:财政司司长牵头,100+CEO与这家AI公司搞大事
2025 年 8 月 28 日下午,香港数码港会议厅的热度,比盛夏的维港更甚. 偌大的会场内座无虚席,香港金融领域的重要领导,以及数百位来自全球顶尖金融机构的 CEO.高管西装革履,手中的议程表被反复 ...
- git 本地协议、http、ssh、git协议优缺点总结对比
之前一直使用的是git的http协议来推拉代码,新公司使用的是git协议,好奇这两种的区别,科普了一下,https://cloud.tencent.com/developer/article/1347 ...
- vue3小坑之-为什么把ref定义的数组赋值给数组对象后取值为空数组?
天呢,居然两年没有上博客园看过了,呜呜呜,日渐废柴 这次总结一个码代码的时候遇到的问题,为什么把数据赋值给数组对象的某个字段,打印出来的是个空数组? 错误写法一: // 动态获取list值,前端可以增 ...