selenium爬虫学习1
简介
Selenium是广泛使用的模拟浏览器运行的库,它是一个用于Web应用程序测试的工具。 Selenium测试直接运行在浏览器中,就像真正的用户在操作一样,并且支持大多数现代 Web 浏览器。
函数介绍
重点方法
1.find_element方法是 Selenium WebDriver 提供的一种用于查找页面上某个符合条件的元素的方法。
2.find_elements 方法是 Selenium WebDriver 提供的一种用于查找页面上所有符合条件的元素的方法。与 find_element 不同,find_elements 返回的是一个列表,其中包含所有匹配的元素。如果没有找到任何元素,则返回一个空列表。
以下是 find_element(s) 方法的一些常见用法:
By.ID:通过元素的 ID 查找。
By.NAME:通过元素的 name 属性查找。
By.CLASS_NAME:通过元素的类名查找。
By.TAG_NAME:通过元素的标签名查找。
By.LINK_TEXT:通过链接文本查找。
By.PARTIAL_LINK_TEXT:通过部分链接文本查找。
By.CSS_SELECTOR:通过 CSS 选择器查找。
By.XPATH:通过 XPath 表达式查找。
driver.find_element对象具有.click()方法,就是点击这个元素
3.driver.window_handles获取当前所有窗口句柄
4.driver.switch_to.window()跳转到某个窗口
练习代码
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 初始化浏览器驱动
driver = webdriver.Chrome()
# 打开阿里云漏洞库首页
driver.get("https://avd.aliyun.com/")
time.sleep(2)
# 定位输入框并输入关键字
search_box = driver.find_element(By.XPATH, "/html/body/header/nav/div/form/input")
search_box.send_keys("MySQL")
# 点击搜索按钮
search_button = driver.find_element(By.XPATH, '/html/body/header/nav/div/form/button')
search_button.click()
# 等待2秒
time.sleep(2)
res_header=driver.find_element(By.ID,'itl-header')
print(res_header.text)
tr_elements = driver.find_elements(By.XPATH,"/html/body/main/div[2]/div/div[2]/table/tbody")
for tr in tr_elements:
# 在这里对每个tr元素进行操作,例如提取文本内容
print(tr.text)
link = driver.find_element(By.PARTIAL_LINK_TEXT, "AVD-2024-21177")
link.click()
all_windows = driver.window_handles
driver.switch_to.window(all_windows[-1])
searchclass=driver.find_elements(By.CSS_SELECTOR, '.border-bottom.border-gray.pb-2.mb-0')
for search in searchclass:
print(search.text)
time.sleep(3)
driver.close()
driver.switch_to.window(all_windows[0])# 切回原来的窗口
input("Press Enter to close the browser...")
# 关闭浏览器
driver.quit()
运行效果
运行过程
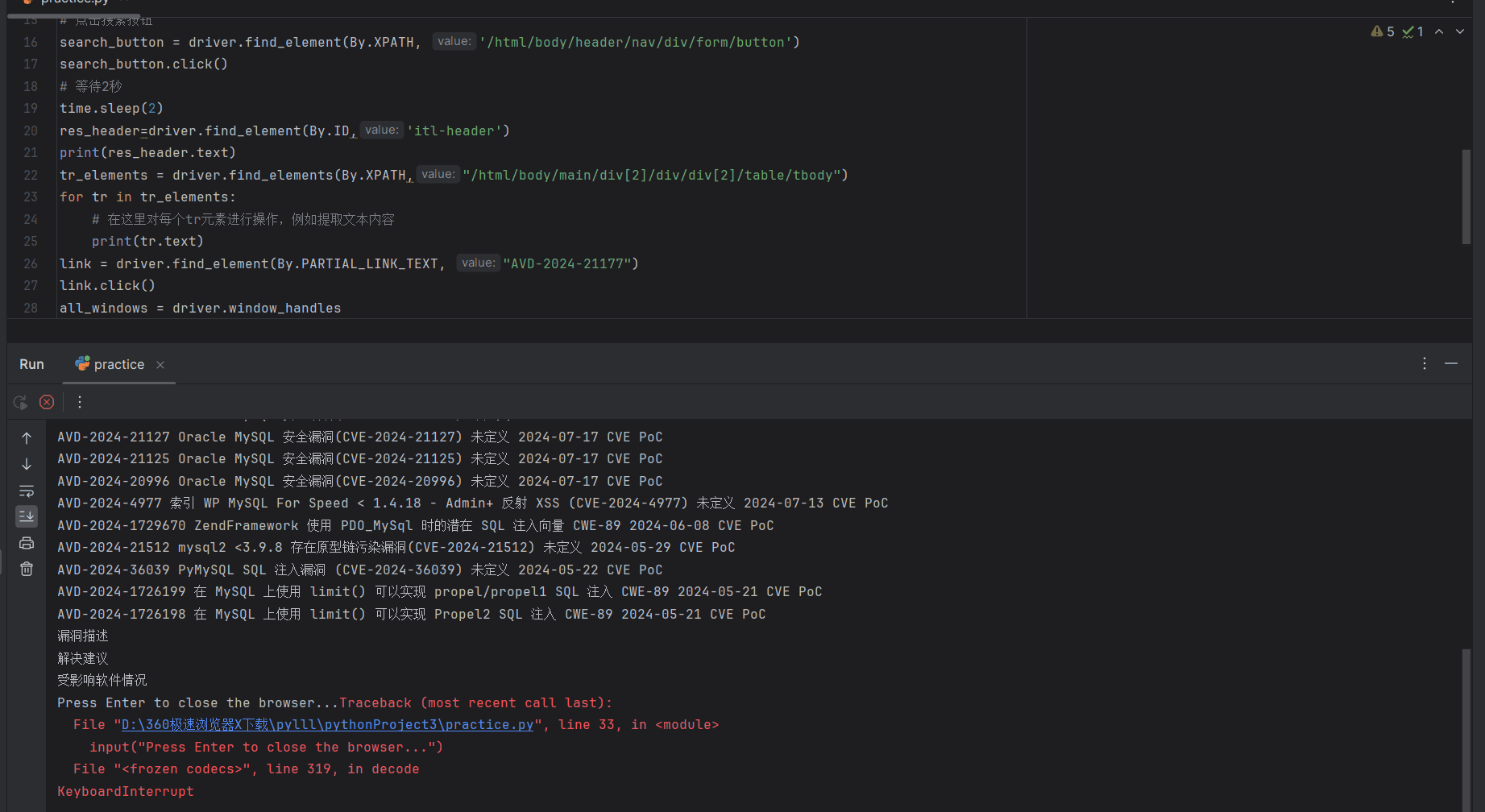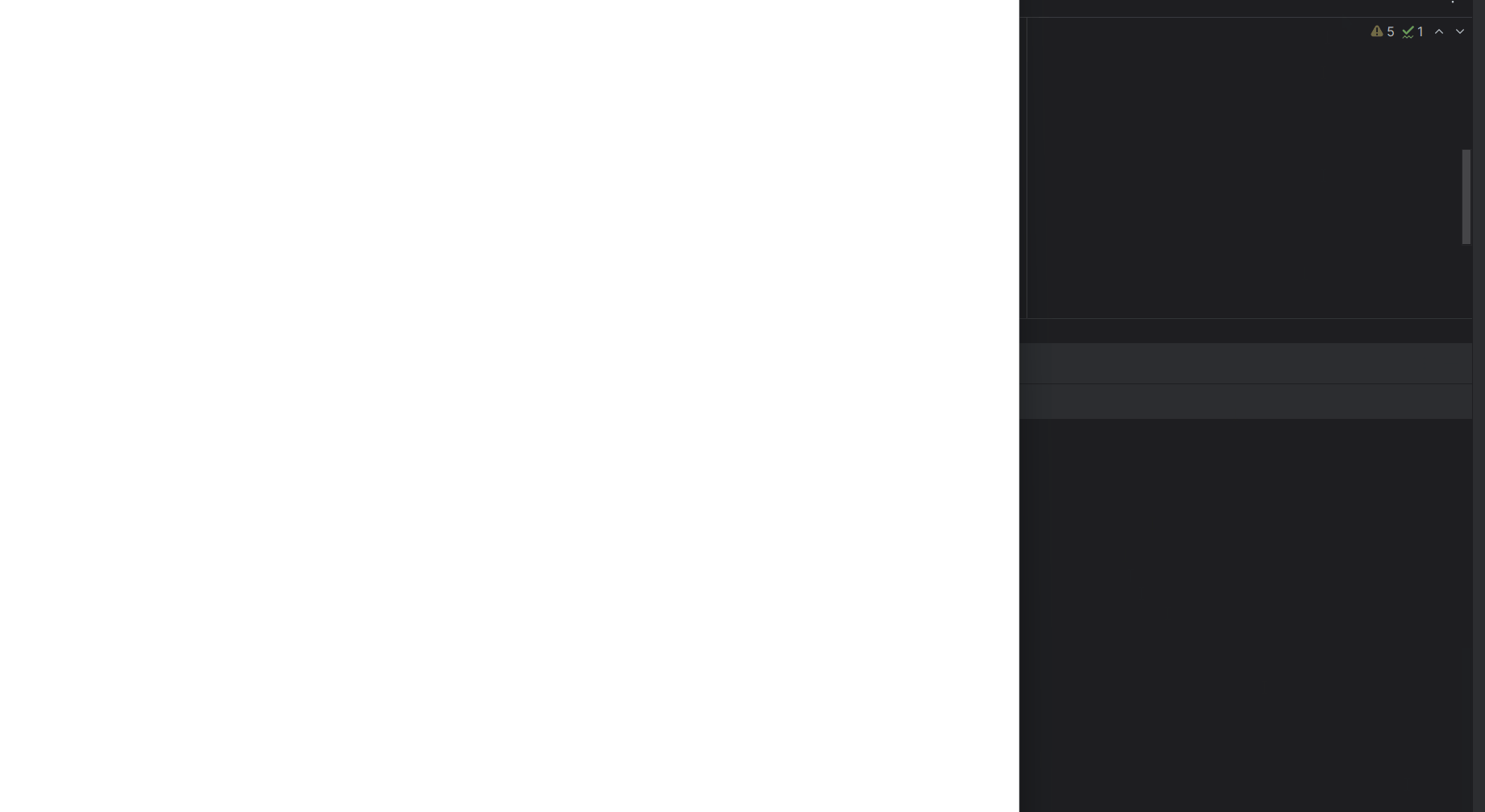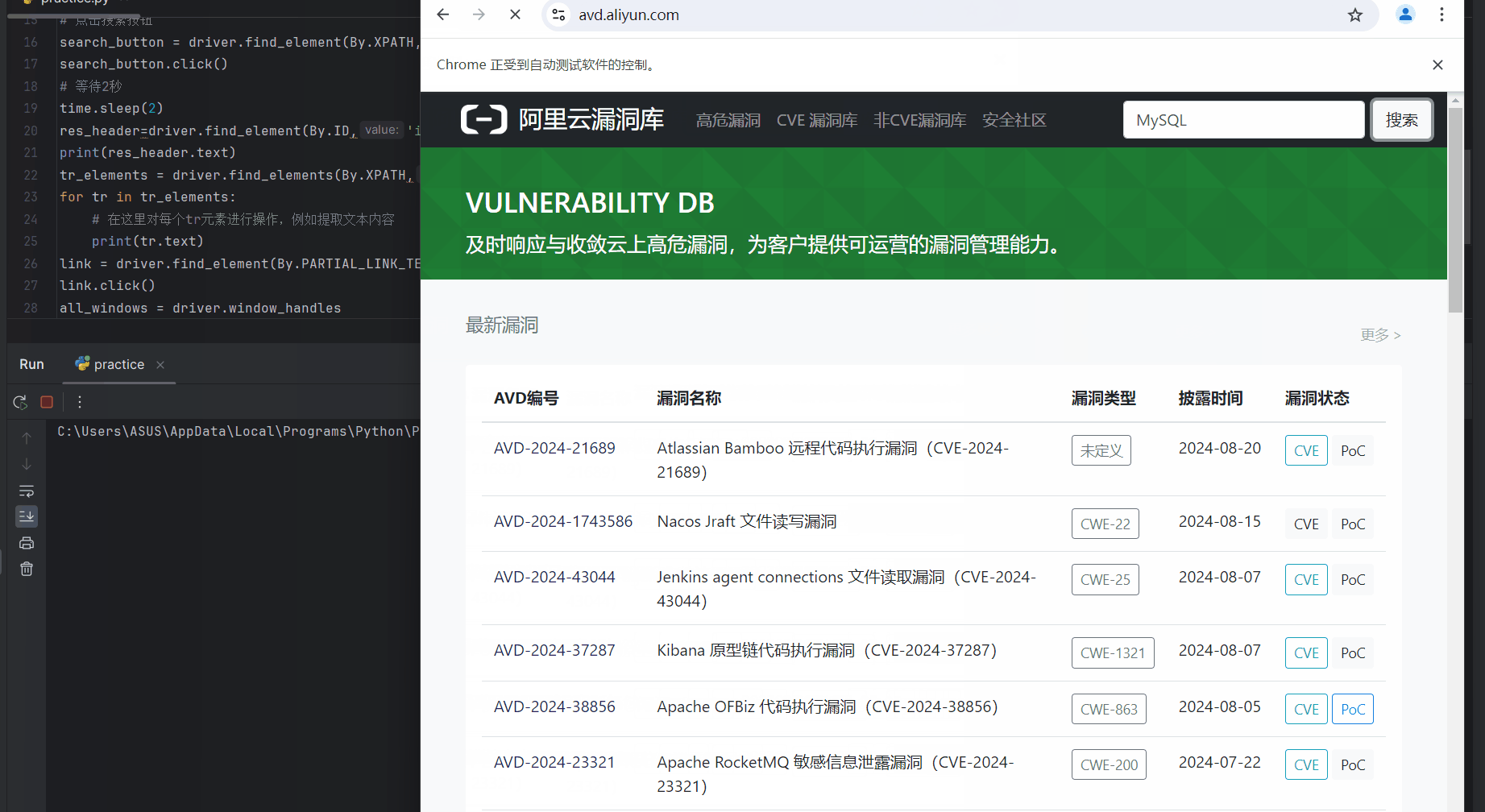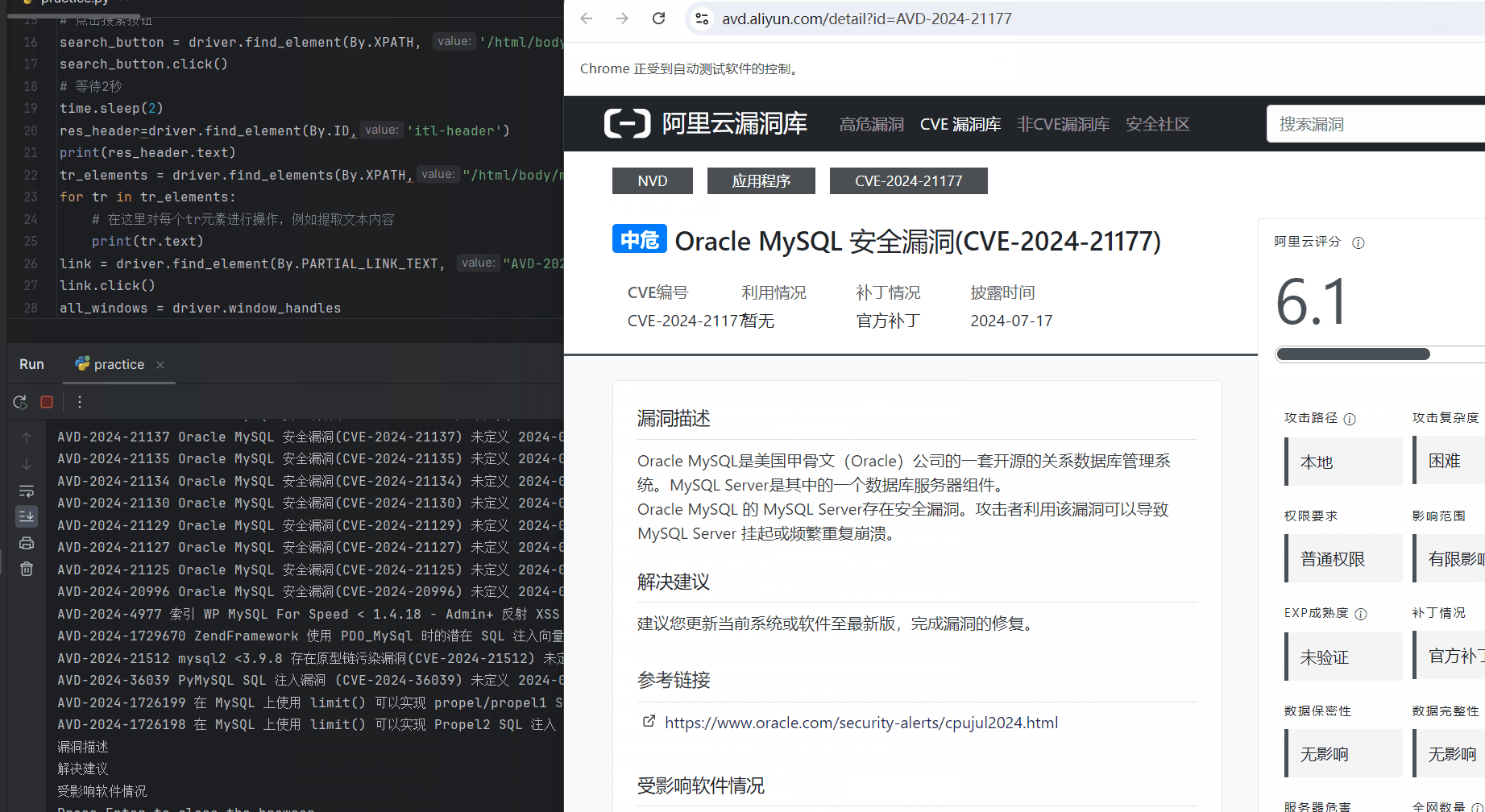
运行后先是打开浏览器进入阿里云漏洞库,紧接着搜索MYSQL相关漏洞,结果如下
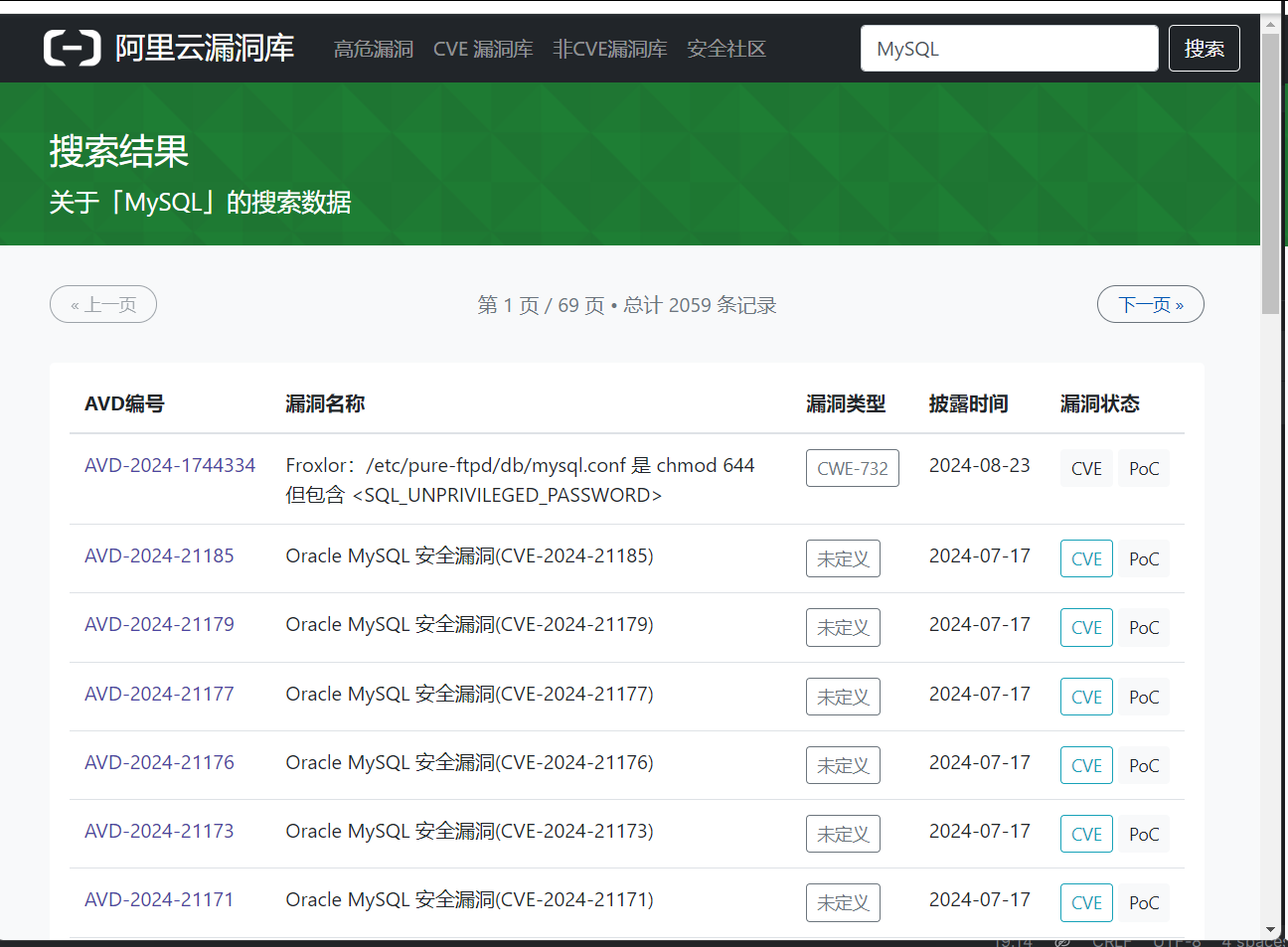
通过html的id属性找到“搜索结果 关于[mysql]的搜索数据”这几个字打印出来
tr_elements = driver.find_elements(By.XPATH,"/html/body/main/div[2]/div/div[2]/table/tbody")
res_header=driver.find_element(By.ID,'itl-header')
print(res_header.text)
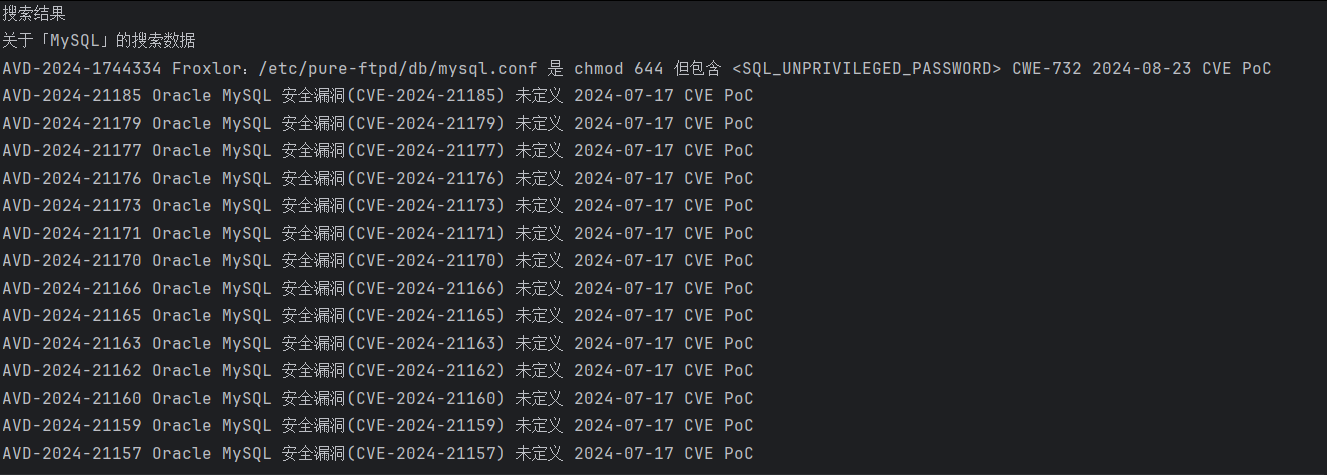
通过xpath找到tbody里面所有行,遍历并打印内容
tr_elements = driver.find_elements(By.XPATH,"/html/body/main/div[2]/div/div[2]/table/tbody")
for tr in tr_elements:
# 在这里对每个tr元素进行操作,例如提取文本内容
print(tr.text)
随便定位一个漏洞介绍的链接点进去:
link = driver.find_element(By.PARTIAL_LINK_TEXT, "AVD-2024-21177")
link.click()
all_windows = driver.window_handles # 获取所有窗口的句柄
driver.switch_to.window(all_windows[-1])#有的浏览器并不会自动跳转到点开的标签页,所以可以获取当前所有标签页再利用函数跳转
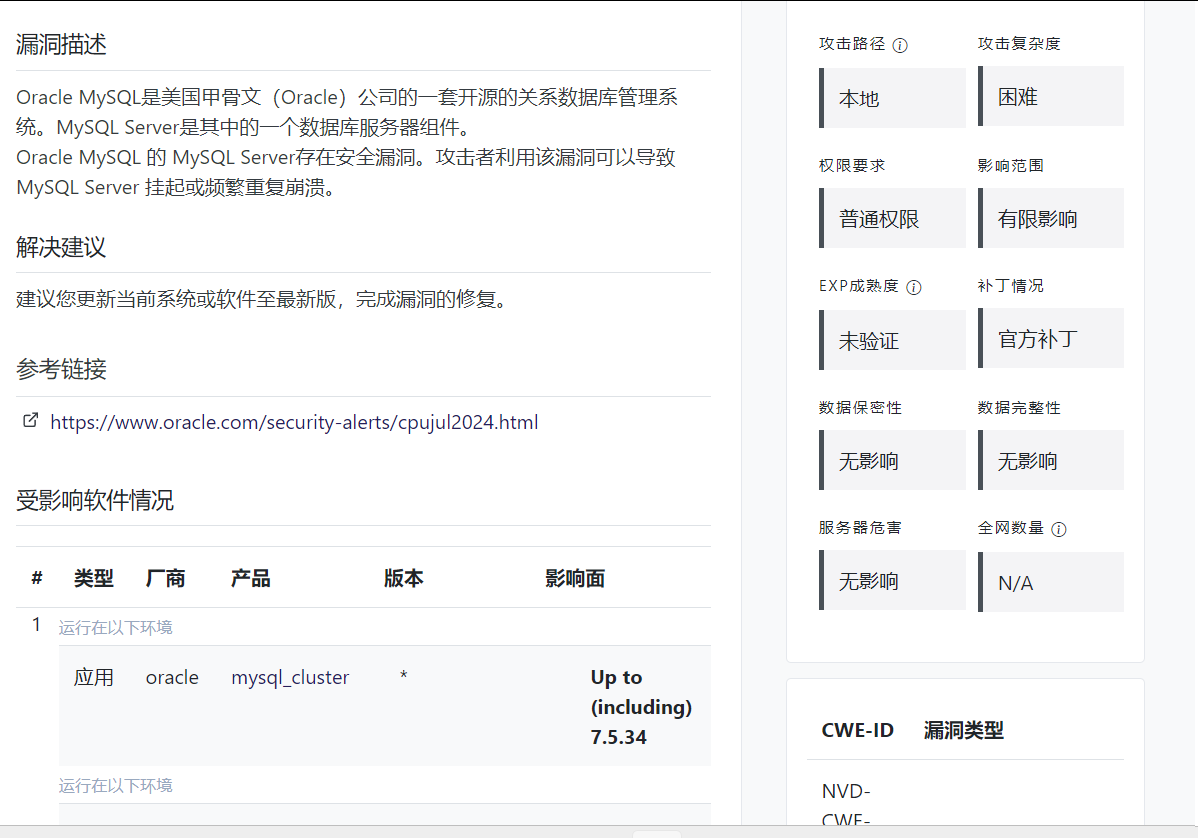
打印所有class="border-bottom border-gray pb-2 mb-0"的元素

searchclass=driver.find_elements(By.CSS_SELECTOR, '.border-bottom.border-gray.pb-2.mb-0')
for search in searchclass:
print(search.text)
因为class的值包含空格所以不能直接By.CLASS寻找,用By.CSS_SELECTOR,每个值用点号分隔
关闭浏览器
selenium爬虫学习1的更多相关文章
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Selenium Grid 学习笔记
Selenium Grid 学习笔记http://www.docin.com/p-765680298.html
- Selenium webdriver 学习总结-元素定位
Selenium webdriver 学习总结-元素定位 webdriver提供了丰富的API,有多种定位策略:id,name,css选择器,xpath等,其中css选择器定位元素效率相比xpath要 ...
- 爬虫学习之基于Scrapy的爬虫自动登录
###概述 在前面两篇(爬虫学习之基于Scrapy的网络爬虫和爬虫学习之简单的网络爬虫)文章中我们通过两个实际的案例,采用不同的方式进行了内容提取.我们对网络爬虫有了一个比较初级的认识,只要发起请求获 ...
- 爬虫学习之基于Scrapy的网络爬虫
###概述 在上一篇文章<爬虫学习之一个简单的网络爬虫>中我们对爬虫的概念有了一个初步的认识,并且通过Python的一些第三方库很方便的提取了我们想要的内容,但是通常面对工作当作复杂的需求 ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
随机推荐
- LetsTalk_Android中引导用户加入白名单图
--------------------------------
- 直播系统聊天技术(八):vivo直播系统中IM消息模块的架构实践
本文由vivo互联网技术团队LinDu.Li Guolin分享,有较多修订和改动. 1.引言 IM即时消息模块是直播系统的重要组成部分,一个稳定.有容错.灵活的.支持高并发的消息模块是影响直播系统用户 ...
- 使用ollama玩转本地大模型
使用ollama玩转本地大模型 https://ollama.com/download 安装 安装验证 测试 ollama run llama2 ollama run qwen
- JVM实战—9.线上FGC的几种案例
大纲 1.如何优化每秒十万QPS的社交APP的JVM性能(增加S区大小 + 优化内存碎片) 2.如何对垂直电商APP后台系统的FGC进行深度优化(定制JVM参数模版) 3.不合理设置JVM参数可能导致 ...
- linux 安装 Ollama 框架
概述 Ollama 是一款旨在简化大语言模型(LLM)本地部署的工具,支持 Windows.Linux 和 MacOS 系统.它提供了一个用户友好的环境,让开发者可以轻松地运行和调优如 Qwen.Ll ...
- OpenCL入门笔记
1.概述 1.1.OpenCL标准 OpenCL(Open Computing Language)是一个开放标准的并行编程框架,它允许开发者在异构系统上利用各种计算设备(例如CPU.GPU.FPGA等 ...
- winform 引用AForge调用摄像头拍照
Nuget安装这个2个: AForge.Controls; AForge.Video.DirectShow; code: namespace WindowsFormsApp1 { partial cl ...
- Websocket详细讲解
因为websocket的内容比较多,所以准备分解将基础篇主要讨论一下websocket的概念,websocket和http协议的区别,客户端的websocket以及服务端的websocket,中间穿插 ...
- Redis组件的特性,实现一个分布式限流
分布式---基于Redis进行接口IP限流 场景 为了防止我们的接口被人恶意访问,比如有人通过JMeter工具频繁访问我们的接口,导致接口响应变慢甚至崩溃,所以我们需要对一些特定的接口进行IP限流,即 ...
- cmake-4
cmake-4学习,参考 cmake构建c++项目快速入门2-1 cmake构建c++项目快速入门2-2 了解 cmake的工作原理: Windows下用cmake编译cmake (1)先下载cmak ...