SciTech-BigDataAIML-TensorFlow-Model模型的 建立与训练 与 Layer层的inputs/outputs参数可自适应训练建模(投入产出)
TensorFlow 模型建立与训练
TensorFlow 模型建立与训练
本章介绍如何使用 TensorFlow 快速搭建动态模型。
- 模型的构建: tf.keras.Model 和 tf.keras.layers
- 模型的损失函数: tf.keras.losses: cost成本(error误差)不止一种方式, 如diff=(y_true-y_pred), diff^2, abs(diff), ..., ,但总之是为更好的适用当前模型应用的当前场合。
- 模型的优化器: tf.keras.optimizer
- 模型的评估: tf.keras.metrics
前置知识
- Python -{zh-hant: 物件導向;zh-hans: 面向對象;}- 编程 :
- Python 定义 类和方法、类的继承、构造和析构函数,
- 使用 super () 函数调用父类方法 ,
- 使用__call__() 方法对实例进行调用 等);
- 多层感知机、卷积神经网络、循环神经网络和强化学习(每节之前给出参考资料)。
- Python 的函数装饰器 (非必须)
模型(Model)与层(Layer)
- 在 TensorFlow 中,推荐使用 Keras( tf.keras )构建模型。
Keras 是一个广为流行的高级神经网络 API,简单、快速而不失灵活性,现已得到 TensorFlow 的官方内置和全面支持。 - Keras 有两个重要的概念: 模型(Model) 和 层(Layer) 。
- 层将各种计算流程和变量进行了封装(例如基本的全连接层,CNN 的卷积层、池化层等),
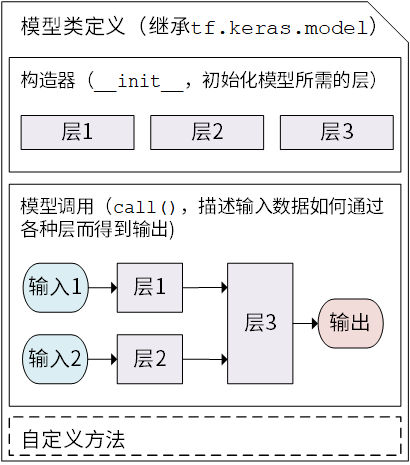
- 模型则将各种层进行组织和连接,并封装成一个整体,描述了如何将输入数据通过各种层以及运算而得到输出。
- 在需要模型调用的时候,使用
y_pred = model(X)的形式即可。 - Keras 在
tf.keras.layers下内置有深度学习用的大量常用的预定义层; - Keras同时也允许我们自定义层。
- Keras 模型以类的形式呈现,我们可以通过继承
tf.keras.Model这个Python 类来定义自己的模型。在继承类中,我们需要重写__init__()(构造函数,初始化)和call(input)(模型调用)两个方法,同时也可以根据需要增加自定义的方法.
class MyModel(tf.keras.Model):
def __init__(self):
super().__init__()
# Python 2 下使用 super(MyModel, self).__init__()
# 此处添加初始化代码(包含 call 方法中会用到的层),例如
# layer1 = tf.keras.layers.BuiltInLayer(...)
# layer2 = MyCustomLayer(...) def call(self, input):
# 此处添加模型调用的代码(处理输入并返回输出),例如
# x = layer1(input)
# output = layer2(x)
return output # 还可以添加 自定义的方法
- 继承 tf.keras.Model 后,我们同时可以使用父类的若干方法和属性,例如在实例化类
model = Model()后,可以通过model.variables这一属性直接获得模型的所有变量,免去我们一个个显式指定变量的麻烦。 - Keras 的 Model模型类 定义示意图:
![]()
上一章中简单的线性模型 y_pred = a * X + b ,我们可以通过模型类的方式编写如下:
import tensorflow as tf X = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
y = tf.constant([[10.0], [20.0]]) class Linear(tf.keras.Model):
def __init__(self):
super().__init__()
self.dense = tf.keras.layers.Dense(
units=1,
activation=None,
kernel_initializer=tf.zeros_initializer(),
bias_initializer=tf.zeros_initializer()
) def call(self, input):
output = self.dense(input)
return output # 以下代码结构与前节类似
model = Linear()
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
for i in range(100):
with tf.GradientTape() as tape:
y_pred = model(X)
# 调用模型 y_pred = model(X) 而不是显式写出 y_pred = a * X + b
loss = tf.reduce_mean(tf.square(y_pred - y))
grads = tape.gradient(loss, model.variables)
# 使用 model.variables 这一属性直接获得模型中的所有变量
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
print(model.variables)
这里,我们没有显式地声明 a 和 b 两个变量并写出 y_pred = a * X + b 这一线性变换,而是建立一个继承 tf.keras.Model 的模型类 Linear :
- 这个类在初始化部分实例化了一个 全连接层(
tf.keras.layers.Dense), - 在 call 方法中对这个层进行调用,实现线性变换的计算。
- 如果需要显式地声明自己的变量并使用变量进行自定义运算,或者希望了解 Keras 层的内部原理,请参考 自定义层。
Layer的“矩阵变换函数”与“投入产出自适应训练参数的建模”
数学角度,可将Layer视为“矩阵变换函数”,即将inputs张量 变换到 outputs张量;
为什么要以“数学”建模?:
数量值化:宏观的规律与策略,必须要与微观的度与量,有严谨的统一:
易于变换:inputs输入张量,outputs输出张量 都是数量值,通过数学变换函数;
无量纲化:数量许多时候"有量纲"即是"相对"、"现象"的,
而"无量纲"时是"绝对"与"本质规律"的; 无量纲 与 绝对(普遍适用) 的,本质与度量联系的,才会是可"模型"(通用规律化)的;
概率统计: Event -> Samples -> Population, Phenomenon->Measure->Nature实现角度,为“智能”的将inputs张量 变换到 outputs张量,
需要总结出kernel张量:
supervised: 用样本数据,自适应的预训练好参数,例如分类,
unsupervised: 直接由inputs提取 参数kernel,例如聚类,统一的
数据与过程建模:- 数据上,设立inputs/outputs数学建模:
inputs输入张量,outputs输出张量 都是数量值,
有目标的 投入产出效能建模,评估每一次的 目标值 与 真实值 之间的效能提升; - 过程上,epoches(一轮轮)的以一定的
调整策略``尝试改变参数, 通过outputs的变化量(真实值y_true与y_pred的变化量), 一步步的选取最优的参数。
- 数据上,设立inputs/outputs数学建模:
Loss(error) Function: 就是由 目标值 与 真实值 提取出 变参的效果度量数值 的函数:
例如:
abs_Loss_function = abs(y_pred - y_true),
mse_Loss_function = (y_pred - y_true)^2
...
事实上keras.metrics已经集成许多常用到的Loss Function:
[
[
keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError(),
],
[keras.metrics.CategoricalAccuracy()],
],
- Optimizer: 优化器是拿到 loss(error)后,进行“优化”的;
Layer 之 Dense(tf.keras.layers.Dense)全连接层:线性变换 + 激活函数
- Fully-connected Layer(
tf.keras.layers.Dense)是 Keras 中最基础和常用的层之一.
之所以叫"全连接层",是因为线性变换tf.matmul(input, kernel) + bias用的,
是"tf.matmul矩阵乘法", 将inputs张量视为行向量组(每个行向量都有input_dim列的特征维度), 将kernel视为列向量组(每个列向量都有input_dim行),则outputs张量的每一个元素都与inputs张量全部(input_dim维度数)的特征有"连接"。 Dense对输入矩阵A进行f(AW + b)的 线性变换 + 激活函数 操作。
如果不指定激活函数,即只进行线性变换AW + b。Dense的实现:
给定 输入张量input = [batch_size, input_dim],
首先进行tf.matmul(input, kernel) + bias的线性变换(kernel和bias是层中可训练的变量),
然后对线性变换后张量的每个元素通过激活函数activation,从而输出形状为[batch_size, units]的二维张量。
![]()
Dense包含的主要参数如下:units:输出张量的维度;activation:激活函数,
对应于f(AW + b)的f,默认为转发激活(即a(x) = x, 转发x)。
常用的有tf.nn.relu,tf.nn.tanh和tf.nn.sigmoid;use_bias:
是否加入偏置向量bias,即f(AW + b)的b. 默认为True;kernel_initializer、bias_initializer:
权重矩阵kernel和偏置向量bias两个变量的初始化器。
默认为tf.glorot_uniform_initializer.
Keras 的很多层都默认使用tf.glorot_uniform_initializer初始化变换。
设置为tf.zeros_initializer表示将两个变量均初始化为全0;
该层包含权重矩阵kernel = [input_dim, units]和偏置向量bias = [units]两个可训练变量,对应于f(AW + b)的W和b。
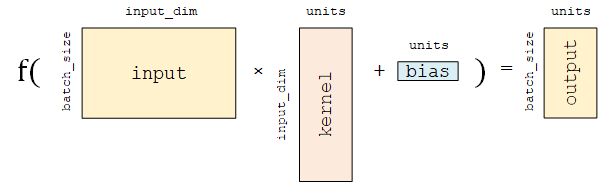
这里着重从数学矩阵运算和线性变换的角度描述Dense全连接层。
基于神经元建模的描述可参考 后文介绍 。
Keras 中的很多层都默认使用 tf.glorot_uniform_initializer 初始化变量,关于该初始化器可参考 https://www.tensorflow.org/api_docs/python/tf/glorot_uniform_initializer 。
你可能会注意到, tf.matmul(input, kernel) 的结果是一个形状为 [batch_size, units] 的二维矩阵,这个二维矩阵要如何与形状为 [units] 的一维偏置向量 bias 相加呢?事实上,这里是 TensorFlow 的 Broadcasting 机制在起作用,该加法运算相当于将二维矩阵的每一行加上了 Bias 。Broadcasting 机制的具体介绍可见 https://www.tensorflow.org/xla/broadcasting 。
为什么模型类是重载 call() 方法而不是 call() 方法?
在 Python 中,对类的实例 myClass 进行形如 myClass() 的调用等价于 myClass.call() (具体请见本章初 “前置知识” 的 call() 部分)。那么看起来,为了使用 y_pred = model(X) 的形式调用模型类,应该重写 call() 方法才对呀?原因是 Keras 在模型调用的前后还需要有一些自己的内部操作,所以暴露出一个专门用于重载的 call() 方法。 tf.keras.Model 这一父类已经包含 call() 的定义。 call() 中主要调用了 call() 方法,同时还需要在进行一些 keras 的内部操作。这里,我们通过继承 tf.keras.Model 并重载 call() 方法,即可在保持 keras 结构的同时加入模型调用的代码。
n 为分类任务的类别个数。
预测概率分布与真实分布越接近,则交叉熵的值越小,反之则越大。
更具体的介绍及其在机器学习中的应用可参考 这篇博客文章 。
在 tf.keras 中,有两个交叉熵相关的损失函数 tf.keras.losses.categorical_crossentropy 和 tf.keras.losses.sparse_categorical_crossentropy 。其中 sparse 的含义是,真实的标签值 y_true 可以直接传入 int 类型的标签类别。具体而言:
loss = tf.keras.losses.sparse_categorical_crossentropy(
y_true=y,
y_pred=y_pred)
与
loss = tf.keras.losses.categorical_crossentropy(
y_true=tf.one_hot(y, depth=tf.shape(y_pred)[-1]),
y_pred=y_pred)
的结果相同。
模型的评估: tf.keras.metrics
使用测试集评估模型的性能。
使用 tf.keras.metrics 的 SparseCategoricalAccuracy 评估器来评估模型在测试集上的性能:
该评估器能够对模型的"预测结果"与""真实结果"进行比较,并输出预测正确的样本数占总样本数的比例。
我们迭代测试数据集,每次通过 update_state() 方法向评估器输入两个参数: y_pred 和 y_true,即模型预测出的结果和真实结果。
评估器具有内部变量来保存当前评估指标相关的参数数值(例如当前已传入的累计样本数和当前预测正确的样本数)。
迭代结束后,我们使用 result() 方法输出最终的评估指标值(预测正确的样本数占总样本数的比例)。
以下代码,实例化一 tf.keras.metrics.SparseCategoricalAccuracy 评估器,
并使用 For 循环迭代分批次传入的测试集数据的预测结果与真实结果,
并输出训练后的模型在测试数据集上的准确率。
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
num_batches = int(data_loader.num_test_data // batch_size)
for batch_index in range(num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict(data_loader.test_data[start_index: end_index])
sparse_categorical_accuracy.update_state(y_true=data_loader.test_label[start_index: end_index], y_pred=y_pred)
print("test accuracy: %f" % sparse_categorical_accuracy.result())
输出结果:
test accuracy: 0.947900
可以注意到,使用这样简单的模型,已经可以达到 95% 左右的准确率。
SciTech-BigDataAIML-TensorFlow-Model模型的 建立与训练 与 Layer层的inputs/outputs参数可自适应训练建模(投入产出)的更多相关文章
- ChatGirl 一个基于 TensorFlow Seq2Seq 模型的聊天机器人[中文文档]
ChatGirl 一个基于 TensorFlow Seq2Seq 模型的聊天机器人[中文文档] 简介 简单地说就是该有的都有了,但是总体跑起来效果还不好. 还在开发中,它工作的效果还不好.但是你可以直 ...
- TensorFlow笔记-模型的保存,恢复,实现线性回归
模型的保存 tf.train.Saver(var_list=None,max_to_keep=5) •var_list:指定将要保存和还原的变量.它可以作为一个 dict或一个列表传递. •max_t ...
- Keras(一)Sequential与Model模型、Keras基本结构功能
keras介绍与基本的模型保存 思维导图 1.keras网络结构 2.keras网络配置 3.keras预处理功能 模型的节点信息提取 config = model.get_config() 把mod ...
- Python之TensorFlow的模型训练保存与加载-3
一.TensorFlow的模型保存和加载,使我们在训练和使用时的一种常用方式.我们把训练好的模型通过二次加载训练,或者独立加载模型训练.这基本上都是比较常用的方式. 二.模型的保存与加载类型有2种 1 ...
- django Model模型二及Model模型对数据库的操作
在django模型中负责与数据库交互的为Model层,Model层提供了一个基于orm的交互框架 一:创建一个最基本的Model from __future__ import unicode_lite ...
- TensorFlow-Bitcoin-Robot:一个基于 TensorFlow LSTM 模型的 Bitcoin 价格预测机器人
简介 TensorFlow-Bitcoin-Robot:一个基于 TensorFlow LSTM 模型的 Bitcoin 价格预测机器人. 文章包括一下几个部分: 1.为什么要尝试做这个项目? 2.为 ...
- keras系列︱Sequential与Model模型、keras基本结构功能(一)
引自:http://blog.csdn.net/sinat_26917383/article/details/72857454 中文文档:http://keras-cn.readthedocs.io/ ...
- 学习笔记TF053:循环神经网络,TensorFlow Model Zoo,强化学习,深度森林,深度学习艺术
循环神经网络.https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/re ...
- 『TensorFlow』模型保存和载入方法汇总
『TensorFlow』第七弹_保存&载入会话_霸王回马 一.TensorFlow常规模型加载方法 保存模型 tf.train.Saver()类,.save(sess, ckpt文件目录)方法 ...
- TensorFlow 自定义模型导出:将 .ckpt 格式转化为 .pb 格式
本文承接上文 TensorFlow-slim 训练 CNN 分类模型(续),阐述通过 tf.contrib.slim 的函数 slim.learning.train 训练的模型,怎么通过人为的加入数据 ...
随机推荐
- Weblogic远程代码执行CVE-2023-21839复现及修复
声明:本文分享的安全工具和项目均来源于网络,仅供安全研究与学习之用, 如用于其他用途,由使用者承担全部法律及连带责任,与工具作者和本公众号无关. WebLogic 存在远程代码执行漏洞(CVE ...
- python-docx 设置表格边框
# -*- coding: utf-8 -*- """ Created on Sat Oct 24 17:21:31 2020 pip install -i https: ...
- python 处理word 分页符、分节符
import docx doc1 =docx.Document(r"C:\Users\Administrator\Desktop\test.docx") doc1.paragrap ...
- 探秘Transformer系列之(31)--- Medusa
探秘Transformer系列之(31)--- Medusa 目录 探秘Transformer系列之(31)--- Medusa 0x00 概述 0x01 原理 1.1 动机 1.2 借鉴 1.3 思 ...
- mysql8.0.16 设置远程主机访问
新版的的mysql版本已经将创建账户和赋予权限的方式分开了 1.创建账户 create user 'root'@'%' identified by '123456'; 注意密码是否符合要求,我用的阿里 ...
- django实例(1)
Urls.py from django.contrib import adminfrom django.conf.urls import urlfrom cmdb import viewsurlpat ...
- 自实现模态对话框-DoModal函数
参考CDialog::DoModal函数的实现方式,自己实现了模态框相关功能. ModalBase.h头文件 1 #include <afxwin.h> 2 3 #define ID_NU ...
- 【工程应用十】 基于Hessian矩阵的Frangi滤波算法 == 血管图像增强 == Matlab中fibermetric函数的自我实现、加速和优化。
前几天在翻一翻matlab中的帮助文档,无意中发现一个叫fibermetric的图像处理函数,感觉有点意思,可以增强或者说突出一些类似于管状的对象,后面看了下算法的帮助文档,在百度上找了找,原来这也是 ...
- 全网资源无水印下载!支持抖音、视频号、小红书等,Rubik下载介绍
在日常生活和工作中,我们经常要用到一些优质的影音或图片素材,然而,随着各种平台的限制越来越多,不是需要付费订阅后才能下载,就是完全不提供下载渠道,想要找到一个广泛又好用的下载工具变得格外困难 Rubi ...
- TVM VLOG打印
TVM 提供了详细日志记录功能,允许提交跟踪级别的调试消息,而不会影响生产中 TVM 的二进制大小或运行时.你可以在你的代码中使用 VLOG 如下: void Foo(const std::strin ...