configure HDFS(hadoop 分布式文件系统) high available
注:来自尚学堂小陈老师上课笔记
1.安装启动zookeeper
a)上传解压zookeeper包
b)cp zoo_sample.cfg zoo.cfg修改zoo.cfg文件
c)dataDir=/opt/data/zookeeper
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
这里的node1是自己主机名,可以写ip
d)分别在node1 node2 node3 的数据目录/opt/data/zookeeper下面创建myid文件,里面写对应server.后面的数字
e)配置环境变量并source生效
export ZK_HOME=/opt/soft/zookeeper-3.4.6
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZK_HOME/bin
f)启动 zkServer.sh start启动,隔一分钟,通过zkServer.sh status查看状态
2.配置hadoop配置文件
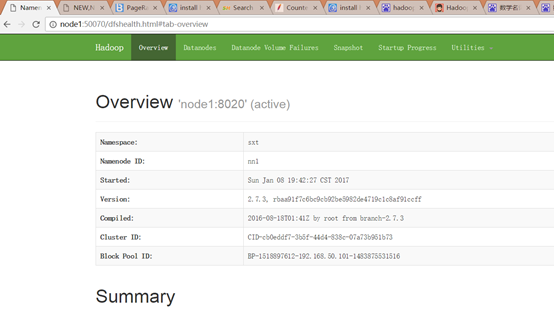
配置hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>sxt</value>
</property>
<property>
<name>dfs.ha.namenodes.sxt</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.sxt.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.sxt.nn2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.sxt.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.sxt.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/sxt</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.sxt</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
配置core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://sxt</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/journal</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
3.启动所有journalnode
hadoop-daemon.sh start journalnode
4.其中一个namenode节点执行格式化
hdfs namenode -format
5.另外一个namenode节点格式化拷贝
首先要将刚才格式化之后的namenode启动起来
hadoop-daemon.sh start namenode
hdfs namenode -bootstrapStandby
6.上传配置到zookeeper集群
hdfs zkfc -formatZK
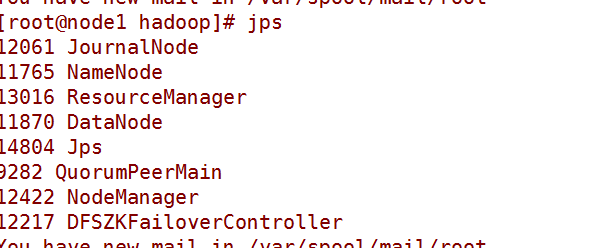
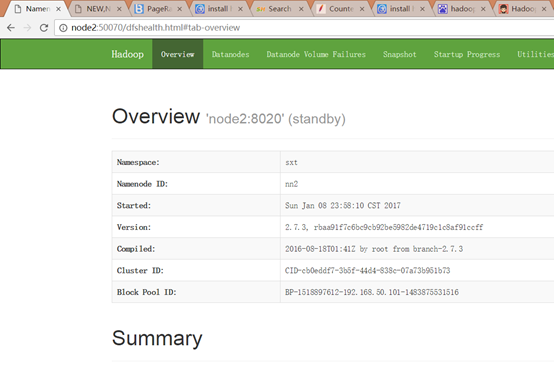
7.启动
先stop-dfs.sh
然后start-dfs.sh
hadoop-daemon.sh start namenode


configure HDFS(hadoop 分布式文件系统) high available的更多相关文章
- Hadoop分布式文件系统HDFS详解
Hadoop分布式文件系统即Hadoop Distributed FileSystem. 当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区(Partition)并 ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
- HDFS(Hadoop Distributed File System )hadoop分布式文件系统。
HDFS(Hadoop Distributed File System )hadoop分布式文件系统.HDFS有如下特点:保存多个副本,且提供容错机制,副本丢失或宕机自动恢复.默认存3份.运行在廉价的 ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- 对Hadoop分布式文件系统HDFS的操作实践
原文地址:https://dblab.xmu.edu.cn/blog/290-2/ Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop核 ...
- Hadoop分布式文件系统(HDFS)设计
Hadoop分布式文件系统是设计初衷是可靠的存储大数据集,并且使应用程序高带宽的流式处理存储的大数据集.在一个成千个server的大集群中,每个server不仅要管理存储的这些数据,而且可以执行应用程 ...
- Hadoop 分布式文件系统:架构和设计
引言 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点.但同时,它和其他的分布式文件系统 ...
- 【官方文档】Hadoop分布式文件系统:架构和设计
http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html 引言 前提和设计目标 硬件错误 流式数据访问 大规模数据集 简单的一致性模型 “移动计 ...
- 在Hadoop分布式文件系统的索引和搜索
FROM:http://www.drdobbs.com/parallel/indexing-and-searching-on-a-hadoop-distr/226300241?pgno=3 在今天的信 ...
随机推荐
- NFC高级
高级 NFC 本文档介绍了高级的NFC主题,如各种标签技术,NFC标签写入和前台发布,它允许即使当其他应用程序过滤器相同的时候,应用程序在前台处理Intent. Tag技术支持工作 当使NFC Tag ...
- screen获取屏幕信息
<script type="text/javascript" language="javascript"> document.write(" ...
- GridView中两个DropDownList联动
GridView中两个DropDownList联动 http://www.cnblogs.com/qfb620/archive/2011/05/25/2057163.html Html: <as ...
- MVC 5 - 查询Details和Delete方法
MVC 5 - 查询Details和Delete方法 在这部分教程中,接下来我们将讨论自动生成的Details和Delete方法. 查询Details和Delete方法 打开Movie控制器并查看De ...
- 【转】jQuery each函数中的continue及break
continue :return true; break :return false; 也可以利用return即可跳出jQuery 来源:http://bie.xiaowangge.info/brow ...
- 移动tempdb导致数据库服务不能启动
事情的起因是因为数据库的IO操作过大,于是新加了个硬盘,发现在执行写入操作的时候,服务器的压力依然是比较大的,于是想到了内存盘.内存盘是"魔方"系统优化提供的一个小工具,就是将内存 ...
- let和const关键词
ECMAScript 6中的let和const关键词 2013-11-28 21:46 by BarretLee, 21 阅读, 0 评论, 收藏, 编辑 ECMAScript 6中多了两个定义变量的 ...
- [转]Debugging the Mac OS X kernel with VMware and GDB
Source: http://ho.ax/posts/2012/02/debugging-the-mac-os-x-kernel-with-vmware-and-gdb/ Source: http:/ ...
- JavaScript 跨域方法总结
同源策略 在客户端编程语言中,如javascript和 ActionScript,同源策略是一个很重要的安全理念,它在保证数据的安全性方面有着重要的意义.同源策略规定跨域之间的脚本是隔离的,一个域的脚 ...
- Unable to start activity异常的解决方案
当时我正在测试一个用户身份验证组件.使用的是android内置的Accounts API.当时的情况是,需要在App2中调用App1的用户身份验证组件,但是不知道为什么登入界面总是无法正常开启.后来我 ...