configure HDFS(hadoop 分布式文件系统) high available
注:来自尚学堂小陈老师上课笔记
1.安装启动zookeeper
a)上传解压zookeeper包
b)cp zoo_sample.cfg zoo.cfg修改zoo.cfg文件
c)dataDir=/opt/data/zookeeper
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
这里的node1是自己主机名,可以写ip
d)分别在node1 node2 node3 的数据目录/opt/data/zookeeper下面创建myid文件,里面写对应server.后面的数字
e)配置环境变量并source生效
export ZK_HOME=/opt/soft/zookeeper-3.4.6
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZK_HOME/bin
f)启动 zkServer.sh start启动,隔一分钟,通过zkServer.sh status查看状态
2.配置hadoop配置文件
配置hdfs-site.xml
<property>
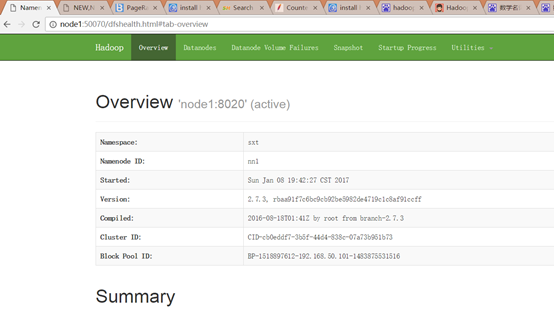
<name>dfs.nameservices</name>
<value>sxt</value>
</property>
<property>
<name>dfs.ha.namenodes.sxt</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.sxt.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.sxt.nn2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.sxt.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.sxt.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/sxt</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.sxt</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
配置core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://sxt</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/journal</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
3.启动所有journalnode
hadoop-daemon.sh start journalnode
4.其中一个namenode节点执行格式化
hdfs namenode -format
5.另外一个namenode节点格式化拷贝
首先要将刚才格式化之后的namenode启动起来
hadoop-daemon.sh start namenode
hdfs namenode -bootstrapStandby
6.上传配置到zookeeper集群
hdfs zkfc -formatZK
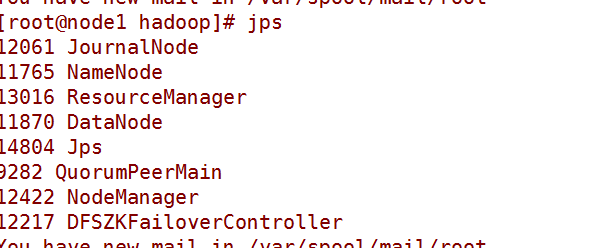
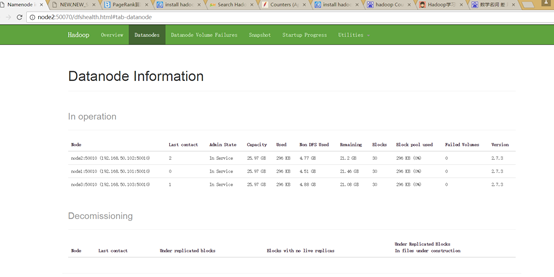
7.启动
先stop-dfs.sh
然后start-dfs.sh
hadoop-daemon.sh start namenode


configure HDFS(hadoop 分布式文件系统) high available的更多相关文章
- Hadoop分布式文件系统HDFS详解
Hadoop分布式文件系统即Hadoop Distributed FileSystem. 当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区(Partition)并 ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
- HDFS(Hadoop Distributed File System )hadoop分布式文件系统。
HDFS(Hadoop Distributed File System )hadoop分布式文件系统.HDFS有如下特点:保存多个副本,且提供容错机制,副本丢失或宕机自动恢复.默认存3份.运行在廉价的 ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- 对Hadoop分布式文件系统HDFS的操作实践
原文地址:https://dblab.xmu.edu.cn/blog/290-2/ Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop核 ...
- Hadoop分布式文件系统(HDFS)设计
Hadoop分布式文件系统是设计初衷是可靠的存储大数据集,并且使应用程序高带宽的流式处理存储的大数据集.在一个成千个server的大集群中,每个server不仅要管理存储的这些数据,而且可以执行应用程 ...
- Hadoop 分布式文件系统:架构和设计
引言 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点.但同时,它和其他的分布式文件系统 ...
- 【官方文档】Hadoop分布式文件系统:架构和设计
http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html 引言 前提和设计目标 硬件错误 流式数据访问 大规模数据集 简单的一致性模型 “移动计 ...
- 在Hadoop分布式文件系统的索引和搜索
FROM:http://www.drdobbs.com/parallel/indexing-and-searching-on-a-hadoop-distr/226300241?pgno=3 在今天的信 ...
随机推荐
- linux服务创建及jq配置服务列表查看
1.应用背景 随着业务需求,后台处理服务不断增多,对于这些服务或后台程序的查看.更新操作越来越凌乱,所以我们首先需要一个服务列表查看工具,方便查看各 服务的端口.运行状态.jar包路径等等. 2.创建 ...
- asp.net MVC2.0学习笔记
asp.net;与mvc都是不可替代的:只是多一种选择:(解决了许多asp.net的许多缺点) model:充血模型.领域模型:很大程度的封装: 控制器:处理用户的交互,处理业务逻辑的调用,指定具体的 ...
- status状态栏实现字符串走动
<script type="text/javascript" language="javascript"> var i = 0; var str=& ...
- go orcale
golang连接orcale 使用glang有一段时间了,最开始其实并不太喜欢他的语法,但是后来熟悉之后发现用起来还挺爽的.之前数据库一直使用mysql,连接起来没有什么问题,github上有很多 ...
- 后台XML处理
public void GetInfo() { string message = @"<?xml version='1.0' encoding='utf-8' ...
- 图解 ENGLISH
人在江湖,总得会几门手艺,英语必不可缺,下面几张图诠释了什么叫强大:
- AHOI1997彩旗飘飘 VIJOS1097合并果子(noip2007)
AHOI彩旗飘飘 这是一题类似于排列组合的题目吧...递推状态 数组f[100][100][100][2];表示红旗数目,黄旗数目,颜色改变的次数,末尾的旗的颜色(0为黄,1为红) 之后就是如何写递推 ...
- 类图class的关联关系(聚合、组合)
类图class的关联关系(聚合.组合) 关联的概念 关联用来表示两个或多个类的对象之间的结构关系,它在代码中表现为一个类以属性的形式包含对另一个类的一个或多个对象的应用. 程序演示:关联关系(code ...
- [笔记] OS X and iOS 内核开发
一.KEXT包的安全性说明 KEXT 程序包及其包含的所有文件及文件夹必须属于 root 用户(用户 id 是 0) KEXT 程序包及其包含的所有文件及文件夹必须属于 wheel 组(组 id 是 ...
- ios学习之category设计模式
之前看书的时候,没怎么注意,但在项目中,才发现它的特别之处. 先来看看他用途:官网大意是这样写的:当你想简单的向一个已知类添加一个方法的时候,你就可以使用它.使用它的时候,命名是有要求的,如下: @i ...