SQL Server数据库的三种恢复模式:简单恢复模式、完整恢复模式和大容量日志恢复模式(转载)
SQL Server数据库有三种恢复模式:简单恢复模式、完整恢复模式和大容量日志恢复模式:
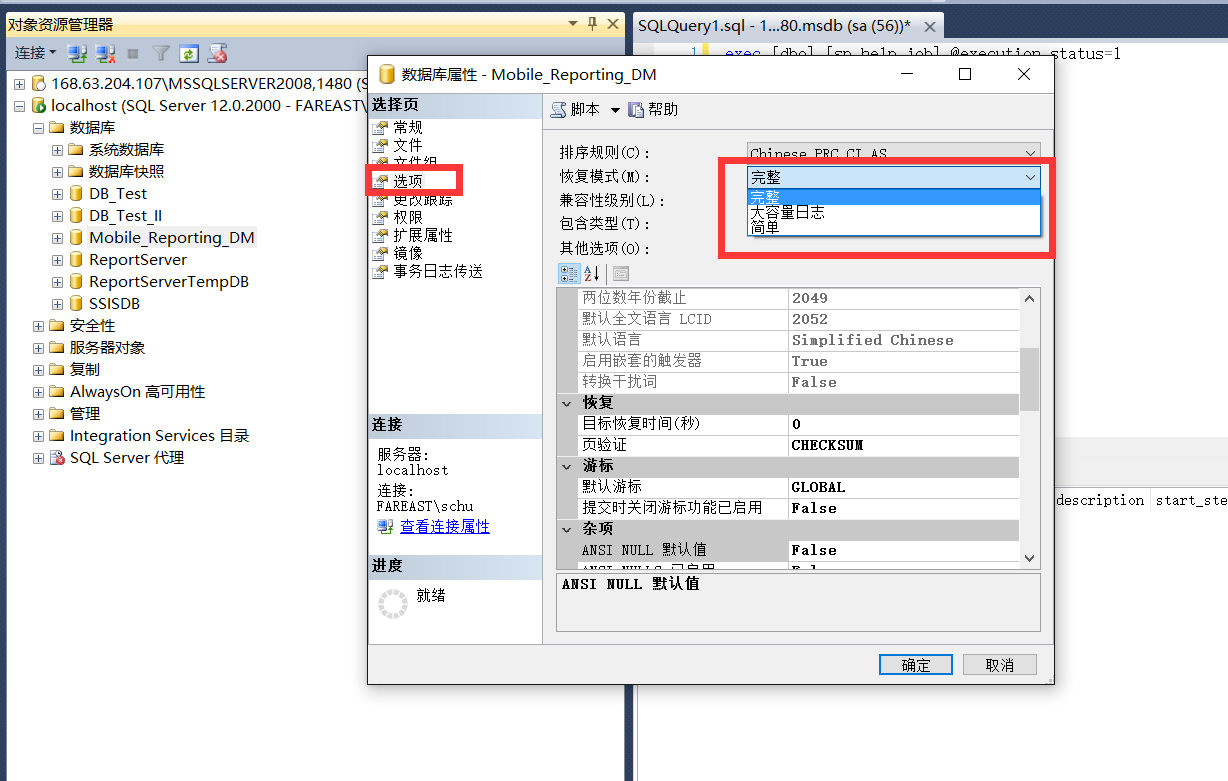
1.Simple 简单恢复模式,
Simple模式的旧称叫”Checkpoint with truncate log“,其实这个名字更形象,在Simple模式下,SQL Server会在每次checkpoint或backup之后自动截断log,也就是丢弃所有的inactive log records,仅保留用于实例启动时自动发生的instance recovery所需的少量log,这样做的好处是log文件非常小,不需要DBA去维护、备份log,但坏处也是显而易见的,就是一旦数据库出现异常,需要恢复时,最多只能恢复到上一次的备份,无法恢复到最近可用状态,因为log丢失了。 Simple模式主要用于非critical的业务,比如开发库和测试库,但是道富这边的SQL Server(即使是生产库)大都采用Simple模式,是因为这边的SQL Server大都用于非critical的业务(critical的数据库大都采用Oracle和DB2),可以忍受少于1天的数据丢失(我们的job每天都会定时备份全库)。
如果需要压缩数据库日志(Shrink语句),将数据库模式切换到简单恢复模式后压缩率才是最高的,如果你的数据库在完整恢复模式或大容量日志回复模式下采用日志压缩,压缩后的日志大小并不会很理想。
2.Full 完整恢复模式,
和Simple模式相反,Full模式的旧称叫”Checkpoint without truncate log“,也就是SQL Server不主动截断log,只有备份log之后,才可以截断log,否则log文件会一直增大,直到撑爆硬盘,因此需要部署一个job定时备份log。Full的好处是可以做point-in-time恢复,最大限度的保证数据不丢失,一般用于critical的业务环境里。缺点就是DBA需要维护log,增加人员成本(其实也就是多了定时备份log这项工作而已)。
3.Bulk-logged 大容量日志恢复
Bulk-logged模式和full模式类似,唯一的不同是针对以下Bulk操作,会产生尽量少的log: 1) Bulk load operations (bcp and BULK INSERT). 2) SELECT INTO. 3) Create/drop/rebuild index 众所周知,通常bulk操作会产生大量的log,对SQL Server的性能有较大影响,bulk-logged模式的作用就在于降低这种性能影响,并防止log文件过分增长,但是它的问题是无法point-in-time恢复到包含bulk-logged record的这段时间。 Bulk-logged模式的最佳实践方案是在做bulk操作之前切换到bulk-logged,在bulk操作结束之后马上切换回full模式。
SQL Server数据库的三种恢复模式:简单恢复模式、完整恢复模式和大容量日志恢复模式(转载)的更多相关文章
- SQL Server中的三种Join方式
1.测试数据准备 参考:Sql Server中的表访问方式Table Scan, Index Scan, Index Seek 这篇博客中的实验数据准备.这两篇博客使用了相同的实验数据. 2.SQ ...
- C# 连接SQL Server数据库的几种方式--server+data source等方式
如何使用Connection对象连接数据库? 对于不同的.NET数据提供者,ADO.NET采用不同的Connection对象连接数据库.这些Connection对象为我们屏蔽了具体的实现细节,并提供了 ...
- 修改SQL Server数据库表的创建时间最简单最直接有效的方法
说明:这篇文章是几年前我发布在网易博客当中的原创文章,但由于网易博客现在要停止运营了,所以我就把这篇文章搬了过来,因为这种操作方式是通用的,即使是对现在最新的SQL Server数据库里面的操作也是一 ...
- 浅谈SQL Server中的三种物理连接操作
简介 在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge J ...
- SQL Server中的三种物理连接操作
来源:https://msdn.microsoft.com/zh-cn/library/dn144699.aspx 简介 在SQL Server中,我们所常见的表与表之间的Inner Join,Out ...
- 浅谈SQL Server中的三种物理连接操作(HASH JOIN MERGE JOIN NESTED LOOP)
简介 在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge J ...
- 浅谈SQL Server中的三种物理连接操作(Nested Loop Join、Merge Join、Hash Join)
简介 在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge J ...
- 收缩SQL Server 数据库的几种方法
方法一: Use 数据库名 Select NAME,size From sys.database_files ALTER DATABASE 数据库名 SET RECOVERY SIMPLE WITH ...
- SQL SERVER 2008 中三种分页方法与总结
建立表: CREATE TABLE [TestTable] ( , ) NOT NULL , ) COLLATE Chinese_PRC_CI_AS NULL , ) COLLATE Chinese_ ...
随机推荐
- webKit和chromium的文章地址
http://blog.csdn.net/column/details/yongsheng.html?&page=1
- 运用SET ANSI_PADDING OFF创建某个字段为自增列的表,以及插入数据
SET ANSI_PADDING OFFGOPRINT 'Testing with ANSI_PADDING OFF'GO CREATE TABLE WebsitesPaddingOFF (id in ...
- Given a binary tree containing digits from0-9only, each root-to-leaf path could represent a number. An example is the root-to-leaf path1->2->3which represents the number123. Find the total sum of a
class TreeNode { int val; TreeNode left; TreeNode right; TreeNode(int x) { val = x; } } public class ...
- 人脸pts文件检查及人脸框输出
function output() outtxt = fopen('D:\AR database\kz.txt','wt'); : imgpath= strcat('D:\AR database\kz ...
- Python-S13作业-day5-之 ATM
Python-S13作业-day5-之 ATM 需求: 模拟实现一个ATM + 购物商城程序 额度 15000或自定义 实现购物商城,买东西加入 购物车,调用信用卡接口结账 其实是两 ...
- JQuery:JQuery语法、选择器、事件处理
JQuery语法: 通过 jQuery,您可以选取(查询,query) HTML 元素,并对它们执行"操作"(actions). 一.语法:jQuery 语法是通过选取 HTM ...
- gpt
gpt 这里sdb是大于2T的那个VD,具体到您的机器,可以先在parted命令中先用list命令列出磁盘,然后用mklabel gpt来转换,具体如下: (parted) select /dev/s ...
- nginx端口被占用解决方案
killall -9 nginx或service nginx restart(重新启动)
- centOS中wget的使用方法
对于 Linux 用户来说,几乎每天都在使用它. 下面为大家介绍几个有用的 CentOS wget 小技巧,可以让你更加高效而灵活的使用CentOS wget. CentOS wget 使用技巧 $ ...
- Java native关键字
在String类中 public native String intern(); native关键字是干嘛的? Java不是完美的,Java的不足除了体现在运行速度上要比传统的C++慢许多之外,Jav ...