scrapy爬取youtube游戏模块
本次使用mac进行爬虫 mac爬虫安装过程中出现诸多问题
避免日后踩坑这里先进行记录
首先要下载xcode ,所以要更新macOS到10.14.xx版本
更新完之后因为等下要进行环境路径配置 但是macOS升级到高级版本之后自带了一个自我保护的功能
因此需要重启电脑然后按cmd+r 进入编辑模式 然后选择语言 粘贴下面的命令后,按回车,输入你的系统密码;
sudo spctl --master-disable
然后取消后重启就可以了 然后下载xcode 下载完重启
接下来下载下载神器 https://brew.sh/index_zh-cn.html
下载安装后提示
Warning: Homebrew's sbin was not found in your PATH but you have installed formulae that put executables in /usr/local/sbin.Consider setting the PATH for example like so
就是说这个homebrew虽然安装了 但是不在路径中 因此需要配置路径 刚刚已经把安全模式取消 现在要去更改下路径环境
Mac配置环境变量的地方
1./etc/profile (建议不修改这个文件 )
全局(公有)配置,不管是哪个用户,登录时都会读取该文件。
2./etc/bashrc (一般在这个文件中添加系统级环境变量)
全局(公有)配置,bash shell执行时,不管是何种方式,都会读取此文件。
3.~/.bash_profile (一般在这个文件中添加用户级环境变量)
每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该文件仅仅执行一次!
这里选择~/.bash_profile
sudo vim ~/.bash_profile
然后输入电脑密码进入
export PATH="/usr/local/bin:$PATH"
修改完后按esc 然后输入wq:! 回车 (:wq! 强制保存文件,并退出vi)
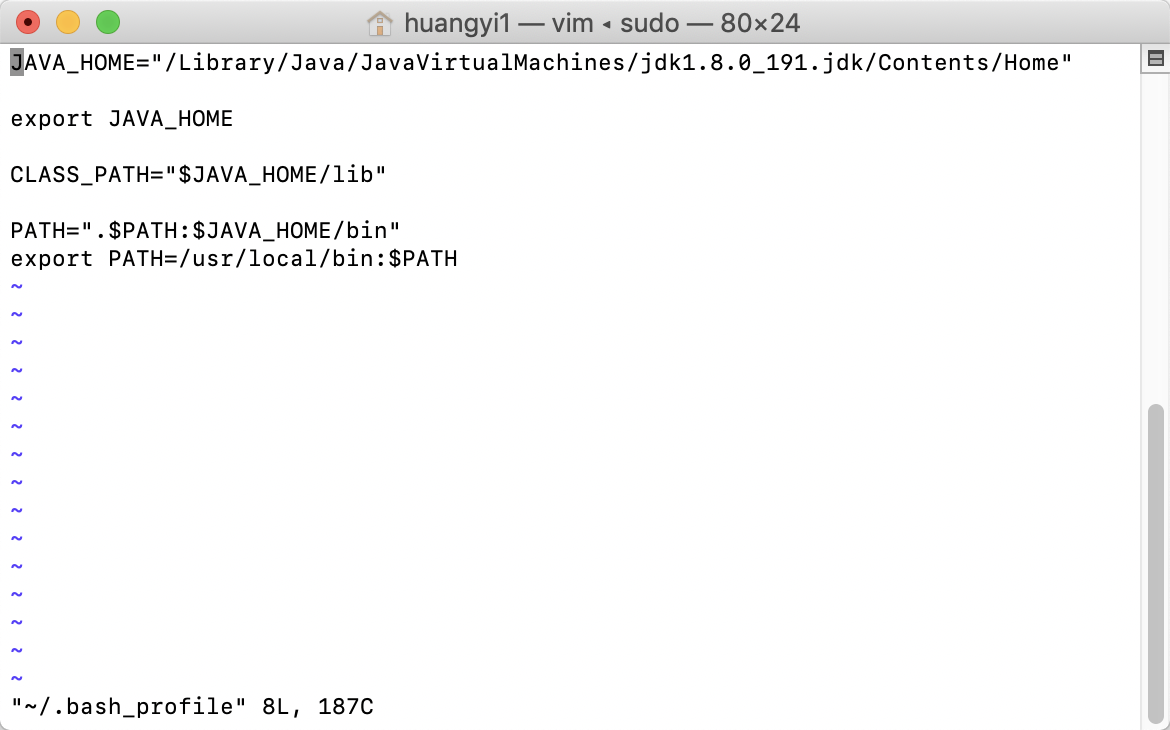
然后终端输入 $source ~/.bash_profile 进行刷新
sudo python get-pip.py
sudo pip install Scrapy
如果安装成功则输入 scrapy --verison 查看版本
本次内容是热门直播游戏、推荐、热门直播、work to game、时下流行视频。
热门直播游戏
Live-broadcast-id = 游戏直播名称
live-viewers-count = 游戏观看人数
推荐
video-title = 推荐视频名称
byline = 推荐游戏类别
热门直播
hot-img = 热门直播图片
hot-video-title = 热门视频名称
hot-byline = 热门游戏类别
hot-metadata = 观看人数
hot-button = 热门下一页
work to game
work-thumbnail = work展示图片
work-video-title = work视频名称
work-metadata-line = work观看人数
work-ytd-grid-video-renderer = work视频日期
p.p1 { margin: 0; font: 11px Menlo; color: rgba(0, 0, 0, 1) }
span.s1 { font-variant-ligatures: no-common-ligatures }
scrapy爬取youtube游戏模块的更多相关文章
- nodejs爬虫笔记(三)---爬取YouTube网站上的视频信息
思路:通过笔记(二)中代理的设置,已经可以对YouTube的信息进行爬取了,这几天想着爬取网站下的视频信息.通过分析YouTube,发现可以从订阅号入手,先选择几个订阅号,然后爬取订阅号里面的视频分类 ...
- Scrapy爬取美女图片第三集 代理ip(上) (原创)
首先说一声,让大家久等了.本来打算那天进行更新的,可是一细想,也只有我这样的单身狗还在做科研,大家可能没心思看更新的文章,所以就拖到了今天.不过忙了521,522这一天半,我把数据库也添加进来了,修复 ...
- Scrapy爬取美女图片续集 (原创)
上一篇咱们讲解了Scrapy的工作机制和如何使用Scrapy爬取美女图片,而今天接着讲解Scrapy爬取美女图片,不过采取了不同的方式和代码实现,对Scrapy的功能进行更深入的运用.(我的新书< ...
- scrapy爬取海量数据并保存在MongoDB和MySQL数据库中
前言 一般我们都会将数据爬取下来保存在临时文件或者控制台直接输出,但对于超大规模数据的快速读写,高并发场景的访问,用数据库管理无疑是不二之选.首先简单描述一下MySQL和MongoDB的区别:MySQ ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- scrapy爬取极客学院全部课程
# -*- coding: utf-8 -*- # scrapy爬取极客学院全部课程 import scrapy from pyquery import PyQuery as pq from jike ...
随机推荐
- Linuxqq shell脚本安装后的卸载
官方下载和帮助页面: 传送门 linuxqq_2.0.0-b1 的时候,并没有发布 MIPS64 的 DEB 包,只能用 .sh 安装,需要手动删除卸载.愚人节发布的 beta2 新增了 MIPS64 ...
- C# 反射调用拓展类方法
今天封装Protobuf封包时候遇到一个问题: Protobuf的反序列化方法MergeFrom,是写在扩展类里的:c#拓展类 通过反射获取不到这个方法,就没法使用Type来泛型封装... 然而仔细一 ...
- 嵌入式硬件之ADC/DAC
嵌入式硬件之ADC/DAC 写在前面 这几天在做一个寒假练项目,其中涉及到了音频的处理,ADC.DAC再次进入到了我的视野,并引起了我新的思考. 1.初次相识 记得去年七月份,本科毕业刚离校,就到研究 ...
- 集合框架-HashSet集合(无序唯一)
1 package cn.itcast.p4.hashset.demo; 2 3 import java.util.HashSet; 4 import java.util.Iterator; 5 /* ...
- 集合框架-工具类-Collections-逆序替换
1 package cn.itcast.p2.toolclass.collections.demo; 2 3 import java.util.ArrayList; 4 import java.uti ...
- Python如何把八进制转换成ASCII码
做题途中拿到一串八进制字符串 0126 062 0126 0163 0142 0103 0102 0153 0142 062 065 0154 0111 0121 0157 0113 0111 010 ...
- 搭建BBS博客系统
目录 一:搭建BBS项目 1.部署数据库 2.启动数据库 3.进入数据库 4.远程连接MySQL数据 5.pycham连接Mysql 二:开始部署BBS 1.上传代码 2.数据库迁移 3.删除文件 4 ...
- Win11怎么启动任务管理器?Win11启动任务管理器的四种方法
Win11怎么启动任务管理器?小编为大家带来了Win11启动任务管理器的四种方法,感兴趣的朋友一起看看吧 任务管理器是Windows系统中一项非常实用的功能.不过在最新版Win11中,右击任务栏启动任 ...
- C# 实例解释面向对象编程中的单一功能原则
在面向对象编程中,SOLID 是五个设计原则的首字母缩写,旨在使软件设计更易于理解.灵活和可维护.这些原则是由美国软件工程师和讲师罗伯特·C·马丁(Robert Cecil Martin)提出的许多原 ...
- STL priority_queue 优先队列 小记
今天做题发现一个很有趣的地方,竟然还是头一次发现,唉,还是太菜了. 做图论用STL里的priority_queue去优化prim,由于特殊需求,我需要记录生成树中是用的哪些边. 于是,我定义的优先队列 ...