scrapy爬取youtube游戏模块
本次使用mac进行爬虫 mac爬虫安装过程中出现诸多问题
避免日后踩坑这里先进行记录
首先要下载xcode ,所以要更新macOS到10.14.xx版本
更新完之后因为等下要进行环境路径配置 但是macOS升级到高级版本之后自带了一个自我保护的功能
因此需要重启电脑然后按cmd+r 进入编辑模式 然后选择语言 粘贴下面的命令后,按回车,输入你的系统密码;
sudo spctl --master-disable
然后取消后重启就可以了 然后下载xcode 下载完重启
接下来下载下载神器 https://brew.sh/index_zh-cn.html
下载安装后提示
Warning: Homebrew's sbin was not found in your PATH but you have installed formulae that put executables in /usr/local/sbin.Consider setting the PATH for example like so
就是说这个homebrew虽然安装了 但是不在路径中 因此需要配置路径 刚刚已经把安全模式取消 现在要去更改下路径环境
Mac配置环境变量的地方
1./etc/profile (建议不修改这个文件 )
全局(公有)配置,不管是哪个用户,登录时都会读取该文件。
2./etc/bashrc (一般在这个文件中添加系统级环境变量)
全局(公有)配置,bash shell执行时,不管是何种方式,都会读取此文件。
3.~/.bash_profile (一般在这个文件中添加用户级环境变量)
每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该文件仅仅执行一次!
这里选择~/.bash_profile
sudo vim ~/.bash_profile
然后输入电脑密码进入
export PATH="/usr/local/bin:$PATH"
修改完后按esc 然后输入wq:! 回车 (:wq! 强制保存文件,并退出vi)
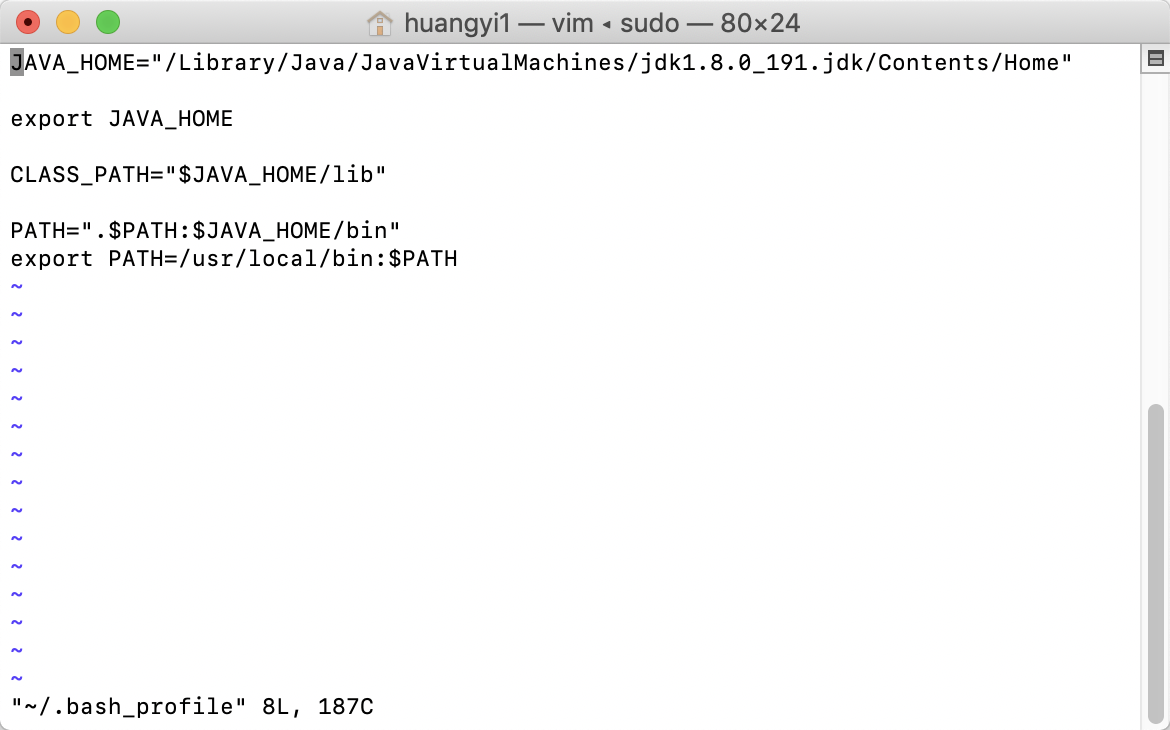
然后终端输入 $source ~/.bash_profile 进行刷新
sudo python get-pip.py
sudo pip install Scrapy
如果安装成功则输入 scrapy --verison 查看版本
本次内容是热门直播游戏、推荐、热门直播、work to game、时下流行视频。
热门直播游戏
Live-broadcast-id = 游戏直播名称
live-viewers-count = 游戏观看人数
推荐
video-title = 推荐视频名称
byline = 推荐游戏类别
热门直播
hot-img = 热门直播图片
hot-video-title = 热门视频名称
hot-byline = 热门游戏类别
hot-metadata = 观看人数
hot-button = 热门下一页
work to game
work-thumbnail = work展示图片
work-video-title = work视频名称
work-metadata-line = work观看人数
work-ytd-grid-video-renderer = work视频日期
p.p1 { margin: 0; font: 11px Menlo; color: rgba(0, 0, 0, 1) }
span.s1 { font-variant-ligatures: no-common-ligatures }
scrapy爬取youtube游戏模块的更多相关文章
- nodejs爬虫笔记(三)---爬取YouTube网站上的视频信息
思路:通过笔记(二)中代理的设置,已经可以对YouTube的信息进行爬取了,这几天想着爬取网站下的视频信息.通过分析YouTube,发现可以从订阅号入手,先选择几个订阅号,然后爬取订阅号里面的视频分类 ...
- Scrapy爬取美女图片第三集 代理ip(上) (原创)
首先说一声,让大家久等了.本来打算那天进行更新的,可是一细想,也只有我这样的单身狗还在做科研,大家可能没心思看更新的文章,所以就拖到了今天.不过忙了521,522这一天半,我把数据库也添加进来了,修复 ...
- Scrapy爬取美女图片续集 (原创)
上一篇咱们讲解了Scrapy的工作机制和如何使用Scrapy爬取美女图片,而今天接着讲解Scrapy爬取美女图片,不过采取了不同的方式和代码实现,对Scrapy的功能进行更深入的运用.(我的新书< ...
- scrapy爬取海量数据并保存在MongoDB和MySQL数据库中
前言 一般我们都会将数据爬取下来保存在临时文件或者控制台直接输出,但对于超大规模数据的快速读写,高并发场景的访问,用数据库管理无疑是不二之选.首先简单描述一下MySQL和MongoDB的区别:MySQ ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- scrapy爬取极客学院全部课程
# -*- coding: utf-8 -*- # scrapy爬取极客学院全部课程 import scrapy from pyquery import PyQuery as pq from jike ...
随机推荐
- rocketmq学习之-基本样例
1 基本样例 在基本样例中我们提供如下的功能场景: 使用RocketMQ发送三种类型的消息:同步消息.异步消息和单向消息.其中前两种消息是可靠的,因为会有发送是否成功的应答. 使用RocketMQ来消 ...
- 5.12-jsp分页功能学习
1.分页功能相关资料查询 分页须知知识点: (1)JDBC2.0的可滚动结果集. (2)HTTP GET请求. 一.可滚动结果集 Connection con = DriverManager.g ...
- 44.Prim算法
public static void main(String[] args) { //测试看看图是否创建ok char[] data = new char[]{'A','B','C','D','E', ...
- Python小练习更改版(更改一部分代码,与错误)
之前上传的发现有部分代码错误,重新上传: 更改了第一次的代码与错误,增加了注释与商店部分功能: 没有每天坚持更新博客,与初衷相差甚远,坚持!每天进步一点点! user_list.txt 部分代码: { ...
- 使用 C# 开发 Kubernetes 组件,获取集群资源信息
写什么呢 前段时间使用 C# 写了个项目,使用 Kubernetes API Server,获取信息以及监控 Kubernetes 资源,然后结合 Neting 做 API 网关. 体验地址 http ...
- ORACLE数据库误操作DELETE并且提交数据库之后如何恢复被删除的数据
一:根据时间来恢复: 1.查询数据库当前时间() select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual; 2.查询删除数据时间点之前的数据 ...
- linux可用内存判断
free是完全没有占用的空闲内存,Available 减 free是操作系统为了优化运行速度拿来调用的内存, 程序需要的话操作系统会进行释放.所以一般看Available即可. free+buffer ...
- %r和%s的区别
理解%r和%s的区别 %r会重现所表达的对象,%s会将所有转成字符串 eg1: print('i am %s years old' % 22) print('i am %r years old' % ...
- <input type="file"> 标签详解
详见:https://developer.mozilla.org/zh-CN/docs/Web/HTML/Element/Input/file#attr-multiple 使用 type=" ...
- 帆软报表(finereport)table块钻取,返回记住table块位置
<1>首先table块加初始化事件,idex为参数,参数值为$tab_idexsetTimeout(function(){_g().getWidgetByName("tabpan ...