MySQL必知必会笔记——查询的基础知识
查询基础知识
第七章 数据过滤
组合where子句
MySQL允许给出多个WHERE子句。这些子 句可以两种方式使用:以AND子句的方式或OR子句的方式使用。
AND操作符
可使用AND操作符给WHERE子句附加条件
-- 检索由1003制造且价格小于等于10美元的所有产品的名称和价格
SELECT prod_id, prod_price, prod_name FROM products
WHERE vend_id = 1003 AND prod_price <= 10;
OR操作符
OR用来表示检索匹配任一给定条件的行。
-- 检索由1002和1003制造的产品的名称和价格
SELECT prod_name, prod_price FROM products
WHERE vend_id = 1002 or vend_id = 1003;
计算次序
WHERE可包含任意数目的AND和OR操作符。允许两者结合以进行复杂 和高级的过滤。
AND的优先级高于OR
-- 列出价格为10美元(含)以上且由1002或1003制造的所有产品
SELECT prod_name, prod_price FROM products
WHERE (vend_id = 1002 OR vend_id = 1003) AND prod_price >= 10;
可以用括号括起来优先让某一部分先计算。
IN操作符
用来指定条件范围,取合法值的由逗号分隔的清单全部在圆括号中。
-- 检索供应商1002和1003制造的所有产品。
SELECT prod_name, prod_price FROM products WHERE vend_id IN (1002, 1003)
ORDER BY prod_name;
上述语句中WHERE vend_id IN (1002, 1003)等同于WHERE vend_id=1002 OR vend_id=1003)
IN比OR执行更快,最大的优点是可以包含其他SELECT语句,能够更动态地建立WHERE子句。
- 在使用长的合法选项清单时,IN操作符的语法更清楚且更直观。
- 在使用IN时,计算的次序更容易管理(因为使用的操作符更少)。
- IN操作符一般比OR操作符清单执行更快。
- IN的最大优点是可以包含其他SELECT语句,使得能够更动态地建 立WHERE子句。
NOT操作符
-- 列出除1002,1003之外所有供应商供应的产品
SELECT prod_name, prod_price FROM products WHERE vend_id NOT IN (1002, 1003)
ORDER BY prod_name;
用通配符进行过滤
通配符(wildcard) 用来匹配值的一部分的特殊字符。
LIKE操作符
LIKE指示MYSQL,后跟的搜索模式利用通配符匹配而不是直接相等匹配进行比较。
百分号(%)通配符
表示任何字符出现任意次数
-- 例:找出所有jet起头的产品
SELECT prod_id, prod_name FROM products WHERE prod_name LIKE 'jet%';
-- 例:使用多个通配符,匹配任何位置包含anvil的值,不论它之前或之后出现什么字符
SELECT prod_id, prod_name FROM products WHERE prod_name LIKE '%anvil%';
-- 例:找出s起头e结尾的所有产品
SELECT prod_name FROM products WHERE prod_name LIKE 's%e';
虽然似乎%通配符可以匹配任何东西,但有一个例外,即NULL。即使是WHERE prod_name LIKE '%'也不能匹配用值NULL作为产品名的行。
下划线(_)通配符
-- 只匹配单个字符而不是多个字符
SELECT prod_id, prod_name FROM products WHERE prod_name LIKE '_ ton anvil';
使用通配符的技巧
- 不要过度使用通配符,如果其他操作符能够达到目的应该使用其他操作符
- 在确实需要使用通配符时,除非绝对有必要,否则不要把它们用在搜索的开始处。 把通配符置于搜索模式的开始处搜索起来是最慢的。
- 仔细注意通配符的位置
第九章 用正则表达式进行搜索
使用MySQL正则表达式
基本字符匹配
MySQL 中使用 REGEXP 关键字指定正则表达式的字符匹配模式
-- 例:检索prod_name包含文本1000的所有行
SELECT prod_name FROM products WHERE prod_name REGEXP '1000'
ORDER BY prod_name;
.表示匹配任意一个字符
SELECT prod_name FROM products WHERE prod_name REGEXP '.000'
ORDER BY prod_name;
- LIKE和REGEXP的区别: LIKE '1000'匹配整个列值,等于'1000'时才会返回相应行,而REGEXP '1000'在列值内进行匹配,如果包含'1000'则会返回相应行。
也就是说,LIKE 匹配整个列,如果被匹配的文本在列值中出现,LIKE 将不会找到它,相应的行也不会被返回(除非使用通配符)。而 REGEXP 在列值内进行匹配,如果被匹配的文本在列值中出现,REGEXP 将会找到它,相应的行将被返回,并且 REGEXP 能匹配整个列值(与 LIKE 相同的作用)。
看个实际例子就好理解了。
这是orders表:
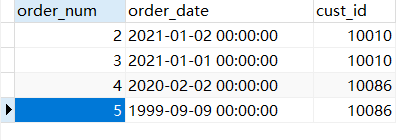
我们使用like来查询:
select * from orders where cust_id like "100";
其结果如下,为空:
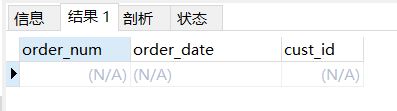
使用regexp实验:
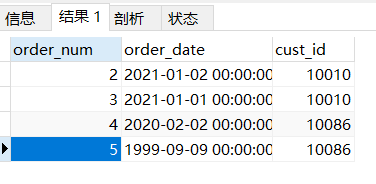
select * from orders where cust_id REGEXP "100";
其结果如下:
MySQL 的正则表达式匹配(自3.23.4版本后)不区分大小写(即大写和小写都匹配)。为区分大小写,可以使用 BINARY 关键字
WHERE prod_name REGEXP BINARY 'JetPack .000';
进行OR匹配
|为正则表达式的OR操作符,表示匹配其中之一
SELECT prod_name FROM products WHERE prod_name REGEXP '1000|2000'
ORDER BY prod_name;
可以给出两个以上的OR条件1000|2000|3000
匹配几个字符之一
[]表示匹配[]中的任何单一字符,可以理解为另一种形式的OR语句。
另外,[123]是[1|2|3]的缩写
SELECT prod_name FROM products WHERE prod_name REGEXP '[123] Ton'
ORDER BY prod_name;
-- 结果
+-------------+
| prod_name |
+-------------+
|1 ton anvil |
|2 ton anvil |
+-------------+
记得一定要加方括号,以下是不加方括号的结果
SELECT prod_name FROM products WHERE prod_name REGEXP '1|2|3 Ton'
ORDER BY prod_name
-- 结果
+-------------+
| prod_name |
+-------------+
|1 ton anvil |
|2 ton anvil |
|JetPack 1000 |
|JetPack 2000 |
|TNT (1 stick)|
+-------------+
不加方括号它匹配的含义是1 OR 2 OR 3 Ton,所以还会检索出JetPack 1000等不符合要求的行。
字符集合也可以被否定,为否定一个字集,在集合的开始处放置^,例如[^123]匹配除这些字符的任何东西
匹配范围
匹配0到9,可以用[0123456789],为了简化,可以用-来定义范围,可以写成[0-9]。同理,a到z的范围就可以写成[a-z]。
SELECT prod_name FROM products WHERE prod_name REGEXP '[1-5] Ton'
ORDER BY prod_name
-- 结果
+-------------+
| prod_name |
+-------------+
| .5 ton anvil|
| 1 ton anvil |
| 2 ton anvil |
+-------------+
匹配特殊字符
特殊字符,比如我们前文说到的
.:匹配任一字符[]:匹配几个字符中是某个字符-:指定范围
如下面的例子:
SELECT vend_name FROM vendors WHERE vend_name REGEXP '.'
ORDER BY vend_name;
-- 结果
+---------------+
| vend_name |
+---------------+
| ACME |
| Anvils R Us |
| Furball Inc. |
| Jet Set |
| Jouets Et Ours|
| LT Supplies |
+---------------+
因为'.'为匹配任意字符,所以匹配的结果不是我们想要的结果。
如果只想匹配带.的结果,必须用\\为前导。同理,匹配其他特殊字符也要用\\为前导.
SELECT vend_name FROM vendors WHERE vend_name REGEXP '\\.'
ORDER BY vend_name;
-- 结果
+---------------+
| vend_name |
+---------------+
| Furball Inc. |
+---------------+
正则表达式中具有特殊意义的所有字符都要通过这种方式转义 \\也用来引用元字符
| 元字符 | 说明 |
|---|---|
\\f |
换页 |
\\n |
换行 |
\\r |
回车 |
\\t |
制表 |
\\v |
纵向制表 |
为了匹配\本身,需要使用\\\ |
匹配字符类
| 类 | 说明 |
|---|---|
| [:alnum:] | 任意字母和数字(同[a-zA-Z0-9]) |
| [:alpha:] | 任意字符(同[a-zA-Z]) |
| [:cntrl:] | 空格和制表(同[\t]) |
| [:digit:] | ASCII控制字符(ASCII)0到31和127 |
| [:graph:] | 任意数字(同[0-9]) |
| [:lower:] | 任意小写字母(同[a-z]) |
| [:print:] | 任意可打印字符 |
| [:punct:] | 既不在[:alnum:]又不在[:cntrl:]中的任意字符 |
| [:space:] | 包括空格在内的任意空白字符(同[\f\n\r\t\v]) |
| [:upper:] | 任意大写字母(同[A-Z]) |
| [:xdigit:] | 任意十六进制数字(同[a-fA-F0-9]) |
匹配多个实例
| 元字符 | 说明 |
|---|---|
| * | 0个或多个匹配 |
| + | 1个或多个匹配(等于{1,}) |
| ? | 0个或1个匹配(等于{0,1}) |
| {n} | 指定数目的匹配 |
| {n,} | 不少于指定数目的匹配 |
| {n.m} | 匹配数目的范围(m不超过255) |
例:
SELECT prod_name FROM products WHERE prod_name REGEXP '\\([0-9] sticks?\\)'
ORDER BY prod_name
-- 结果
+---------------+
| prod_name |
+---------------+
| TNT (1 stick) |
| TNT (5 sticks)|
+---------------+
说明:
\\(表示匹配左括号[0-9]表示匹配0到9的任意数字stick?匹配'stick'和'sticks'\\)表示匹配右括号
例:匹配连在一起的4位数字
SELECT prod_name FROM products WHERE prod_name REGEXP '[[:digit:]]{4}'
ORDER BY prod_name;
-- 结果
+---------------+
| prod_name |
+---------------+
| JetPack 1000 |
| JetPack 2000 |
+---------------+
-- 也可以写成 '[0-9][0-9][0-9][0-9]'
定位符
| 元字符 | 说明 |
|---|---|
| ^ | 文本的开始 |
| $ | 文本的结尾 |
| [:<:] | 词的开始 |
| [:>:] | 词的结尾 |
| 例:找出以一个数(包括小数点开头)开始的所有产品 |
SELECT prod_name FROM products WHERE prod_name REGEXP '^[0-9\\.]'
ORDER BY prod_name;
-- 结果
+---------------+
| prod_name |
+---------------+
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
+---------------+
第十章 创建计算字段
拼接字段
拼接:将值联结到一起构成单个值
在SELECT语句中,可使用Concat()函数来拼接两个列。Concat()函数需要一个或多个指定的串,各个串之间用逗号分隔。
SELECT Concat(vend_name, ' (',vend_country,')') FROM vendors
ORDER BY vend_name;
-- 结果
+-----------------------------------------+
| Concat(vendname,' (',vend_country,')') |
+-----------------------------------------+
| ACME (USA) |
| Anvils R Us (USA) |
| Furball Inc. (USA) |
| Jet Set (England) |
| Jouets Et Ours (France) |
| LT Supplies (USA) |
+-----------------------------------------+
删除字段多余空格
| 函数 | 说明 |
|---|---|
| Trim() | 去掉两边的空格 |
| LTrim() | 去掉左边的空格 |
| RTrim() | 去掉右边的空格 |
示例:使用 RTrim()函数删除右侧多余的空格。
SELECT Concat(RTrim(vend_name),' (',RTrim(vend_country), ')')
FROM vendors
ORDER BY vend_name;
使用别名
可以用AS关键字赋予别名
SELECT Concat(RTrim(vend_name), ' (', RTrim(vend_country), ')') AS
vend_title
FROM vendors
ORDER BY vend_name;
-- 结果
+----------------------------+
| vend_title |
+----------------------------+
| ACME (USA) |
| Anvils R Us (USA) |
| Furball Inc. (USA) |
| Jet Set (England) |
| Jouets Et Ours (France) |
| LT Supplies (USA) |
+----------------------------+
执行算术计算
-- 汇总物品的价格(单价乘以订购数量)
SELECT prod_id,
quantity,
item_price,
quantity * item_price AS expand_price
FROM orderitems
WHERE order_num = 20005;
-- 结果
+---------+----------+------------+----------------+
| prod_id | quantity | item_price | expanded_price |
+---------+----------+------------+----------------+
| ANV01 | 10 | 5.99 | 59.90 |
| ANV02 | 3 | 9.99 | 29.97 |
| TNT2 | 5 | 10.00 | 50.00 |
| FB | 1 | 10.00 | 10.00 |
+---------+----------+------------+----------------+
如上代码的第四行中出现了quantity * item_price,我们可以对检索出的数据进行算术计算,常用的操作符如下:
| 操作符 | 说明 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
第十一章 使用数据处理函数
文本处理函数
常用的文本处理函数
| 函数 | 说明 |
|---|---|
| Left() | 返回串左边的字符 |
| Length() | 返回串的长度 |
| Locate() | 找出串的一个子串 |
| Lower() | 将串转换为小写 |
| LTrim() | 去掉串左边的空格 |
| Right() | 返回串右边的字符 |
| RTrim() | 去掉串右边的空格 |
| Soundex() | 返回串的SOUNDEX值 |
| SubString() | 返回子串的字符 |
| Upper() | 将串转换为大写 |
-- 示例:将文本转换为大写
SELECT vend_name, Upper(vend_name) AS vend_name_upcase
FROM vendors
ORDER BY vend_name;
上表中Soundex()的补充说明:
SOUNDEX是一个将任何文本转换为描述其语音表示的字母数字模式的算法,使得能对串进行发音比较而不是字母比较。MySQL提供对SOUNDEX的支持。
看一下下面的例子
表中有一个用户的名字为Y.Lee,通过select查询联系人时输入错误为Y.Lie。此时Y.Lee这一行时不会被检索出来的,但使用SOUNDEX检索,可以匹配发音类似于Y.Lie的联系名:
SELECT cust_name, cust_contact FROM customers
WHERE Soundex(cust_contact)= Soundex('Y Lie'); -- 结果 +-------------+--------------+
| cust_name | cust_contact |
+-------------+--------------+
| Coyote Inc. | Y Lee |
+-------------+--------------+
日期和时间处理函数
| 函数 | 说明 |
|---|---|
| AddDate() | 增加一个日期(天、周等) |
| AddTime() | 增加一个时间(时、分等) |
| CurDate() | 返回当前日期 |
| CurTime() | 返回当前时间 |
| Date() | 返回日期时间的日期部分 |
| DateDiff() | 计算两个日期之差 |
| Date_Add() | 高度灵活的日期计算函数 |
| Date_Format() | 返回一个格式化的日期或时间串 |
| Day() | 返回一个日期的天数部分 |
| DayOfWeek() | 对于一个日期,返回对应的星期几 |
| Hour() | 返回一个时间的小时部分 |
| Minute() | 返回一个时间的分钟部分 |
| Month() | 返回一个日期的月份部分 |
| Now() | 返回当前日期和时间 |
| Second() | 返回一个时间的秒部分 |
| Time() | 返回一个日期时间的时间部分 |
| Year() | 返回一个日期的年份部分 |
使用日期格式的注意点:
日期必须为格式yyyy-mm-dd
关于datetime
SELECT cust_id, order_num FROM orders
WHERE order_date = '2021-01-02';
sql语句中的order_date类型为datetime,它具有时间值00:00:00。生成时间数据时,比如生成
"2021-01-02",生成的数据除了年月日还会自动生成时分秒,默认是00:00:00。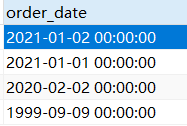
此时,如果你检索的值为2021-01-02 14:06:29,则上面的
WHERE order_date = '2021-01-02'不会检索出这一行要使用Date()函数,才能找到值为2021-01-02 14:06:29的行
SELECT cust_id, order_num FROM orders
WHERE Date(order_date) = '2021-01-02';
示例:检索出2005年9月下的所有订单
SELECT cust_id, order_num FROM orders
WHERE Date(order_date) BETWEEN '2005-09-01' AND '2005-09-30';
或者
SELECT cust_id, order_num FROM orders
WHERE Year(roder_date) = 2005 AND Month(order_date) = 9;
数值处理函数
| 函数 | 说明 |
|---|---|
| Abs() | 返回一个数的绝对值 |
| Cos() | 返回一个角度的余弦 |
| Exp() | 返回一个数的指数值 |
| Mod() | 返回除操作的余数 |
| Pi() | 返回圆周率 |
| Rand() | 返回一个随机数 |
| Sin() | 返回一个角度的正弦 |
| Sqrt() | 返回一个数的平方根 |
| Tan() | 返回一个角度的正切 |
第十二章 汇总函数
聚集函数
聚集函数(aggregate function):运行在行组上,计算和返回单个值的函数。
| 函数 | 说明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值之和 |
VG()函数
例:返回products表中所有产品的平均价格
SELECT AVG(prod_price) AS avg_price FROM products;
例:返回特定供应商所提供产品的平均价格
SELECT AVG(prod_price) AS avg_price
FROM products
WHERE vend_id = 1003;
COUNT()函数
例:返回customer表中客户的总数
SELECT COUNT(*) AS num_cust FROM customers;
例:只对具有电子邮件地址的客户计数
SELECT COUNT(cust_email) AS num_cust
FROM customers;
MAX()函数
例:返回products表中最贵的物品价格
SELECT MAX(prod_price) AS max_price
FROM products;
对非数值数据使用MAX() MySQL允许将它用来返回任意列中的最大值,包括返回文本列中的最大值。在用于文本数据时,如果数据按相应的列排序,则MAX()返回最后一行。MAX()函数忽略列值为NULL的行。
MIN()函数
例:
SELECT MIN(prod_price) AS min_price FROM products;
SUM()函数
返回指定列值的和(总计) 例:检索所订购物品的总数
SELECT SUM(quantity) AS items_ordered
FROM orderitems
WHERE order_num = 20005;
例:合计计算值,合计每项物品item_price*quantity,得出订单总金额
SELECT SUM(item_price*quantity) AS total_price
FORM orderitems
WHERE order_num = 20005;
聚集不同值(适用于5后的版本)
上述五个聚集函数都可以如下使用:
- 对所有的行执行计算,指定ALL参数或不给参数(ALL为默认)
- 只包含不同的值,指定DISTINCT参数
-- 物品的平均价格
SELECT AVG(DISTINCT prod_price) AS avg_price
FROM products
WHERE vend_id = 1003;
如果指定列名,则DISTINCT只能用于COUNT()。DISTINCT不能用于COUNT(*),因此不允许使用COUNT(DISTINCT), 否则会产生错误。类似地,DISTINCT必须使用列名,不能用于计算或表达式。
组合聚集函数
SELECT语句可根据需要包含多个聚集函数
SELECT COUNT(*) AS num_items;
MIN(prod_price) AS price_min,
MAX(prod_price) AS price_max,
AVG(prod_price) AS price_avg
FROM products;
-- 结果
+-----------+-----------+-----------+-----------+
| num_items | price_min | price_max | price_avg |
+-----------+-----------+-----------+-----------+
| 14 | 2.50 | 55.50 | 16.133571 |
+-----------+-----------+-----------+-----------+
第十三章 分组数据
数据分组
分组允许把数据分为多个逻辑组,以便能对每个组进行聚集计算。
创建分组
例:根据vend_id分组,对每个分组分别计算总数
SELECT vend_id, COUNT(*) AS num_prods
FROM products
GROUP BY vend_id;
-- 结果
+---------+-----------+
| vend_id | num_prods |
+---------+-----------+
| 1001 | 3 |
| 1002 | 2 |
| 1003 | 7 |
| 1005 | 2 |
+---------+-----------+
结果表明vend_id为1001有3个,vend_id为1002有2个,vend_id为1003有7个,vend_id为1005有2个。
在具体使用GROUP BY子句前,需要知道一些重要的规定。
- GROUP BY 子句可以包含任意数目的列,使得能对分组进行嵌套,为数据分组提供更细致的控制
- 如果GROUP BY子句中中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
- GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。
- 除聚集计算语句外,SELECT语句中的每个列都必须在GROUP BY子句中给出。
- 如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
- GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
过滤分组
WHERE指定的是行,不是分组,WHERE没有分组的概念
使用HAVING过滤分组
SELECT cust_id, COUNT(*) AS orders
FROM orders
GROUP BY cust_id
HAVING COUNT(*) >= 2;
-- 结果
+---------+--------+
| cust_id | orders |
+---------+--------+
| 10001 | 2 |
+---------+--------+
WHERE不起作用,因为过滤是基于分组聚集值而不是特定行值的。
-- 列出具有2个(含)以上、价格为10(含)以上的产品的供应商
SELECT vend_id, COUNT(*) AS num_prods
FROM products
WHERE prod_price >= 10
GROUP BY vend_id
HAVING COUNT(*) >=2
-- 结果
+---------+-----------+
| vend_id | num_prods |
+---------+-----------+
| 1003 | 4 |
| 1005 | 2 |
+---------+-----------+
分组和排序
虽然GROUP BY和ORDER BY经常完成相同的工作,但它们是非常不同的。
ORDER BY与GROUP BY的区别:
| ORDER BY | GROUP BY |
|---|---|
| 排序产生的输出 | 分组行。但输出可能不是分组的顺序 |
| 任意列都可以使用(甚至 非选择的列也可以使用) | 只可能使用选择列或表达式列,而且必须使用每个选择 列表达式 |
| 不一定需要 | 如果与聚集函数一起使用列(或表达式),则必须使用 |
一般在使用GROUP BY子句时,应该也给出ORDER BY子句。这是保证数据正确排序的唯一方法。千万不要仅依赖GROUP BY排序数据。
-- 检索总计订单价格大于等于50的订单的订单号和总计订单价格
SELECT order_num, SUM(quantity*item_price) AS ordertotal
FROM orderitems
GROUP BY order_num
HAVING SUM(quantity*item_price) >= 50
ORDER BY ordertital;
SELECT子句顺序
SELECT子句及其顺序
| 子句 | 说明 | 是否必须使用 |
|---|---|---|
| SELECT | 要返回的列或表达式 | 是 |
| WHERE | 从中检索数据的表 | 仅在从表选择数据时使用 |
| GROUP BY | 分组说明 | 尽在按组计算聚集是使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 输出排序顺序 | 否 |
| LIMIT | 要检索的行数 | 否 |
上述子句使用时必须遵循该顺序
第十四章 使用子查询
SELECT order_num FROM orderitems
WHERE prod_id = 'TNT2';
SELECT cust_id
FROM orders
WHERE order_num IN (20005, 20007);
可以使用如下方式
SELECT cust_id
FROM orders
WHERE order_num IN (SELECT order_num FROM orderitems WHERE prod_id = 'TNT2');
再加一个条件:
SELECT clust_name. cust_contact FROM customers WHERE cust_id IN (10001, 10004)
合并为一句sql
SELECT cust_name, cust_contact FROM customers
WHERE cust_id IN(SELECT cust_id FROM orders
WHERE order_name IN(SELECT order_num FROM orderitems
WHERE prod_id ='TNT2'));
- 在WHERE子句中使用子查询应保证SELECT语句有与WHERE子句中相同数目的列。
- 这里给出的代码有效并获得所需的结果。但是,使用子查询并不总是执行这种类型的数据检索的最有效的方法。(即这样写执行的性能不一定最好)
作为计算字段使用子查询
# 对客户10001的订单进行计数
SELECT COUNT (*) AS orders FROM orders WHERE cust_id = 10001;
# 为了对每个客户执行COUNT(*)计算,应该将COUNT(*)作为一个子查询
SELECT cust_name, cust_state, (SELECT COUNT(*) FROM orders
WHERE orders.cust_id = customers.cust_id) AS orders
FROM customers ORDER BY cust_name;
MySQL必知必会笔记——查询的基础知识的更多相关文章
- 《mysql必知必会》读书笔记--存储过程的使用
以前对mysql的认识与应用只是停留在增删改查的阶段,最近正好在学习mysql相关内容,看了一本书叫做<MySQL必知必会>,看了之后对MySQL的高级用法有了一定的了解.以下内容只当读书 ...
- MySQL必知必会(第4版)整理笔记
参考书籍: BookName:<SQL必知必会(第4版)> BookName:<Mysql必知必会(第4版)> Author: Ben Forta 说明:本书学习笔记 1.了解 ...
- MySQL必知必会1-20章读书笔记
MySQL备忘 目录 目录 使用MySQL 检索数据 排序检索数据 过滤数据 数据过滤 用通配符进行过滤 用正则表达式进行搜索 创建计算字段 使用数据处理函数 数值处理函数 汇总数据 分组数据 使用子 ...
- 《MySQL必知必会》[01] 基本查询
<MySQL必知必会>(点击查看详情) 1.写在前面的话 这本书是一本MySQL的经典入门书籍,小小的一本,也受到众多网友推荐.之前自己学习的时候是啃的清华大学出版社的计算机系列教材< ...
- 读《MySql必知必会》笔记
MySql必知必会 2017-12-21 意义:记录个人不注意的,或不明确的,或不知道的细节方法技巧,此书250页 登陆: mysql -u root-p -h myserver -P 9999 SH ...
- 《MySQL必知必会》学习笔记——前言
前言 MySQL已经成为世界上最受欢迎的数据库管理系统之一.无论是用在小型开发项目上,还是用来构建那些声名显赫的网站,MySQL都证明了自己是个稳定.可靠.快速.可信的系统,足以胜任任何数据存储业务的 ...
- MySQL必知必会:组合查询(Union)
MySQL必知必会:组合查询(Union) php mysqlsql 阅读约 8 分钟 本篇文章主要介绍使用Union操作符将多个SELECT查询组合成一个结果集.本文参考<Mysql ...
- 《MySQL必知必会》学习笔记整理
简介 此笔记只包含<MySQL必知必会>中部分章节的整理笔记.这部分章节主要是一些在<SQL必知必会>中并未讲解的独属于 MySQL 数据库的一些特性,如正则表达式.全文本搜索 ...
- MySQL必知必会复习笔记(1)
MySQL必知必会笔记(一) MySQL必知必会是一本很优秀的MySQL教程书,并且相当精简,在日常中甚至能当成一本工作手册来查看.本系列笔记记录的是:1.自己记得不够牢的代码:2.自己觉得很重要的代 ...
随机推荐
- Windows PE资源表编程(枚举资源树)
资源枚举 写一个例子,枚举一个PE文件的资源表.首先说下资源相关的作为铺垫. 1.资源类型也是PE可选头中数据目录的一种.位于第三个类型. 2.资源目录分为三层.第四层是描述文件相关的.这些结构是按照 ...
- java线程池实践
线程池大家都很熟悉,无论是平时的业务开发还是框架中间件都会用到,大部分都是基于JDK线程池ThreadPoolExecutor做的封装, 都会牵涉到这几个核心参数的设置:核心线程数,等待(任务)队列, ...
- Markdown修改字体颜色
在写blog时,想高亮某些字,但是发现markdown更改字体颜色不像word里那么方便,于是查了一下,要用一下代码进行更改字体颜色,还可以更改字体大小,还有字体格式 <font 更改语法> ...
- 浅谈持续集成(CI)、持续交付(CD)、持续部署(CD)
CI/CD是实现敏捷和Devops理念的一种方法,具体而言,CI/CD 可让持续自动化和持续监控贯穿于应用的 整个生命周期(从集成和测试阶段,到交付和部署).这些关联的事务通常被统称为"CI ...
- readdir_r()读取目录内容
readdir()在多线程操作中不安全,Linux提供了readdir_r()实现多线程读取目录内容操作. #include <stdio.h> #include <stdlib.h ...
- NPM包管理器入门(附加cnpm : 无法加载文件错误解决方案)
NPM 包管理器 1.作用: 快速构建nodejs工程 快速安装和依赖第三个模块 2.使用方法 快速构建 npm init 会得到一package.json文件 { "name": ...
- 用JIRA管理你的项目——(三)基于LDAP用户管理
JIRA提供了基于LDAP方式的用户管理,也就是用户密码的管理交给LDAP,而JIRA只管理用户在系统中的角色. 要打开JIRA的LDAP设置,首先需要验证下你的LDAP服务是否正常! 几乎有所有的L ...
- CentOS 7 vs. CentOS 8 版本差异大比拼
CentOS 7 vs. CentOS 8 版本差異大比拼 2020-02-14 CentOS 最近剛好在撰寫課鋼,必須要以最新的 CentOS 8 版本為主,剛好來做一下 CentOS 7 和 Ce ...
- 面试阿里P6难在哪?(面试难点)
对于很多没有学历优势的人来说,面试大厂是非常困难的,这对我而言,也是一样,出身于二本,原本以为就三点一线的生活度过一生,直到生活上的变故,才让我有了新的想法和目标,因此我这个二本渣渣也奋斗了起来,竟拿 ...
- 搭建LAMP环境部署discuz论坛
!!!什么是LAMP: LAMP是指一组通常一起使用来运行动态网站或者服务器的自由软件名称首字母缩写: Linux,操作系统 Apache,网页服务器 MariaDB或MySQL,数据库管理系统(或者 ...