Python基础入门(9)- Python文件操作
1.文件的读写
1.1.文件的创建与写入
- 利用内置函数open获取文件对象
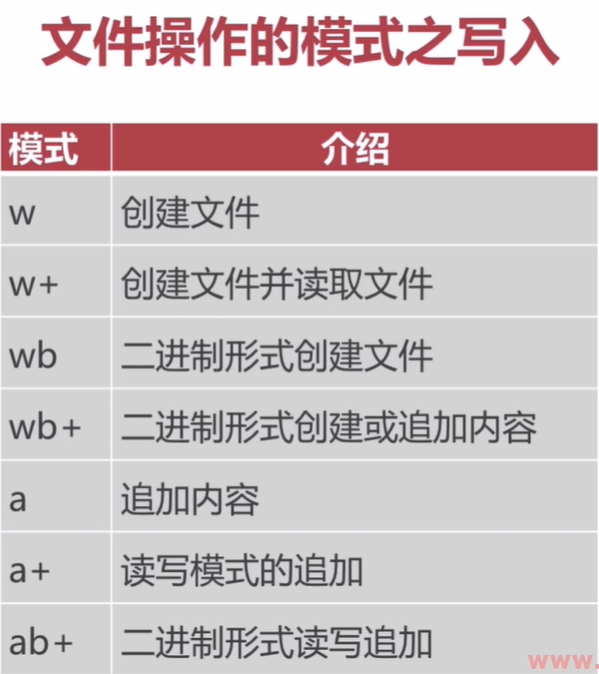
- 文件操作的模式之写入
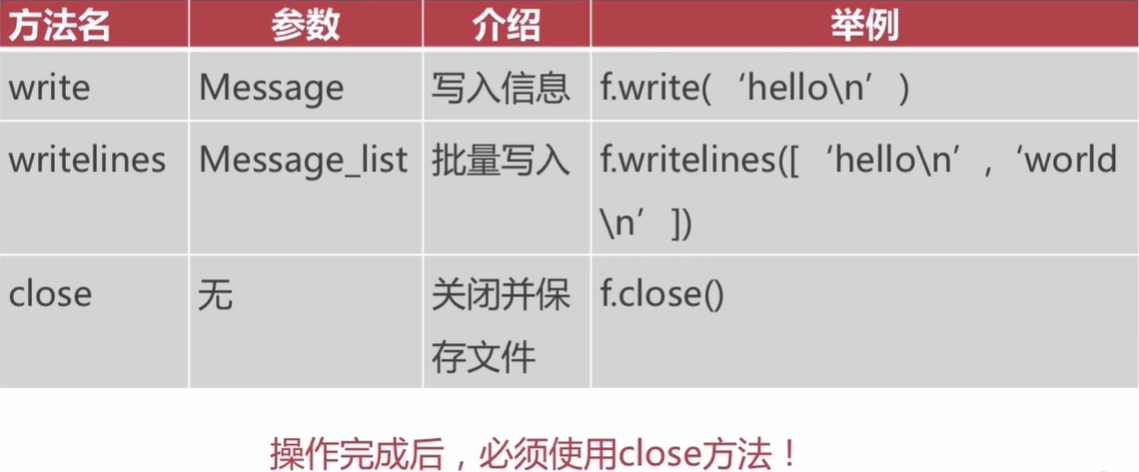
- 文件对象的操作方法之写入保存
1 # coding:utf-8
2
3 import os
4
5 current_path=os.getcwd()
6 file_path=os.path.join(current_path,'test_os.txt')
7
8 f=open(file_path,'w',encoding="utf-8") #Windows系统在写入中文时需要设置编码格式
9 f.write("Hello Python;你好 Python")
10 #f.read() io.UnsupportedOperation: not readable,控制台报错,因为f是w模式
11 f.close()
12
13 f=open(file_path,'w+',encoding="utf-8") #Windows系统在写入中文时需要设置编码格式
14 f.write("Hello World;你好 世界")
15 print(f.read()) #无内容输出,read读取文件的话 是从最后一个角标读取
16 f.seek(0) #此时调用seek,选择从索引开始读取,则会读取所有刚才写入的字符串
17 print(f.read()) #Hello World;你好 世界
18 f.close()
19
20 f=open(file_path,'ab')#a:追加,b:比特类型
21 message="python很有意思"
22 #message=b"python很有意思" SyntaxError: bytes can only contain ASCII literal characters.之前的知识,我们使用b对字符串内容转译成比特类型报错,因为b特类型不能有汉字,所以得采用其他办法
23 _message=message.encode("utf-8") #将字符串变成比特类型
24 f.write(_message)
25 f.close()
26
27 f=open(file_path,'a')
28 message=("1\n","2\n","3\n")
29 f.writelines(message)
30 f.close()1 # coding:utf-8
2 import os
3
4 #练习1:自动创建python包
5 def creat_package(path):
6 if os.path.exists(path):
7 raise Exception('%s 已经存在,不可创建'% path)
8 os.makedirs(path)
9 init_path=os.path.join(path,'__init__.py')
10 f=open(init_path,'w')
11 f.write('# coding:utf-8\n')
12 f.close()
13
14 if __name__=='__main__':
15 current_path=os.getcwd()
16 path=os.path.join(current_path,'test1')
17 creat_package(path)1 # coding:utf-8
2 import os
3
4 #练习2:写入文件
5 class Open(object):
6 def __init__(self,path,mode='w',is_return=True):
7 self.path=path
8 self.mode=mode
9 self.is_return=is_return
10
11 def write(self,message):
12 f=open(self.path,mode=self.mode)
13 if self.is_return:
14 message= '%s\n' %message
15 f.write(message)
16 f.close()
17
18 if __name__=='__main__':
19 current_path=os.getcwd()
20 open_path=os.path.join(current_path,'a.txt')
21 o=Open(open_path)
22 o.write("Hello World")1 # coding:utf-8
2 import os
3
4 #练习2:容错处理完善
5 class Open(object):
6 def __init__(self,path,mode='w',is_return=True):
7 self.path=path
8 self.mode=mode
9 self.is_return=is_return
10
11 def write(self,message):
12 f=open(self.path,mode=self.mode)
13 if message.endswith("\n"):
14 self.is_return=False
15 if self.is_return:
16 message= '%s\n' %message
17 try:
18 f.write(message)
19 finally:
20 f.close()
21
22 if __name__=='__main__':
23 current_path=os.getcwd()
24 open_path=os.path.join(current_path,'a.txt')
25 o=Open(open_path,'a')
26 o.write("Hello World\n")
1.2.文件的读操作
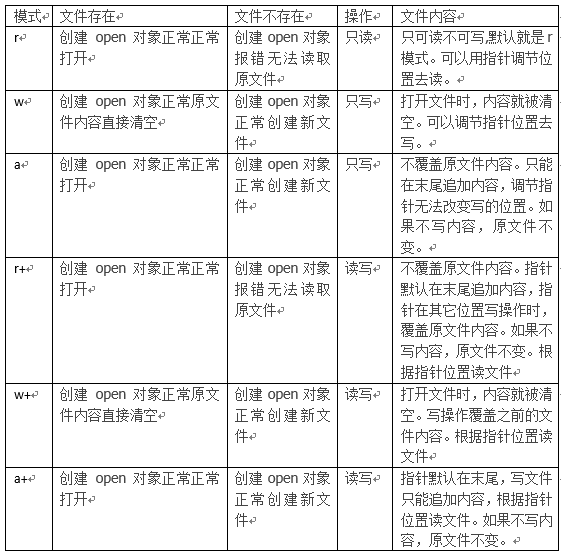
- 文件操作的模式之读
r:返回数据类型为字符串;rb:读取bit类型
- 文件对象的操作方法之读取
1 # coding:utf-8
2
3 import os
4
5 file_path=os.getcwd()
6 file=os.path.join(file_path,'a.txt')
7
8 #read用法,读取文件所有内容,返回的是字符串,read可以和seek配合使用,重置角标去取
9 f=open(file,'r')
10 # data=f.read()
11 # print(data)
12 '''
13 Hello World
14 Hello World
15 Hello World
16 '''
17
18 #readlines用法,返回的是一个列表,每个元素带\n换行
19 '''
20 data=f.readlines()
21 print(data) #['Hello World\n', 'Hello World\n', 'Hello World\n']
22 _data=[]
23 for i in data:
24 temp=i.strip() #strip默认去除空格,换行符等
25 if temp != '': #去除空行
26 _data.append(temp)
27 print(_data) #['Hello World', 'Hello World', 'Hello World']
28 '''
29
30 #readline用法,逐行去取
31 '''
32 data=f.readline()
33 print(data) #Hello World
34 data=f.readline()
35 print(data) #123
36 '''
37
38 #mode用法,使用什么方式打开open(path,mode)文件,返回mode的值
39 print(f.mode) #r
40
41 #name用法,返回文件名称
42 print(f.name) #D:\WorkSpace\Python_Study\a.txt
43 print(os.path.split(f.name)[1]) #a.txt
44
45 #closed用法,文件是否关闭
46 print(f.closed) #False
47 f.close()
48 print(f.closed) #True1 # coding:utf-8
2 import os
3
4 #文件读写简单封装:
5 class Open(object):
6 def __init__(self,path,mode='w',is_return=True):
7 self.path=path
8 self.mode=mode
9 self.is_return=is_return
10
11 def write(self,message):
12 f=open(self.path,mode=self.mode)
13 if message.endswith("\n"):
14 self.is_return=False
15 if self.is_return:
16 message='%s\n'%message
17 try:
18 f.write(message)
19 finally:
20 f.close()
21
22 def read(self,is_strip=True):
23 result=[]
24 with open(self.path,mode=self.mode) as f:
25 data=f.readlines()
26 for line in data:
27 if is_strip: #is_strip需不需要去掉每个元素的\n
28 temp=line.strip()
29 if temp != '':
30 result.append(temp)
31 else:
32 if line !='':
33 result.append(line)
34 return result
35
36 if __name__=='__main__':
37 carrent_path=os.getcwd()
38 file_path=os.path.join(carrent_path,'a.txt')
39 o=Open(file_path,mode='r')
40 data=o.read()
41 print(data)



2.文件的应用
2.1.序列化
- 初识序列化与反序列化
- 序列化:将对象信息或数据结构信息进行转换,达到存储和传输的目的,最终的数据类型是有一定规则的字符串,可用于文件存储或网络传输
- 反序列化:通过序列化生成的字符串反转回原来的形式
- 可序列化的数据类型
- 可序列化:number,str,list,tuple,dict(最常用的序列化数据类型)
- 不可序列化:类,实例化对象,函数,集合不能进行序列化
- Python中的json:通用序列化模块,所有编程语言都有,序列化与反序列化规则统一
- Python中的pickle:只使用python编程语言,pickle性能比json好
1 # coding:utf-8
2 import json
3
4 a=99
5 b='str'
6 c=(1,2,3)
7 d=[4,5,6]
8 e={"name":"中国"}
9
10 #json序列化
11 a_json=json.dumps(a)
12 print(a_json,type(a_json)) #99 <class 'str'>
13 b_json=json.dumps(b)
14 print(b_json,type(b_json)) #"str" <class 'str'>
15 c_json=json.dumps(c)
16 print(c_json,type(c_json)) #[1, 2, 3] <class 'str'>
17 d_json=json.dumps(d)
18 print(d_json,type(d_json)) #[4, 5, 6] <class 'str'>
19 e_json=json.dumps(e)
20 print(e_json,type(e_json)) #{"name": "\u4e2d\u56fd"} <class 'str'>
21
22 #json反序列化
23 print(json.loads(a_json),type(json.loads(a_json))) #99 <class 'int'>
24 print(json.loads(b_json),type(json.loads(b_json))) #str <class 'str'>
25 print(json.loads(c_json),type(json.loads(c_json))) #元组反序列化后数据类型变成了列表,[1, 2, 3] <class 'list'>
26 print(json.loads(d_json),type(json.loads(d_json))) #[4, 5, 6] <class 'list'>
27 print(json.loads(e_json),type(json.loads(e_json))) #{'name': '中国'} <class 'dict'>
28
29 #特殊数据类型进行json序列化与反序列化
30 #布尔类型
31 print(json.dumps(True)) #true
32 print(json.loads(json.dumps(True))) #True
33 print(json.dumps(False)) #false
34 print(json.loads(json.dumps(False))) #False
35 #空类型
36 print(json.dumps(None)) #null
37 print(json.loads(json.dumps(None))) #None1 # coding:utf-8
2 import pickle
3
4 #pickle用法同json,此处不再过多演示
5 e={"name":"中国"}
6
7 #pickle序列化
8 e_pickle=pickle.dumps(e)
9 print(e_pickle,type(e_pickle)) #b'\x80\x03}q\x00X\x04\x00\x00\x00nameq\x01X\x06\x00\x00\x00\xe4\xb8\xad\xe5\x9b\xbdq\x02s.' <class 'bytes'>
10
11 #pickle反序列化
12 print(pickle.loads(e_pickle),type(pickle.loads(e_pickle))) #{'name': '中国'} <class 'dict'>1 # coding:utf-8
2
3 import json
4
5 def read(path):
6 with open('text.json','r') as f:
7 data=f.read()
8 return json.loads(data)
9
10 def write(path,data):
11 with open(path,'w') as f:
12 if isinstance(data,dict):
13 _data=json.dumps(data)
14 f.write(_data)
15 else:
16 raise TypeError('data is dict')
17 return True
18
19 data={"name":"张三","age":18}
20
21 if __name__=="__main__":
22 write('text.json',data)
23 print(read('text.json'))
2.2.yaml的用法
2.2.1.yaml格式的介绍
2.2.2.Python的第三方包---pyyaml
2.2.3.读取yaml文件的方法
1 #yaml文件内容
2 url:
3 https://www.baidu.com
4 types:
5 - 网页
6 - 百度百科
7 - 图片
8 dict_1:
9 name:12
10 age:181 # coding:utf-8
2
3 import yaml
4 def read(path):
5 with open(path,'r',encoding="utf-8") as f:
6 data=f.read()
7 result=yaml.load(data,Loader=yaml.FullLoader)
8 return result
9
10 if __name__=='__main__':
11 print(read("text.yaml"))





回顾:
Python基础入门(9)- Python文件操作的更多相关文章
- python基础入门之对文件的操作
**python**文件的操作1.打开文件 打开文件:open(file,mode='r') file:操作文件的路径加文件名 #绝对路径:从根目录开始的 #相对路径:从某个路径开始 mode:操作文 ...
- python基础之元组、文件操作、编码、函数、变量
1.集合set 集合是无序的,不重复的,主要作用: 去重,把一个列表变成集合,就可以自动去重 关系测试,测试两组数据的交集,差集,并集等关系 操作例子如下: list_1 = [1,4,5,7,3,6 ...
- Python之路:Python 基础(三)-文件操作
操作文件时,一般需要经历如下步骤: 打开文件 操作文件 一.打开文件 文件句柄 = file('文件路径', '模式') # 还有一种方法open 例1.创建文件 f = file('myfile. ...
- Python基础(七)-文件操作
一.文件处理流程 1.打开文件,得到文件句柄赋值给一个变量 2.通过句柄对文件进行操作 3.关闭文件 二.基本操作 f = open('zhuoge.txt') #打开文件 first_line = ...
- python基础 (编码进阶,文件操作和深浅copy)
1.编码的进阶 字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码. 即先将其他编码的字符串解码(decode)成unicode,再从uni ...
- python基础(四)文件操作和集合
一.文件操作 对文件的操作分三步: 1.打开文件获取文件的句柄,句柄就理解为这个文件 2.通过文件句柄操作文件 3.关闭文件. 1.文件基本操作: f = open('file.txt','r') # ...
- python基础(三)-- 文件操作
一. 文件操作: 对文件操作流程 1.打开文件,得到文件句柄并赋值给一个变量 2.通过句柄对文件进行操作 3.关闭文件 现有文件如下 : Somehow, it seems the love I kn ...
- python3速查参考- python基础 5 -> 常用的文件操作
文件的打开方式 打开方式 详细释义 r 以只读方式打开文件.文件的指针会放在文件的开头.这是默认模式. rb 以二进制只读方式打开一个文件.文件指针会放在文件的开头. r+ 以读写方式打开一个文 ...
- python基础--字符编码以及文件操作
字符编码: 1.运行程序的三个核心硬件:cpu.内存.硬盘 任何一个程序要是想要运算,肯定是先从硬盘加载到当前的内存中,然后cpu根据指定的指令去执行操作 2.python解释器运行一个py文件的步骤 ...
- python基础一 day7 复习文件操作
read()原样输出 读取出来的是字符串类型 readline()输出一行 读取出来的是字符串类型 readlines()把每行文本作为一个字符串存入列表,并返回列表 打开方式: b以bytes类型打 ...
随机推荐
- promise.all的应用场景举例
Promise.all方法 简而言之:Promise.all( ).then( )适用于处理多个异步任务,且所有的异步任务都得到结果时的情况. 比如:用户点击按钮,会弹出一个弹出对话框,对话框中有两部 ...
- Sibel Tools和Siebel Cilent的安装步骤
关于Siebel的资料在网上是少之又少,当时安装开发工具的时候花了挺长时间的,把步骤记录了下来. 一安装win32_11gR2_client 首先要安装Oracle数据库的客户端,必须是32位,安装过 ...
- canal整合springboot实现mysql数据实时同步到redis
业务场景: 项目里需要频繁的查询mysql导致mysql的压力太大,此时考虑从内存型数据库redis里查询,但是管理平台里会较为频繁的修改增加mysql里的数据 问题来了: 如何才能保证mysql的数 ...
- vue中vuex的五个属性和基本用法
VueX 是一个专门为 Vue.js 应用设计的状态管理构架,统一管理和维护各个vue组件的可变化状态(你可以理解成 vue 组件里的某些 data ). Vuex有五个核心概念: state, ge ...
- js 时间戳转换为年月日时分秒的格式
<script type="text/javascript"> var strDate = ''; $(function(){ // 获取时间戳 var nowDate ...
- 深入.NET框架与面向对象的回顾
.NET DOTNET DNET 点NET(.NET框架支持跨语言开发.如C#,VB .NET ,C++.NET,F# ,lronRuby,Others) 任何人,在任何地方,使用任何终端设备,都能访 ...
- 『学了就忘』Linux系统定时任务 — 87、只执行一次的定时任务
目录 1.at服务管理 2.at命令的访问控制 3.at命令 4.其他at管理命令 5.总结 定时任务是在服务器上常用到的一个工作. 在你指定的时间,系统会自动执行你指定的程序(脚本或者命令). Li ...
- LuoguP7505 「Wdsr-2.5」小小的埴轮兵团 题解
Content 给出一个范围为 \([-k,k]\) 的数轴,数轴上有 \(n\) 个点,第 \(i\) 个点的位置为 \(a_i\).有 \(m\) 次操作,有且仅有以下三种: 1 x:所有点往右移 ...
- java 多线程:Thread类;Runnable接口
1,进程和线程的基本概念: 1.什么是进程: 进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础.在早期面向进程设计的计算机 ...
- re正则表达式:import re ;re.search()
http://www.cnblogs.com/alex3714/articles/5161349.html re模块 常用正则表达式符号 1 2 3 4 5 6 7 8 9 10 11 12 13 1 ...