ICCV2021 | Vision Transformer中相对位置编码的反思与改进
前言
在计算机视觉中,相对位置编码的有效性还没有得到很好的研究,甚至仍然存在争议,本文分析了相对位置编码中的几个关键因素,提出了一种新的针对2D图像的相对位置编码方法,称为图像RPE(IRPE)。
本文来自公众号CV技术指南的论文分享系列
关注公众号CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。

代码:https://github.com/microsoft/Cream/tree/main/iRPE
Background
Transformer的核心是self-attention,它能够按顺序对tokens之间的关系进行建模。然而,self-attention有一个固有的缺陷-它不能捕获输入tokens的顺序。因此,合并位置信息的显式表示对于Transformer特别重要,因为模型在其他方面完全不受序列排序的影响,这对于对结构化数据进行建模是不可取的。
transformer位置表示的编码方法主要有两类。一个是绝对的,另一个是相对的。
绝对方法将输入tokens的绝对位置从1编码到最大序列长度。也就是说,每个位置都有单独的编码向量。然后将编码向量与输入Tokens组合,以将位置信息输入给模型。
相对位置方法对输入tokens之间的相对距离进行编码,并学习tokens之间的成对关系。相对位置编码(relative position encoding, RPE)通常通过具有与self-attention模块中的 query 和 key 交互的可学习参数的查询表来计算。这样的方案允许模块捕获Tokens之间非常长的依赖关系。
相对位置编码在自然语言处理中被证明是有效的。然而,在计算机视觉中,这种效果仍然不清楚。最近很少有文献对其进行阐述,但在Vision Transformer方面却得出了有争议的结论。
例如,Dosovitski等人观察到相对位置编码与绝对位置编码相比没有带来任何增益。相反,Srinivaset等人发现相对位置编码可以诱导明显的增益,优于绝对位置编码。此外,最近的工作声称相对位置编码不能和绝对位置编码一样好用。这些工作对相对位置编码在模型中的有效性得出了不同的结论,这促使我们重新审视和反思相对位置编码在Vision Transformer中的应用。
另一方面,语言建模采用原始相对位置编码,输入数据为一维单词序列。但对于视觉任务,输入通常是2D图像或视频序列,其中像素具有高度空间结构。目前尚不清楚:从一维到二维的扩展是否适用于视觉模型;方向信息在视觉任务中是否重要?
Contributions
本文首先回顾了现有的相对位置编码方法,然后针对二维图像提出了新的编码方法。做了以下贡献。
1.分析了相对位置编码中的几个关键因素,包括相对方向、上下文的重要性、query、key、value和相对位置嵌入之间的交互以及计算代价。该分析对相对位置编码有了全面的理解,并为新方法的设计提供了经验指导。
2.提出了一种高效的相对编码实现方法,计算成本从原始O()降低到O(nkd)(其中k<<n),适用于高分辨率输入图像,如目标检测、语义分割等Tokens数可能非常大的场合。
3.综合考虑效率和通用性,提出了四种新的vision transformer的相对位置编码方法,称为image RPE(IRPE)。这些方法很简单,可以很容易地插入self-attention层。实验表明,在不调整任何超参数和设置的情况下,该方法在ImageNet和COCO上分别比其原始模型DeiTS和DETR-ResNet50提高了1.5%(top-1ACC)和1.3%(MAP)。
4.实验证明,在图像分类任务中,相对位置编码可以代替绝对编码。同时,绝对编码对于目标检测是必要的,其中像素位置对于目标定位是重要的。
Methods
首先,为了研究编码是否可以独立于输入嵌入,论文引入了两种相对位置模式:偏置模式(Bias Mode)和上下文模式(Contextual Mode)。与传统的裁剪函数(Clip function)不同,论文提出了一种分段函数(Piecewise function)来将相对位置映射到编码。之后,为了研究方向性的重要性,论文设计了两种非定向方法和两种定向方法。
Bias Mode和Contextual Mode
以前的相对位置编码方法都依赖于输入嵌入。它带来了一个问题,即编码是否可以独立于输入?论文引入了相对位置编码的偏置模式和上下文模式来研究这一问题。前者与输入嵌入无关,后者考虑与query、key或value的交互。
用一个统一的公式来表示,即

其中b_ij是2D相对位置编码,用来定义偏置或上下文模式。
对于偏置模式,b_ij = r_ij,其中r_ij是可学习标量,并且表示位置i和j之间的相对位置权重。
对于上下文模式,

其中r_ij是与query嵌入交互的可训练向量。上下文模式有多个变体,这里不一一例举,有需要者请看论文。
Piece Index Function
在描述二维相对位置权值之前,首先引入一个多对一函数,将一个相对距离映射为有限集合中的一个整数,然后以该整数为索引,在不同的关系位置之间共享编码。这样的索引函数可以极大地减少长序列(例如高分辨率图像)的计算成本和参数数量。
尽管在[18]中使用的裁剪函数h(X)=max(−β,min(β,x))也降低了成本,但是将相对距离大于β的位置分配给相同的编码。这种方法不可避免地遗漏了远程相对位置的上下文信息。
论文引入了一个分段函数g(x):R→{y∈Z|−β≤y≤β},用于索引到相应编码的相对距离。该函数基于一个假设,即较近的邻居比较远的邻居更重要,并通过相对距离来分配注意力。它表示为

其中[·]是舍入运算,Sign()确定数字的符号,即正输入返回1,负输入返回-1,反之返回0。α确定分段点,β控制输出在[−β,β]范围内,γ调整对数部分的曲率。
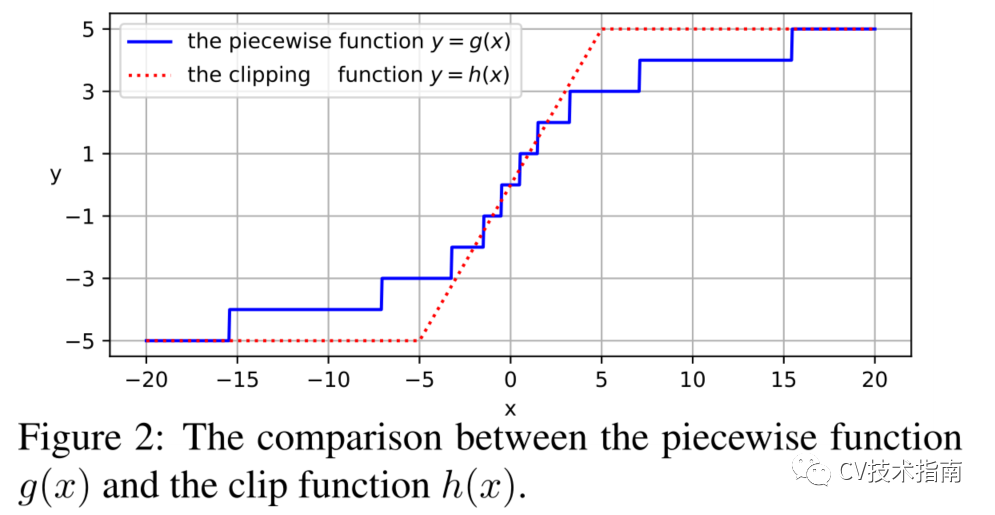

将分段函数h(X)与剪裁函数h(X)=min(−β,max(β,x))进行比较。在图2中,裁剪函数h(X)分布均匀的注意力,省略远距离的位置,但分段函数g(x)根据相对距离分布不同的注意力水平。作者认为应该保留远程位置的潜在信息,特别是对于高分辨率图像或需要远程特征依赖的任务,因此选择g(X)来构造映射方法。
2D相对位置计算
1.欧氏距离方法(Euclidean Method):计算两个相对位置的欧氏距离,将距离通过一个可学习的偏置标量或上下文向量映射到相应的编码。
2.量化方法(Quantization Method ):在上述欧氏距离方法中,较近的两个相对距离不同的邻居可以映射到同一个索引中,例如二维相对位置(1,0)和(1,1)都映射到索引1中,而应该将最近的邻居分开。因此,需要将欧式距离量化,即不同的实数映射成不同的整数。

quant(·)将一组实数{0,1,1.41,2,2.24,...}映射为一组整数{0,1,2,3,4,...}。此方法也是非定向的。
3.交叉法(Cross Method)。像素的位置方向对图像也很重要,因此提出了有向映射方法。这种方法被称为Cross方法,它分别在水平和垂直方向上计算编码,然后对它们进行汇总。该方法如下给出,

其中p˜xi(i,j)和p˜yi(i,j)在偏置模式下都是可学习标量,或者在上下文模式下都是可学习向量。与SASA中的编码类似,相同的偏移量在x轴或y轴上共享相同的编码,但主要区别在于我们使用分段函数根据相对距离来分配注意力。
4.乘积法(Product Method)。如果一个方向上的距离相同,无论是水平距离还是垂直距离,交叉方法都会将不同的相对位置编码到同一嵌入中。此外,交叉法带来额外的计算开销。为了提高效率和包含更多的方向性信息,论文设计了乘积方法,其公式如下

一个高效的实现方法
在上下文模式中,以上所有的方法都有一个共同的部分:。
计算这个部分需要时间复杂度O(),其中n和d分别表示输入序列的长度和特征通道的数目。由于I(i,j)的多对一特性,集合I(i,j)的大小K通常小于vision transformer。因此,论文提供如下高效实现:

它花费O(nkd)的时间复杂度预计算所有的z_i,t,然后通过映射t=i(i,j)将zi_,t赋给那个共同表达式。赋值运算的时间复杂度为O(N^2),其代价比预计算过程小得多。因此,相对位置编码的计算成本也从原来的 O() 降低到 O(nkd)。
Conclusion
1. 四种方法的两种模式之间的比较。

在vision transformer中,有向方法(交叉和乘积)通常比无向方法(欧式距离和量化)表现得更好。这一现象说明了方向性对于vision transformer是很重要的,因为图像像素具有高度的结构化和语义相关性。
无论使用哪种方法,上下文模式都实现了优于偏置模式的性能。潜在的原因可能是上下文模式改变了带有输入特征的编码,而偏置模式保持静态。
2.相对位置编码可以在不同头部之间共享或不共享的结果比较。

对于偏置模式,当在头部之间共享编码时,准确度会显著下降。相比之下,在上下文模式下,两个方案之间的性能差距可以忽略不计。这两种方法的平均TOP-1准确率都达到了80.9%。
论文推测,不同的头部需要不同的相对位置编码(RPE)来捕捉不同的信息。在上下文模式下,每个头部可以通过公式计算自己的RPE。当处于偏置模式时,共享RPE强制所有头部对patches给予相同的关注。
3.分段函数和裁剪函数的比较

在图像分类任务中,这两个函数之间的性能差距非常小,甚至可以忽略不计。然而,在目标检测任务中,裁剪函数比分段函数差。其根本原因在于,当序列长度较短时,这两个函数非常相似。分段函数是有效的,特别是当序列大小远远大于buckets的数量时。(注:作者把P_I(i,j)作为一个bucket(桶),用于存储相对位置权重)
与分类相比,目标检测使用分辨率高得多的输入,导致输入序列长得多。因此,推测当输入序列较长时,应该使用分段函数,因为它能够将不同的注意力分配到距离相对较大的位置,而当相对距离大于β时,裁剪函数分配相同的编码。
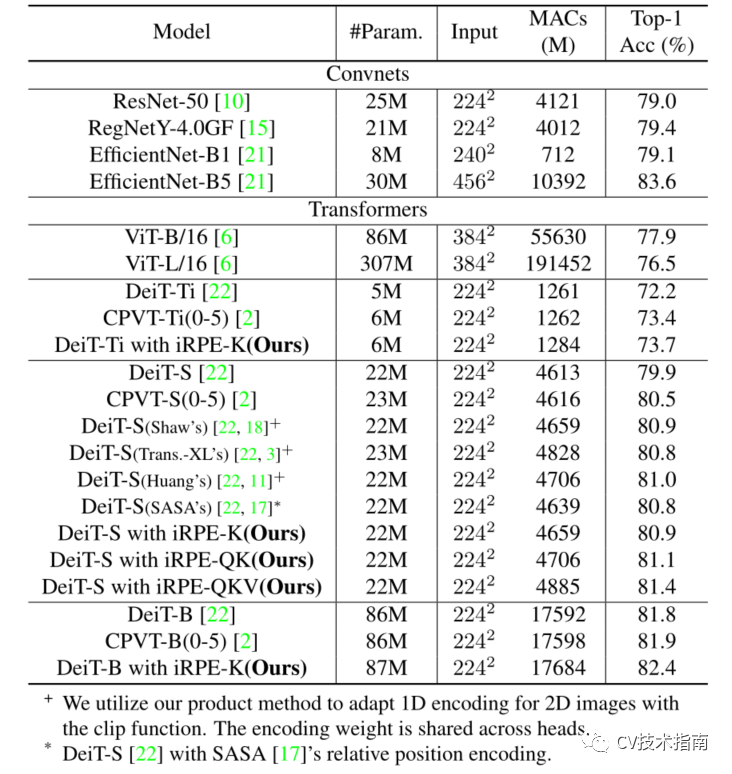
4.在ImageNet上与其它SOTA模型的比较
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “入门指南“可获取计算机视觉入门所有必备资料

其它文章
ICCV2021 | TransFER:使用Transformer学习关系感知的面部表情表征
图像修复必读的 10 篇论文| HOG和SIFT图像特征提取简述
全面理解目标检测中的anchor| 实例分割综述总结综合整理版
单阶段实例分割综述| 小目标检测的一些问题,思路和方案
视觉Transformer综述| 2021年小目标检测最新研究综述
Siamese network综述| 姿态估计综述| 语义分割综述
CVPR2021 | SETR: 使用 Transformer 从序列到序列的角度重新思考语义分割
视频理解综述:动作识别、时序动作定位、视频Embedding
ICCV2021 | MicroNet:以极低的 FLOPs 改进图像识别
ICCV2021 | 重新思考视觉transformers的空间维度
CVPR2021 | TransCenter: transformer用于多目标跟踪算法
CVPR2021 | TimeSformer-视频理解的时空注意模型
经典论文系列 | Group Normalization & BN的缺陷
经典论文系列 | 目标检测--CornerNet & 又名 anchor boxes的缺陷
经典论文系列 | 缩小Anchor-based和Anchor-free检测之间差距的方法:自适应训练样本选择
ICCV2021 | Vision Transformer中相对位置编码的反思与改进的更多相关文章
- ICCV2021 | 渐进采样式Vision Transformer
前言 ViT通过简单地将图像分割成固定长度的tokens,并使用transformer来学习这些tokens之间的关系.tokens化可能会破坏对象结构,将网格分配给背景等不感兴趣的区域,并引 ...
- ICCV2021 | Tokens-to-Token ViT:在ImageNet上从零训练Vision Transformer
前言 本文介绍一种新的tokens-to-token Vision Transformer(T2T-ViT),T2T-ViT将原始ViT的参数数量和MAC减少了一半,同时在ImageNet上从 ...
- ICCV2021 | Swin Transformer: 使用移位窗口的分层视觉Transformer
前言 本文解读的论文是ICCV2021中的最佳论文,在短短几个月内,google scholar上有388引用次数,github上有6.1k star. 本文来自公众号CV技术指南的论文分享系 ...
- 中文NER的那些事儿5. Transformer相对位置编码&TENER代码实现
这一章我们主要关注transformer在序列标注任务上的应用,作为2017年后最热的模型结构之一,在序列标注任务上原生transformer的表现并不尽如人意,效果比bilstm还要差不少,这背后有 ...
- 第五课第四周实验一:Embedding_plus_Positional_encoding 嵌入向量加入位置编码
目录 变压器预处理 包 1 - 位置编码 1.1 - 位置编码可视化 1.2 - 比较位置编码 1.2.1 - 相关性 1.2.2 - 欧几里得距离 2 - 语义嵌入 2.1 - 加载预训练嵌入 2. ...
- 【译】在Transformer中加入相对位置信息
目录 引言 动机 解决方案 概览 注释 实现 高效实现 结果 结论 参考文献 本文翻译自How Self-Attention with Relative Position Representation ...
- [NLP] 相对位置编码(一) Relative Position Representatitons (RPR) - Transformer
对于Transformer模型的positional encoding,最初在Attention is all you need的文章中提出的是进行绝对位置编码,之后Shaw在2018年的文章中提出了 ...
- [NLP] 相对位置编码(二) Relative Positional Encodings - Transformer-XL
参考: 1. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context https://arxiv.org/pdf ...
- 浅析白盒审计中的字符编码及SQL注入
尽管现在呼吁所有的程序都使用unicode编码,所有的网站都使用utf-8编码,来一个统一的国际规范.但仍然有很多,包括国内及国外(特别是非英语国家)的一些cms,仍然使用着自己国家的一套编码,比如g ...
随机推荐
- 架构师必备:MySQL主从同步原理和应用
日常工作中,MySQL数据库是必不可少的存储,其中读写分离基本是标配,而这背后需要MySQL开启主从同步,形成一主一从.或一主多从的架构,掌握主从同步的原理和知道如何实际应用,是一个架构师的必备技能. ...
- 零基础怎么学Java?Java的运行机制是什么?Java入门基础!
Java语言是当前流行的一种程序设计语言,因其安全性.平台无关性.性能优异等特点,受到广大编程爱好者的喜爱. 想学习Java语言的同学对于Java的运行机制是必须要了解的!! 计算机高级语言的类型主要 ...
- HDC 2021 | HMS Core 6.0:连接与通信论坛,为App打造全场景连接体验
如何在弱网环境下让用户享受无中断沉浸体验? 如何在全场景互联中让多设备交互如丝般顺滑? 如何在无网区域让移动终端发出紧急求助信息? 连接无处不在,连接与体验息息相关!流畅的网络体验已成为应用开发的关键 ...
- Python中pymongo find 遍历数据导致timeout
背景 在读取大约200W左右的数据的时候采用游标形式进行数据遍历时,超过10分钟就报错 timeout 原因 pymongo游标会在10分钟之后被关闭 解决方案 db.find({}, no_curs ...
- 内网渗透DC-3靶场通关
个人博客:点我 DC系列共9个靶场,本次来试玩一下DC-3,只有1个flag,下载地址. 下载下来后是 .ova 格式,建议使用vitualbox进行搭建,vmware可能存在兼容性问题.靶场推荐使用 ...
- Kubernetes-Service介绍(三)-Ingress(含最新版安装踩坑实践)
前言 本篇是Kubernetes第十篇,大家一定要把环境搭建起来,看是解决不了问题的,必须实战. Kubernetes系列文章: Kubernetes介绍 Kubernetes环境搭建 Kuberne ...
- 初始HTML05
HTML 表单控件属性 表单控件可设置以下标签属性 属性名 取值 type 设置控件类型 name 设置控件名称,最终与值一并发送给服务器 value 设置控件的值 placeholder 设置输入框 ...
- Django+Vue跨域配置与经验
一.原理 同源?同源策略? 同源的定义是:两个页面的协议.端口和域名都相同 同源的例子: 不同源的例子: 同源策略SOP(Same origin policy)是一种浏览器约定,它是浏览器最核心也最基 ...
- 基于自定义Validator来验证枚举类型
基于自定义Validator来验证枚举类型 一.背景 二.技术要点 三.实现一个自定义枚举校验. 1.需求. 2.实现步骤 1.自定义一个 Sex 枚举. 2.自定义一个 Enum 注解 3.编写具体 ...
- Golang通脉之并发初探
并发是编程里面一个非常重要的概念,Go语言在语言层面天生支持并发. 并发与并行 并发:同一时间段内执行多个任务. 并行:同一时刻执行多个任务,有时间上的重叠. 进程.线程.协程 进程(Process) ...