Python爬虫之lxml-etree和xpath的结合使用
本篇文章给大家介绍的是Python爬虫之lxml-etree和xpath的结合使用(附案例),内容很详细,希望可以帮助到大家。
lxml:python的HTML / XML的解析器
官网文档:https://lxml.de/
使用前需要安装lxml包
终端输入(win7.8,10在cmd输入)pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lxml
功能:
1 解析html:使用etree.html(text)将字符串格式的 html片段解析成 html 文档
2 读取xml文件
3 etree和xpath配合使用(本文主要介绍)
示例:etree和xpath配合使用
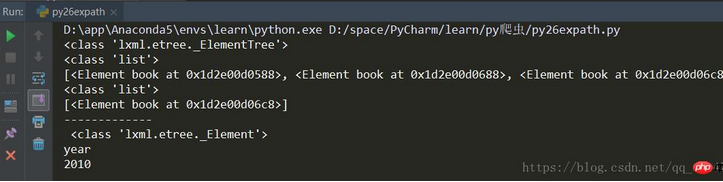
# lxml-etree读取文件from lxml import etree
xml = etree.parse("./py24.xml")
print(type(xml))# 查找所有 book 节点rst = xml.xpath('//book')
print(type(rst))
print(rst)# 查找带有 category 属性值为 sport 的元素rst2 = xml.xpath('//book[@category="sport"]')
print(type(rst2))
print(rst2)# 查找带有category属性值为sport的元素的book元素下到的year元素rst3 = xml.xpath('//book[@category="sport"]/year')
rst3 = rst3[0]
print('-------------\n',type(rst3))
print(rst3.tag)
print(rst3.text)结果:
示例:使用lxml解析html代码
# 先安装lxml
# 用 lxml 来解析HTML代码
from lxml import etree
text = '''<p>
<ul>
<li class="item-0"><a href="0.html">item 0 </a></li>
<li class="item-1"><a href="1.html">item 1 </a></li>
<li class="item-2"><a href="2.html">item 2 </a></li>
<li class="item-3"><a href="3.html">item 3 </a></li>
<li class="item-4"><a href="4.html">item 4 </a></li>
<li class="item-5"><a href="5.html">item 5 </a></li>
</ul> </p>'''
# 利用 etree.HTML 把字符串解析成 HTML 文件
html = etree.HTML(text)
s = etree.tostring(html).decode()
print(s)结果:

示例:读取xml文件
# lxml-etree读取文件from lxml import etree
xml = etree.parse("./py24.xml")
sxml = etree.tostring(xml, pretty_print=True)
print(sxml)结果:

Python爬虫之lxml-etree和xpath的结合使用的更多相关文章
- 小白学 Python 爬虫(20):Xpath 进阶
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(19):Xpath 基操
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 爬虫之lxml - etree - xpath的使用
# 解析原理: # - 获取页面源码数据 # - 实例化一个etree对象,并且将页面源码数据加载到该对象中 # - 调用该对象的xpath方法进行指定标签定位 # - xpath函数必须结合着xpa ...
- python爬虫入门(三)XPATH和BeautifulSoup4
XML和XPATH 用正则处理HTML文档很麻烦,我们可以先将 HTML文件 转换成 XML文档,然后用 XPath 查找 HTML 节点或元素. XML 指可扩展标记语言(EXtensible Ma ...
- Python 爬虫 解析库的使用 --- XPath
一.使用XPath XPath ,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言.它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索. 所 ...
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
- Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢.本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快. 本次爬取的豆瓣书籍排行榜的首页地 ...
- python爬虫三大解析库之XPath解析库通俗易懂详讲
目录 使用XPath解析库 @(这里写自定义目录标题) 使用XPath解析库 1.简介 XPath(全称XML Path Languang),即XML路径语言,是一种在XML文档中查找信息的语言. ...
- Python爬虫:数据解析 之 xpath
资料: W3C标准:https://www.w3.org/TR/xpath/all/ W3School:https://www.w3school.com.cn/xpath/index.asp 菜鸟教程 ...
- Python爬虫教程-22-lxml-etree和xpath配合使用
Python爬虫教程-22-lxml-etree和xpath配合使用 lxml:python 的HTML/XML的解析器 官网文档:https://lxml.de/ 使用前,需要安装安 lxml 包 ...
随机推荐
- excel VBA根据一列的逗号隔开值分行
Sub test1() Dim h Dim j As Integer j = 0 Dim n1 As Integer '分行单元格在第几列 Dim m1 As Integ ...
- Maven项目无法下载JAR包,输入mvn help:system出现No plugin found for prefix 'help' in the current project and in the plugin groups的解决方案
这个问题困扰了我很久,一直无法解决:我在虚拟机里面按照同样的步骤配置了三次maven项目,每次都能成功:可一旦到外面maven项目总是创建失败,输入mvn help:system总是出现No plug ...
- DDoS攻击的工具介绍
1.低轨道离子加农炮(LOIC) 1.1 什么是低轨道离子加农炮(LOIC)? 低轨道离子加农炮是通常用于发起DoS和DDoS攻击的工具.它最初是由Praetox Technology作为网络压力测试 ...
- 9.6、zabbix监控总结
1.自动发现和自动注册的区别: (1)自动发现: 1)用于zabbix-agent的被动模式,是zabbix-server主动去添加主机.在web上创建自动发现的规则 后,zabbix-server会 ...
- 2020牛客NOIP赛前集训营-普及组(第二场) 题解
目录 T1 面试 描述 题目描述 输入描述: 输出描述: 题解 代码 T2 纸牌游戏 描述 题目描述 输入描述: 输出描述: 题解 代码 T3 涨薪 描述 题目描述 输入描述: 输出描述: 题解 代码 ...
- echarts 根据geojson 数据绘制区域图(精确到镇)
步骤:1)先获取区域(县.镇)json数据 :2)使用echarts 绘制地图: 先上一波效果图(昆明市东川区) 一.获取区域json数据 1.下载工具"水经微图", 2.下载东川 ...
- Linux基础 -03
2.2.3 head-tail 命令 #------head #head pass #查看头部内容,默认前10行 #head -n5 pass #查看头部前5行,使用-n指定 #-------tail ...
- SpringBoot中如何监听两个不同源的RabbitMQ消息队列
spring-boot如何配置监听两个不同的RabbitMQ 由于前段时间在公司开发过程中碰到了一个问题,需要同时监听两个不同的rabbitMq,但是之前没有同时监听两个RabbitMq的情况,因此在 ...
- mysql日期时间处理
获得当前周的周一到周日 select subdate(curdate(),date_format(curdate(),'%w')-1)//获取当前日期在本周的周一 select subdate(c ...
- Xshell怎么连接数据库
之前一直用Navicat Premium链接数据库,其实在xshell也可以链接数据库,本文将先介绍如何用xshell链接数据库的方法. 1.打开xshell,连接上 输入指令:mysql -h 19 ...