Python爬虫之lxml-etree和xpath的结合使用
本篇文章给大家介绍的是Python爬虫之lxml-etree和xpath的结合使用(附案例),内容很详细,希望可以帮助到大家。
lxml:python的HTML / XML的解析器
官网文档:https://lxml.de/
使用前需要安装lxml包
终端输入(win7.8,10在cmd输入)pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lxml
功能:
1 解析html:使用etree.html(text)将字符串格式的 html片段解析成 html 文档
2 读取xml文件
3 etree和xpath配合使用(本文主要介绍)
示例:etree和xpath配合使用
# lxml-etree读取文件from lxml import etree
xml = etree.parse("./py24.xml")
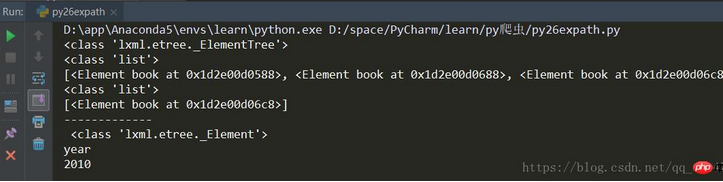
print(type(xml))# 查找所有 book 节点rst = xml.xpath('//book')
print(type(rst))
print(rst)# 查找带有 category 属性值为 sport 的元素rst2 = xml.xpath('//book[@category="sport"]')
print(type(rst2))
print(rst2)# 查找带有category属性值为sport的元素的book元素下到的year元素rst3 = xml.xpath('//book[@category="sport"]/year')
rst3 = rst3[0]
print('-------------\n',type(rst3))
print(rst3.tag)
print(rst3.text)结果:
示例:使用lxml解析html代码
# 先安装lxml
# 用 lxml 来解析HTML代码
from lxml import etree
text = '''<p>
<ul>
<li class="item-0"><a href="0.html">item 0 </a></li>
<li class="item-1"><a href="1.html">item 1 </a></li>
<li class="item-2"><a href="2.html">item 2 </a></li>
<li class="item-3"><a href="3.html">item 3 </a></li>
<li class="item-4"><a href="4.html">item 4 </a></li>
<li class="item-5"><a href="5.html">item 5 </a></li>
</ul> </p>'''
# 利用 etree.HTML 把字符串解析成 HTML 文件
html = etree.HTML(text)
s = etree.tostring(html).decode()
print(s)结果:

示例:读取xml文件
# lxml-etree读取文件from lxml import etree
xml = etree.parse("./py24.xml")
sxml = etree.tostring(xml, pretty_print=True)
print(sxml)结果:

Python爬虫之lxml-etree和xpath的结合使用的更多相关文章
- 小白学 Python 爬虫(20):Xpath 进阶
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(19):Xpath 基操
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 爬虫之lxml - etree - xpath的使用
# 解析原理: # - 获取页面源码数据 # - 实例化一个etree对象,并且将页面源码数据加载到该对象中 # - 调用该对象的xpath方法进行指定标签定位 # - xpath函数必须结合着xpa ...
- python爬虫入门(三)XPATH和BeautifulSoup4
XML和XPATH 用正则处理HTML文档很麻烦,我们可以先将 HTML文件 转换成 XML文档,然后用 XPath 查找 HTML 节点或元素. XML 指可扩展标记语言(EXtensible Ma ...
- Python 爬虫 解析库的使用 --- XPath
一.使用XPath XPath ,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言.它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索. 所 ...
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
- Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢.本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快. 本次爬取的豆瓣书籍排行榜的首页地 ...
- python爬虫三大解析库之XPath解析库通俗易懂详讲
目录 使用XPath解析库 @(这里写自定义目录标题) 使用XPath解析库 1.简介 XPath(全称XML Path Languang),即XML路径语言,是一种在XML文档中查找信息的语言. ...
- Python爬虫:数据解析 之 xpath
资料: W3C标准:https://www.w3.org/TR/xpath/all/ W3School:https://www.w3school.com.cn/xpath/index.asp 菜鸟教程 ...
- Python爬虫教程-22-lxml-etree和xpath配合使用
Python爬虫教程-22-lxml-etree和xpath配合使用 lxml:python 的HTML/XML的解析器 官网文档:https://lxml.de/ 使用前,需要安装安 lxml 包 ...
随机推荐
- 【NX二次开发】Block UI NXOpen::BlockStyler::BlockDialog
定义: NXOpen::BlockStyler::BlockDialog* theDialog; theDialog->PerformApply();//执行应用并重新启动对话框. theDia ...
- DOS命令行(9)——wmic-系统管理命令行工具
wmic 介绍与语法 WMI(Windows Management Instrumentation,Windows 管理规范)是一项核心的 Windows 管理技术:用户可以使用 WMI 管理本地和远 ...
- 《手把手教你》系列基础篇之(二)-java+ selenium自动化测试-环境搭建(下)基于Maven(详细教程)
1.简介 Apache Maven是一个软件项目管理和综合工具.基于项目对象模型(POM)的概念,Maven可以从一个中心资料片管理项目构建,报告和文件.由于现在企业和公司中Java的大部分项目都是基 ...
- 合肥某小公司面试题:Spring基础
<对线面试官>系列目前已经连载25篇啦!有深度风趣的系列! [对线面试官]Java注解 [对线面试官]Java泛型 [对线面试官] Java NIO [对线面试官]Java反射 & ...
- 使用echarts时,鼠标首次移入屏幕会闪动,全屏会出现滚动条
原因: 在echarts图表中出现tooltip时,画布的父标签(即:echarts.init()的标签)的有时宽高都会发生变化,导致相对布局的div可能大小发生变化(画布大小却不变),导致页面闪动. ...
- DHCP的简单介绍与配置
一.DHCP简介 二.DHCP报文类型 三.DHCP工作原理 四.实例操作 一.DHCP简介 DHCP(Dynamic Host Configuration Protocol),动态主机配置协议,是一 ...
- .Net Core 3.1简单搭建微服务
学如逆水行舟,不进则退!最近发现微服务真的是大势所趋,停留在公司所用框架里已经严重满足不了未来的项目需要了,所以抽空了解了一下微服务,并进行了代码落地. 虽然项目简单,但过程中确实也学到了不少东西. ...
- 29、Tomcat只允许指定域名访问,禁用IP地址访问,防止恶意解析
1.1.测试环境说明: Linux版本:7.6 IP地址:10.11.220.123/24 Tomcat版本:tomcat-8.5.37(端口号为8080) Jdk版本:1.8.0_202 1.2.配 ...
- LCA总结
作为一名合格的 OIer ,一定要有自我总结的意识,一定要通过写博客的方式来验证自己的掌握程度 ----沃.茨基硕德 目录 作为一名合格的 OIer ,一定要有自我总结的意识,一定要通过写博客的方式来 ...
- AcWing 1303. 斐波那契前 n 项和
输出斐波那契数列前 n 项和 对m取摸的结果 #include<bits/stdc++.h> #define LL long long #define N 3 using namespac ...