机器学习基石(台湾大学 林轩田),Lecture 1: The Learning Problem

课程的讲授从logo出发,logo由四个图案拼接而成,两个大的和两个小的。比较小的两个下一次课程就可能会解释到它们的意思,两个大的可能到课程后期才会解释到它们的意思(提示:红色代表使用机器学习危险,蓝色代表使用机器学习不危险)。

机器学习是理论与实践相结合的一门学问。要怎么学习机器学习课程?我们可以从很理论的角度出发:机器学习有什么推论什么结论,它可以设计出什么样的东西,我们可以非常深入的了解这些相关知识。然后,我们感叹,哇~ 这些前辈好伟大,怎么可以设计出这么漂亮的数学,这么漂亮的东西。可是,对于大多数人来说,比如你现在想到的是,你要把机器学习应用到某个应用的领域或者其它题目上,可能会觉得学习这些理论不够实用。好,那既然要实用,我们可不可以学习许多机器学习方法,每天都有几十个几百个新的方法在产生,我们可不可以从这些方法中选择最棒、最有趣的几十个方法来学(每堂课学习一两个,十几堂课下来,可以学习几十个方法)。当然可以,但是,当我们这样快速的学完几十个方法,到有朝一日,我们要使用这些方法的时候,你发现,糟糕了,我不知道怎么样选择,我不知道怎么样妥善的使用这些方法。就好比武侠小说里,你学了太多的招数以后,真正上战场的时候,你不知道要用上哪一招。所以,从理论的角度切入,或者从方法的角度切入,都有显而易见的缺点。本课程的选择,是从基础(foundation)开始切入。

什么叫基础?林轩田老师从多年的教授课程和同其他学者讨论得出,有一些东西例如说,包括哲学上机器学习的思想,包括数学上的工具,包括演算法的设计以及包括它们的使用,这些基础的东西,是每一个想要使用机器学习的人都应该要会的东西。会了这些东西你就能够掌握机器学习,把它变成你的工具,而不是你是它的奴隶。这些基础的东西——基石,基石是一个很坚固,是一个打底的工作,并不代表它真的很简单。基础打好了,你才可以拿这些东西来盖大楼。从一个听故事的角度来听这个课程,课程讲授往往是从一个问题出发,来阐述什么时候可以用得上机器学习?在这些时候,为什么机器学习会有用?这些可能都是一些比较理论的部分,但是,有了这些为什么以后,我们就可以很轻易的了解机器学习里面一些基本的方法以及道理。机器怎么样可以学到东西呢?我们进一步了解了这些方法之后,我们可能还想要做的更好。所以我们说,怎样让机器能够学得更好?我们的故事会沿着这四个(When、Why、How、Better)主题发展下来,每个主题不是单一的,并不是说这是一个理论的主题,或这是一个方法的主题,或者是一个应用的主题。实际上,就算在学习最理论的东西的时候,像在第二个主题(Why)里面,我们也会穿插说这些理论背后的这个哲学意思是什么。我们在讲一个最应用的主题,像这个第四个部分的时候——它是一个非常应用的主题,我们也会讲,这些应用背后的理论基础是什么。我们希望通过各个主题交错讲解的过程,然后是整个的故事,能够学好这个故事以后,未来,如果你要想把机器学习拿到你有兴趣的领域里面去应用,你可以很容易做。如果你想要更钻研机器学习里面更深入的理论,你可以很容易做。如果你想要学习机器学习里面更多的技巧的话,你可以很容易做。

台湾大学的该课程有15到17周的课程,每个礼拜大概2~3小时的课程。纯英语授课,并且是用白板或黑板即时写字的方式来做教学。从图中大家可以看到,电脑科学(大陆译:计算机科学)的computer science的学生最多,也有电机系和生物系的学生。对于大多数想要在Coursera上修课的同学来说,实在是太长了。所以我们把它切成两个部分,前8周我们讲的是foundation,就是基础切入部分,也就是机器学习基石这门课。后7周的课,会在Coursera上开另一门机器学习技法(machine learning techniques)课,如果你修完机器学习基石课程,有兴趣学更多machine learning的技巧的话,欢迎你继续修机器学习技法课程。

该课程有许多机制可以与学生互动,上边Fun Time就是其中之一。与该课程有关的叙述何者为真?
- 台语教学
- 建立像星际迷航里data那样的机器人技术
- 课程持续15周
- 课程像讲故事一样,告诉你机器学习背后的故事

正确选项4,我们用中文华语教学;暂时还没有办法教大家很复杂的技术,怎么样制作那样子的机器人,实际上,这还是一个研究中的领域;我们的课程不是总共15周长,而是8周长,如果你选择继续下一门课程的话,总共15周,你可以得到完整的台湾大学的经验。我们的课的确会用像讲故事的方式跟大家讲说,机器学习是怎么一回事儿。现在,就让我们一起来开始这个机器学习的故事。

我们什么时候用(使用者的角度)机器学习?我一开始跟大家介绍机器学习这个问题,到底什么是机器学习,它还有哪些应用,然后它里面有哪些重要的原件,最后,我们也会想办法和大家澄清机器学习,以及其它相关领域的关系。
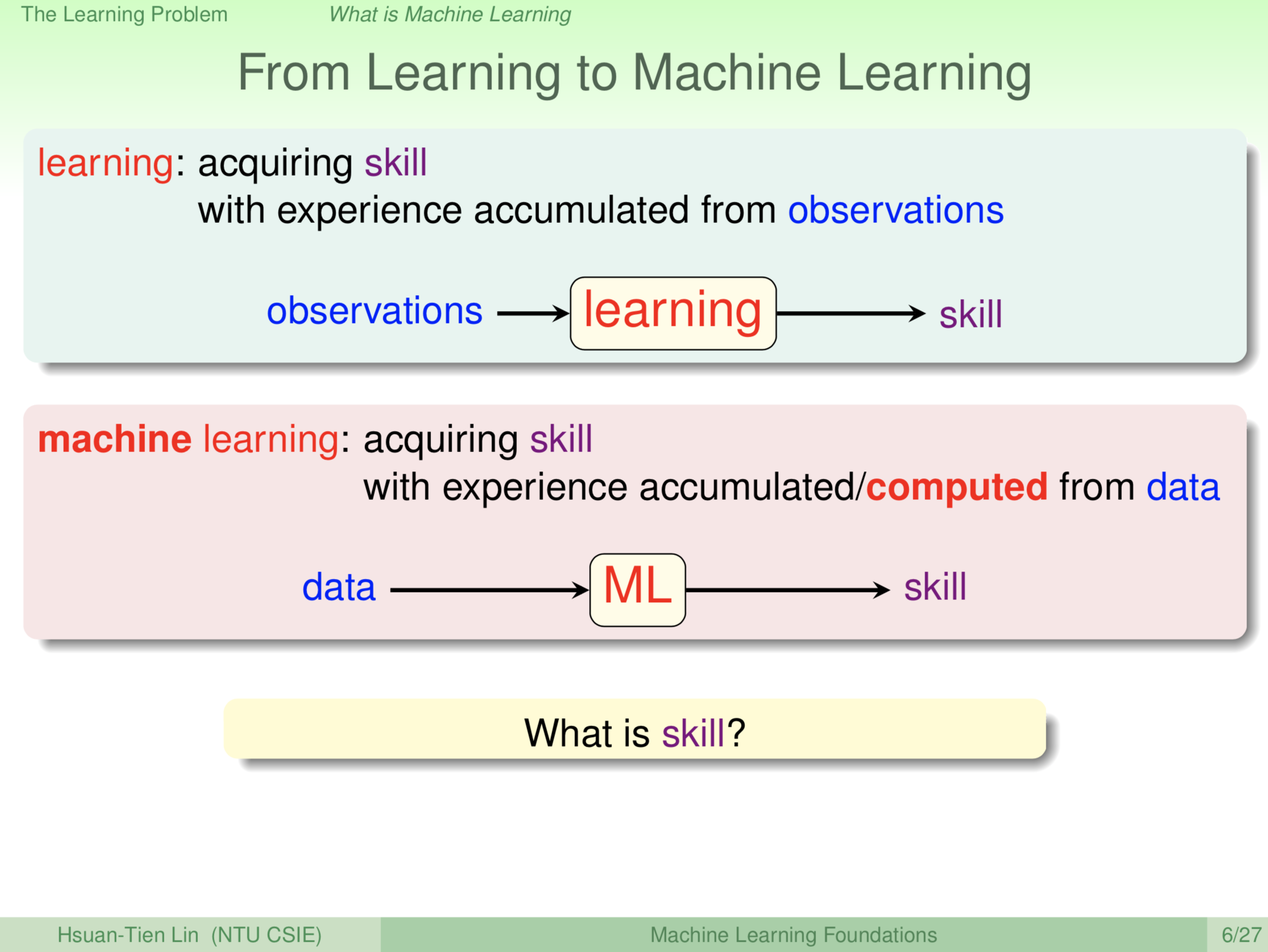
好,所以我们开始机器学习之前,我想请大家先想一想到底什么是学习?好,例如说现在大家听我上课,这是一个学习的过程,你听到我讲什么,也许看到我投影片做的什么,然后你脑袋里想啊想啊,然后最后变成你学到的知识。又或者从我们很小很小的时候就开始学习,像我女儿,我女儿现在很小,她刚开始学讲话,所以她听她身旁的人,也许是我,也许是其他照顾她的人,怎么讲话,然后跟着咿咿呀呀地讲,然后最后她学到了怎么样讲话,怎样跟人沟通的方式。又或者我们看一本书,书里写着说,到底有哪些知识等等,看完这本书以后经过我们脑袋里的转化,变成我们会的知识,也许是数学也许是英文等等不一样的知识。所以从这些各式各样不同的学习的历程或学习的方式里面,我们可以看到学习的其中一个共通性是,我们可以想像,学习是从观察出发,听觉是一种观察,视觉是一种观察,也许甚至有更多例如说嗅觉或触觉都是一种观察,从这些观察出发,然后经过我们脑袋的内化转化的过程,最后变成有用的技巧,有用的技能。这是一个学习的过程,例如说我们看书,看,这个视觉是一种观察,然后最后我们学到了技巧,也许是数学,也许是英文,也许是其它科目。所以这是我们脑袋里的学习,人类或者是其他生物的学习大体上都可以被这个大大的框架涵盖进去。就是说我们从观察,学习的过程,最后转化成有用的技巧,大部分的时候,例如说对于生物界来说,可能就是生存的技巧。机器学习这个名词很大,但是说穿了,只是我们希望用电脑来模拟或模仿类似的过程。也就是现在我们学习的主体不再是人或者其他生物,而是我们的电脑,电脑也是经过一番观察,对环境的观察,然后最后把它变成对电脑来说有用的技能,这样讲好像还是很空泛。电脑的观察是什么?通常我们把电脑观察到的东西(这个观察可能是我们主动喂给电脑的东西,或者电脑想办法得到的东西),观察到的东西,我们通常把它叫做资料。所以,一个机器学习的演算法可以想成,电脑把这些资料拿来,然后经过一番处理,对应到人类的思考过程,我们的脑袋转呀转对应电脑里面的硬碟转呀转,或者CPU转呀转,然后之后变成有用的技巧。机器学习说穿了,就是这个模拟或模仿的这样的过程。讲到这里大家就会想,你说技巧技巧,到底什么是技巧?
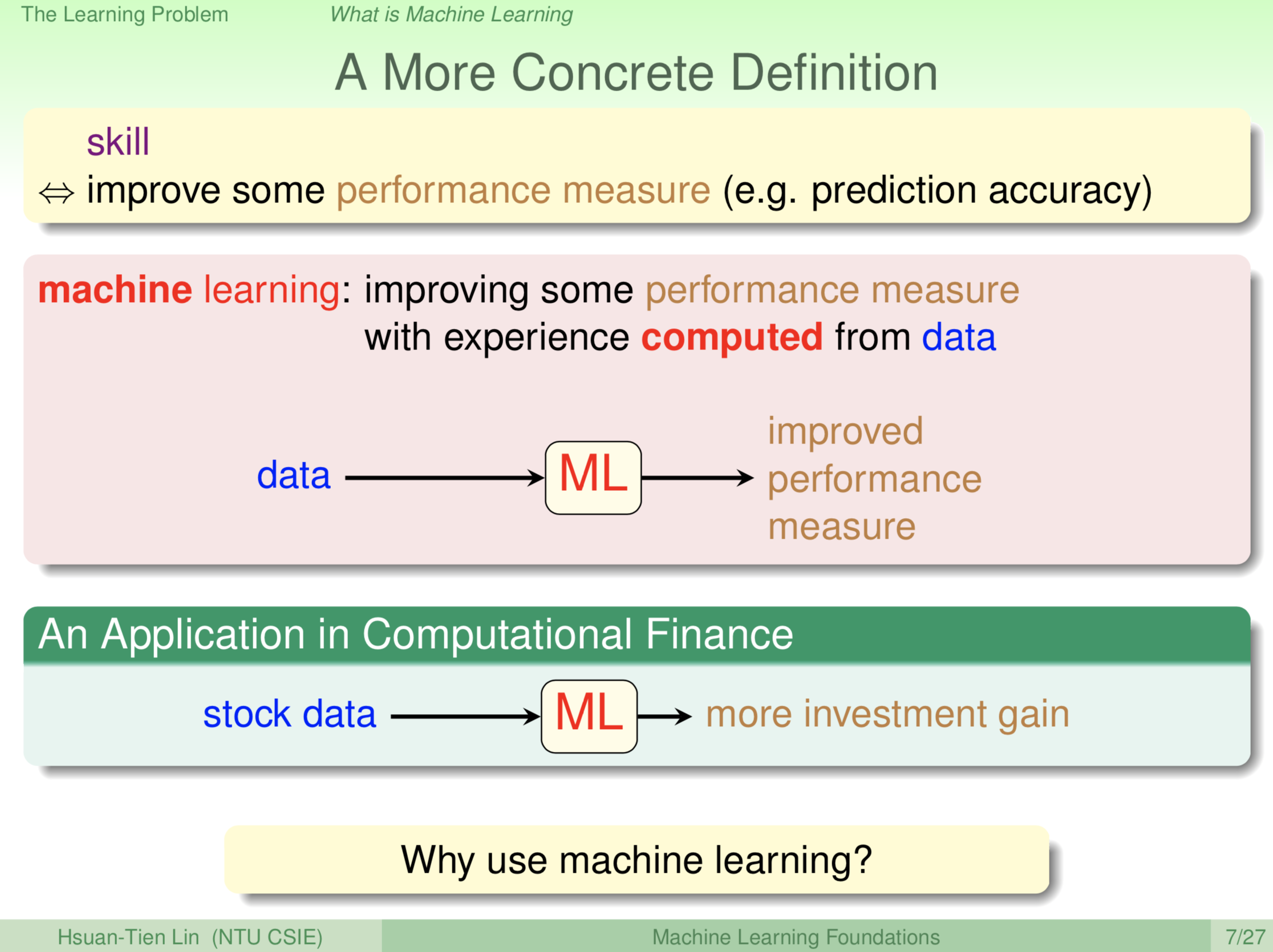
技巧是什么呢?我们可以给技巧再做一个稍微具体一点的定义。技巧实际上是我们想要做的事情的某一种表现的增进。例如说,我们学会了数学,我们的计算就更正确,我们做证明题的时候就更正确;我们学了英文,也许英文就讲的更好;我们学了说话,也许会说的字就更多等。所以有某一种表现的增进,数学的表现增进,英文的表现增进,说话的表现增进。这就是我们说学到了一个技巧。那对于电脑来说,也许我们之后会跟大家介绍说各种各样不同的工作想让电脑做,然后通过机器学习的过程,如果它在这个工作上的表现变好,例如说我们要电脑去预测股票,预测的表现变好了,那我们就说电脑是学到了东西。所以,通过机器学习的过程,我们想要学到的技巧实际上是某一种表现的增进,所以我们就可以把我们刚才的这个示意图,更进一步的去讲说,机器学习的过程是从资料出发,然后经过电脑的计算之后,最终得到某一种表现的增进。例如说,我刚才讲的股票的例子,我们如果喂给电脑前十年的股票资料给电脑,电脑经过分析,知道股市的走势上涨下跌等等趋势。我们希望得到什么样的增进,如果电脑告诉我们说,那明天开始你就照着我说的,就这样去投资,那真的这样去投资之后,赚到了更多的钱,那机器就真的学到了东西。学到什么?学到当我们投资理财的好助手。以上是机器学习一个非常概略的定义,未来,我们会慢慢的把这个定义更加具体化。那么为什么要使用机器学习呢?为什么我们不用其它理工科里面的其它的工具呢?为什么机器学习这样的工具会有用?试想一下,在哪些应用里面机器学习可能有用?

这张图里有什么?十有八九的同学会说是一棵树。那么,如果现在让你定义一棵树,并且把它写下来。你做得到做不到?你说,哪有人定义树的,可能我说,如果今天我要请你写一个程式(大陆叫程序),这个程式要能够自动的辨认一张图里有没有一棵树?那你就要定义一棵树,因为你要有这个数学定义,才能变成电脑看得懂的程式,然后电脑再依据这个程式法去执行,然后最后辨认出一棵树,所以如果你想要写一个树的辨认程式的话,古老的方法当然就是,你脑袋里有100条关于树的规则,你想办法把这100条规则用程式写下来,这是我的树的辨认程式。不过,你可以想象这不是一个容易的工作,你可能脑袋里没有一些观念说这100条规则要写什么。但是我们从小,我们是这样学习辨认树的吗?是我们的爸爸妈妈告诉我们100条规则,然后说你把这100条规则记下来你就可以辨认出一棵树吗?显然不是,我们大体上来说是通过观察,当然也包括我们爸爸妈妈教,他也许说这个是树那个不是树,但是很大的一部分是我们自己的眼睛的观察,看了很多的树或者不是树,长得像这样,就是树,长得不像这样,就不是树。3岁小孩差不多就会辨认这是一棵树,他不是靠今天教导他的人跟他讲100条规则,然后记住。他是靠自己去观察过很多的树之后,得到的内化的技巧,他的技巧就是去辨认一棵树。所以机器学习想要做到的是一样的事情。在有些应用里面,让机器自己去学,像刚才这个例子:去辨认一棵树。可能会比我们坐下来写100行200行300行的程式,来得更简单。这就是机器学习,我们想要机器做一些事情时,如果发现只是靠我们的脑力然后把这些规则写下来,写成程式不容易做到,那另一个方法就是让机器自己去分析资料,自己学会怎么样做这些事情。所以在这样的理由下,机器学习就可能有如下这些方向的应用。

我们想要用机器做一个复杂的计算系统,然后我们不知道该怎么做(不知道编程该怎么实现),于是我们就想办法用机器学习来做。那例如说有的系统,我们还真不知道怎么把详细规则写下来(若能写下来,可直接编程实现)。像你要做一个机器人送去火星,以我们人类目前对火星的了解,知识,等等,其实是很有限的,我们实际上不知道这个机器人送上火星去以后,会碰上什么样的状况。好像我们不太可能在地球上就把100条200条1000条2000条规则统统写好说,你(机器)上去看到什么情况就做什么事。不可能这样子做一台机器,有一大部分势必要靠这个机器人上到火星去之后,观察那边的环境,再决定要做什么。看到这边有个坑的时候也许要绕过去,所以这个时候我们也许就需要机器通过学习,通过跟环境的互动来达到这个更好的表现。又或者是有的时候我们真的不容易写出这些规则,人类要辨识讲话的声音很容易,我们要辨识我们看到的东西很容易,那真的要你写出一个声音的规则来,你看到一堆音讯讯号可能实际上是写不出的,所以在这些辨识的系统里面,现在就大量的采用机器学习,大量的资料希望机器自动去里面学到辨识的这个技能。又譬如说今天要做股市交易,股市的交易是high-frequency trading,我们通常把它翻译为超级超短线,什么意思呢?10~20秒钟你就希望电脑做一个决定,要买还是要卖。若要人做决定,没有那么快速。所以这10~20秒要从股市交易的蛛丝马迹去决定要买还是要卖这样一件事,可能我们只能靠电脑来做,让电脑分析过去10年的股市资料然后做决定。又或者,现在网络上很多应用,我们往往要让一个应用服务很多的使用者,需要让服务个性化(私人订制),那人不可能想得出来说每个使用者是什么个性,张三是什么个性,我要怎么服务他,李四是什么个性,我要怎么服务他,人不可能一开始就想好这些事情。所以我们如果要让机器自动的来做这些事情,来服务这么大量的使用者的话怎么办?让机器去学习,张三李四他们使用的历史是怎么样,然后怎么样去服务他们最好,这些个性化的推荐,会大量的使用到机器学习这个技巧。机器学习实际上有点儿像在教电脑钓鱼,而不是给它鱼吃,如果今天我们自己写好这一百行两百行三百行的规则,然后就放在电脑里让它自己去跑,这是给电脑解决一个工作,它当然可以帮我们跑程序(规则),它可以帮我们解决这件事情。但是,今天我们讨论的是抓鱼给它吃太辛苦或我们抓不到,那我们是不是教它钓鱼的方法,教它分析学习的方法,然后之后电脑可以用这个方法来帮我们解决各式各样的不同问题,这就是机器学习想要做的事情。
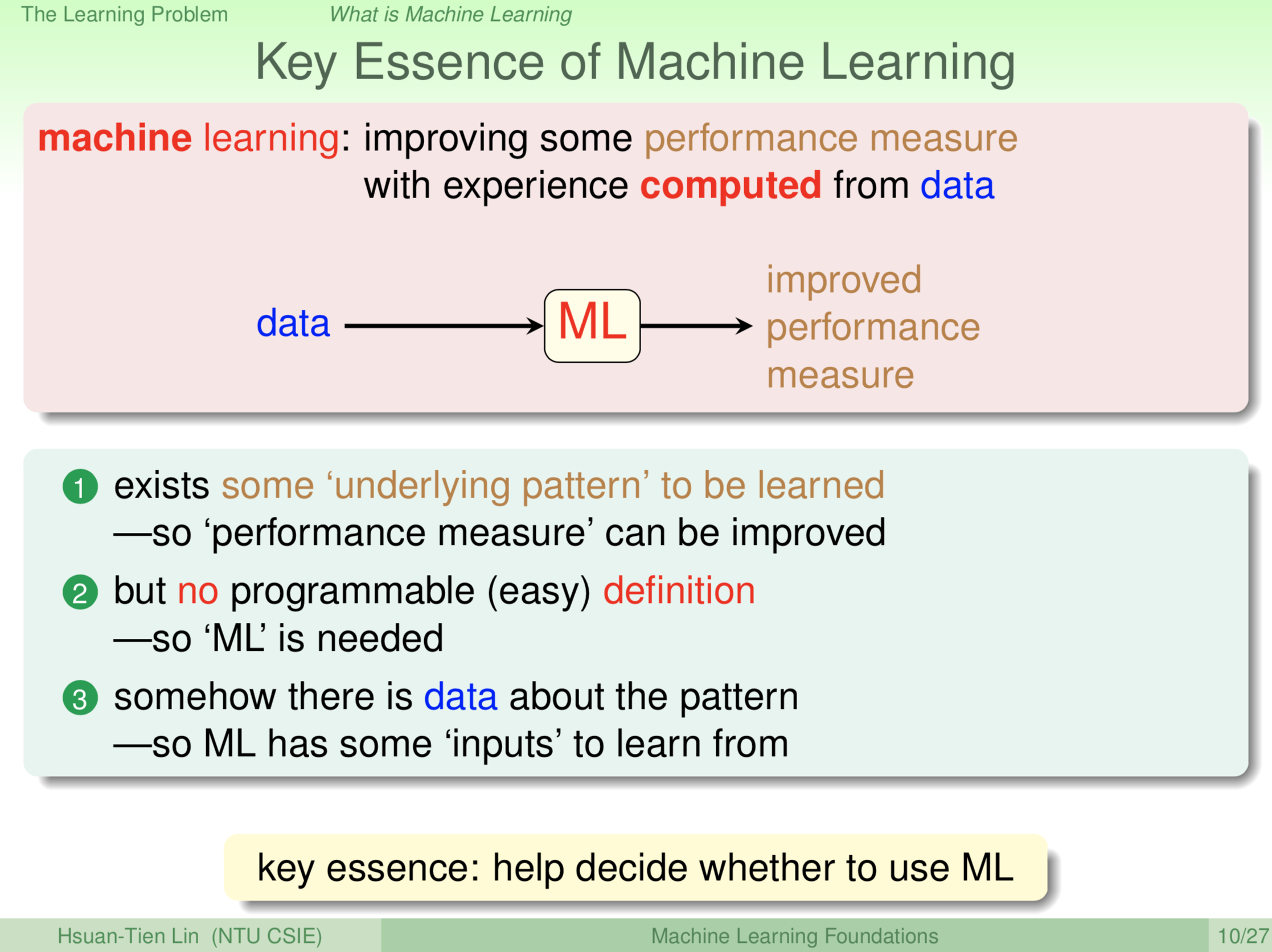
所以,从这里出发,我们就告诉大家机器学习的三个关键。有了这三个关键之后,大家以后面对各式各样不同的问题的时候,你也许就会想我到底适不适合使用机器学习,也就是机器学习不是真的可以用在每个地方,你要去想如果我们的问题有这三个关键的话,那我可能可以使用机器学习,如果没有就不那么适合使用机器学习。哪三个关键呢?第一个,某一种效能某一种表现,能够增进。既然要有表现能够增进就表示问题要可以学,即有潜藏的模式可以学习,如果一个问题完全没有模式,就算你喂给机器再多的资料,让机器跑的再久,它最终还是学不到东西。所以你要有某些目标,这些目标是让机器去学的,这样子你最终才能知道你的效能有没有增进。例如说,数学的目标,证明的正确率更高;股市的目标,虽然看起来很乱,但是可能有某一种可以学的规则,我们希望机器去学到。第二,有这样的一个规则,我们不知道怎么把它写下来,如果我们知道怎么样把这些规则写下来,那我们统统写下来,放在那边就好了。我们不知道怎么把它写下来,所以我们才会想要使用机器学习。第三,我们要有资料。机器学习的一切都是从资料开始的,我们要有资料,如果没有资料就不适合使用机器学习。

小测验:
- 预测婴儿下次哭泣是在偶数/奇数分钟
- 图中是否含有回路
- 银行是否发信用卡给客户
- 未来几年,地球是否因为使用核能而毁灭

参考答案:3
- 无法预测
- 规则可以轻易手动写出
- 合适使用机器学习
- 没有资料

机器学习在哪些领域可能会有所应用?比如孙逸仙在他的民生主义里面说的,食衣住行。
下面我们来看看机器学习怎么样改变我们吃东西的方式,这是一个蛮新的论文,这个论文里面的咨询研究者做的事情是他们让机器从哪里学呢?从Twitter的Microblog的资料去学习,学什么呢?你在推特上抒发你的心情,你可以说,我今天去了某家餐厅,这家餐厅的这个东西很好吃。去了另一家餐厅,结果回来就拉肚子感冒生病了,不高兴,等等。所以会有很多的这些资料,把这些资料综合起来,经过机器也许是语义的分析,也许是位置的分析等等判断之后。最后得到的技能是什么?机器学到的技能是它能够告诉我们说,你去这家餐厅吃,到底有多容易食物中毒。也就是说这家餐厅的卫生状况怎么样?到底容不容易食物中毒?这是一个很有趣的研究,以前我们可能要知道一家餐厅好不好,可能从朋友那里听说,或者自己去体验一下才知道,或者是上网查一下评分等等。现在呢,机器自动从大量的资料里面就告诉我们说,这家餐厅干净不干净。
那穿衣服呢?机器怎么样影响到我们穿衣服呢?Abu-Mostafa教授,加州理工学院,他写了一篇文章提到,有一家线上时尚公司请他去当顾问,当顾问做什么呢?该时尚公司希望设计一个系统,这个系统能够推荐他们的顾客说,要怎么样搭配衣服才好看。说实在话,教授对时尚界所知甚少,对时尚所知非常有限,但是他希望能够妥善的使用机器学习工具解决该问题。教授推荐该公司使用一些机器学习工具,去分析销售数字,调查顾客他们的喜好,从这些分析之后,机器学到了怎样的推荐更容易被顾客接受,迎合顾客的穿衣搭配。这个机器学到的技能,已经有媲美人类时尚专家的能力。
住,机器学习怎么样影响我们在这个住上面呢?2012年的一篇论文讲到,现在要盖房子,节能减碳。我们可能要想办法预测说,我们若盖好房子后,房子的能源消耗如何?比如说是不是常常开冷气,还是常常开暖气,然后有多么耗能等等,这些需要提前有个预估。以前只能凭借建筑师的经验,我们现在可以把这些建筑师的经验喂给机器,机器通过学习,就可以在盖房子之前告诉我们说,这个房子如果你盖好以后的耗能状况怎么样,然后建筑师就可以根据这个来决定,要不要修改设计,让它符合能源消耗预期。
行,行有什么呢?大家可能耳熟能详的最近这几年间,有很多公司和单位在发展无人驾驶的自动车的科技。例如说,Google。自动车的科技里面,很重要的一个东西是什么?是能够自动的辨识交通信号和标识。你的车子,无人驾驶的时候,你希望它能够看得到这些信号,小心行人,或者要减速,或者是看到红灯要停。去年的时候,就有一群人他们办了一个比赛,这个比赛就是希望用机器学习的方法,来提升辨识交通标识的准确率。所以他们会给机器人什么资料呢?是一些已经照相照下来的标识照片,它们可能有不同大小,不同的意思等等。希望机器从这些资料里面去学到说,到底它真正上路的时候看到不同的交通标志,看到不同的大小,不同的状况的时候,它能不能正确的去辨识这些交通标志。
所以,食衣住行,孙逸仙说的民生四大需求,机器学习通通已经开始影响我们了。除了这四大需求,还有许多,我再跟大家讲两个我自己的亲身经历,育乐。食衣住行育乐,这是现在民生六大需求。后面育乐两个是蒋介石加上去的。

育,教育。机器学习怎么影响教育呢?例如,现有一个线上的数学教学系统,学生去上面答题目,从答题目的过程,可能这个系统就慢慢的了解,学生会了什么,不会什么。它(机器)可能就会给学生多做一些他不是很熟练的题目;如果他已经会了,可能就少做一些,或者如果太难的,可能要晚一些再给学生做。那么这个系统里面很重要的当然就是,如果我给学生一个他没有见过的题目,他到底会还是不会答对。如果这个题目非常简单,学生一定答对,我们可能就不给他做;如果非常难,学生一定不会答对,我们可能从系统教育方式这个观点来说,我们也不想让学生做。问题是我们能不能从学生答题的历史记录,还有一些有关这个题目的资料里面自动的去判断,学生到底现在的水平怎么样,答下一个题目会不会答对。所以,有一个可能的方式是这样,作为人类老师我们怎么想象这个问题。我们可能会想,我们出这个题目,题目有一个难度,然后,学生脑袋里依据他的理解程度,他可能有一个现在的他的等级。如果学生的等级比题目的难度高,那么这一题他可能就会答对,否则答错。用这种方式,我们可以去设计一个相对应的机器学习演算法,它做的事情是这样,我们给这个演算法差不多九百万题的资料,来自三千个学生,以及他们的答题历史记录等等。然后,机器就去判断,估计,某个时间点学生的程度(水平)怎么样。还有,根据这个题目很多学生答过,去估计这个学生的这个题目的难度怎么样。这个有一点像工程界所谓的逆向工程,从现有的资料回推回来学生的程度怎么样,题目的难度怎么样。然后,机器就会去判断或预测说,今天这个学生的水平很高,这个题目实在太简单了,学生一定会答对;或者今天学生程度还不够,这个题目很难,他一定会答错。2010年,台湾大学的队伍,在KDDCup(全球最重要的机器学习与资料勘探比赛),这个比赛每年都吸引上百个学界和业界的队伍参加。它有很大的资料,我们刚刚看到的这九百万笔资料,它让机器从这么多的资料去学习,然后最后看看机器的表现怎么样?我们之前介绍机器学习的时候说,我们要增进某一个表现,所以它会有某一个表现的衡量。然后,大家就来比比说,你设计出来的机器学习演算法,是不是在那个表现的衡量上能够有所增进。在当年2010年台大的队伍,拿下了该比赛的冠军,这是一个非常不易的成果。

乐,我们要讲的例子是Recommender System —— 推荐系统。推荐什么呢?例如说有很多的服务,有很多的电影,希望能够把这些电影推荐给服务的使用者。每个使用者喜欢的电影不一样,有人喜欢动作片,有人喜欢爱情片,有人喜欢剧情片,有人喜欢这个演员,有人喜欢那个演员,所以每个人的喜好都不一样。然后我们就想,我们的系统有没有办法很聪明的推荐给使用者说,这个电影是你会喜欢的。如果,我们能够做到这件事,那使用者可能就会喜欢我们的系统,然后进一步的这个系统可能可以赚得一些商业上的利益。那么这个系统要怎么开始设计呢?其中一个办法是,我们要得到使用者喜欢哪些电影,使用者可能对他看过的一些电影做出评价。说我看过这个电影,我喜欢;我看过这个电影,我不喜欢;我看过这个电影,我给它90分;我看过那个电影,不喜欢,我给它20分。从很多的使用者给很多个不同电影的评价里面,我们想要判断,使用者会不会给一个他没看过的电影很高的分数。如果会的话,那可能这是他喜欢的,我们要推荐给他;如果不会的话,可能这不是他喜欢的,我们不要推荐给他。那这问题实际上还蛮重要的,所以在2006年的时候,有一个叫Netflix的公司,它是美国最大的线上DVD出借公司,租电影,该公司希望有一个这样子的电影推荐系统。他们就把收集的一些资料整个拿出来,办了一个比赛。他们收集的资料里面大概有一亿笔左右的评分资料。这一亿笔资料,来自四十八万的使用者,总共大概有一万七千部电影。他们定的比赛规则是,如果你设计出来的机器学习演算法的表现能比他们当时的系统好10%,就能获得一百万美金的奖金。这是一个非常大的题目,至少对于单一的队伍来说,这是一个非常大的数目,所以,当时吸引了全世界上百上千个队伍,来参加这个比赛。说实在话,回头来看这其实还是蛮划算的,一个公司花了一百万美金,除了广告效益外,吸引了全世界最优秀的机器学习的研究者来帮助他们的系统,找出更好的解决方式、更好的机器学习方法。在2011年,Yahoo,在KDDCup比赛中,他们也拿出了类似的资料,只是不一样的是他们拿出来的不是这个电影推荐系统的资料,而是Yahoo有一个服务叫做Yahoo Music的资料,这个资料量更大,差不多有两亿五千万笔。总共来自一百万个使用者,资料里有歌曲的评分,大概有62万笔左右。所以大家看到,资料量很大,如果机器能够从这些资料里学到一些事情的话,等于它实际上学到了我们的喜好。机器要怎么学我们的喜好呢?
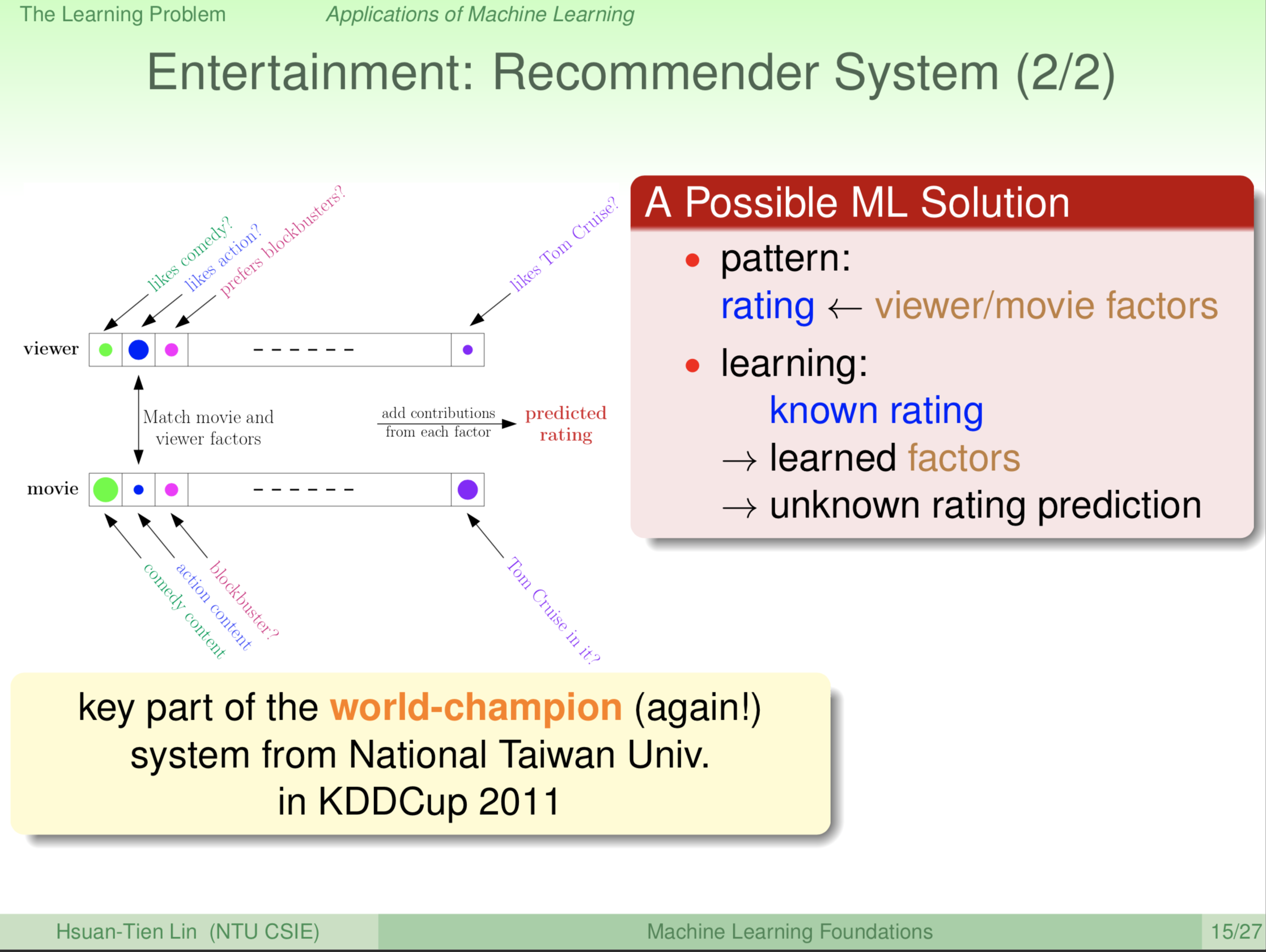
现在就告诉大家,一个可能的机器学习的模型来解决这样的问题。例如说,礼拜天我们要去看电影,那么我们怎么决定我们喜不喜欢一部电影呢?我们可能会看这部电影是什么类型,它可能是动作片、爱情片,或者是它里面有某个演员,例如说汤姆·克鲁斯,或者,它里面有某个其他的演员。这些特征组成一部电影。那我们的喜好,也可以描述成另外一串特征的数字。例如说如果我喜欢动作片,那么我的动作片这一栏的特征数字就高一点;那如果说我不喜欢爱情片,那么我的爱情片这一栏的特征数字就低一点;或者我喜欢汤姆·克鲁斯,可能那一栏的特征数字就高一点。就像图中的viewer这一串,我们用圈圈的大小,来代表特征数字的大小。像第二个蓝色的圈圈,对应于动作片,我喜欢动作片,那么这个圈圈就很大。然后,我们把movie电影描述成另一串特征数字,它若有某一特征,圈圈就很大,没有这个特征的话,圈圈就很小。所以我们想象说,我们给电影分数的过程,可能可以描述成我们把我们的这一串特征数字,跟电影的这一串特征数字,做一个内积相乘起来,相乘起来如果加起来分数非常高,那么我们可能就会给非常高的分数;如果相乘起来,加起来分数非常低,我们可能就会给非常低的分数。所以这里面潜藏的,这个我们说的这个公式(内积之和)或这个模式,是说从我们的这些特征和电影的这些特征,我们可以得到最后的评分。机器现在只有rating,没有观众和电影的这些特征,所有机器就尝试从这些rating里面,反推回来说,到底这个观众的特征是什么,这一部电影的特征是什么。然后,有了这些之后,如果今天这个观众有一部他没看过的电影,我们就把这个人的特征跟这部电影的特征相乘起来。我们就会得到,到底这个人会给这部电影多少分。这是一个很简单的模型,来描述我们怎么决定我们要给电影几分,我们机器学习是用这个方式,这个模型从这个方式出发,然后机器可能就可以自动学到,到底我们有多喜欢这部电影。2011年,台湾大学又参加KDDCup(全世界最重要的机器学习与资料勘探比赛),又拿到第一名。

讲了这些,大家想一想,机器学习在哪些领域用不到?
- 财经
- 医药
- 法律
- 通通用得上机器学习
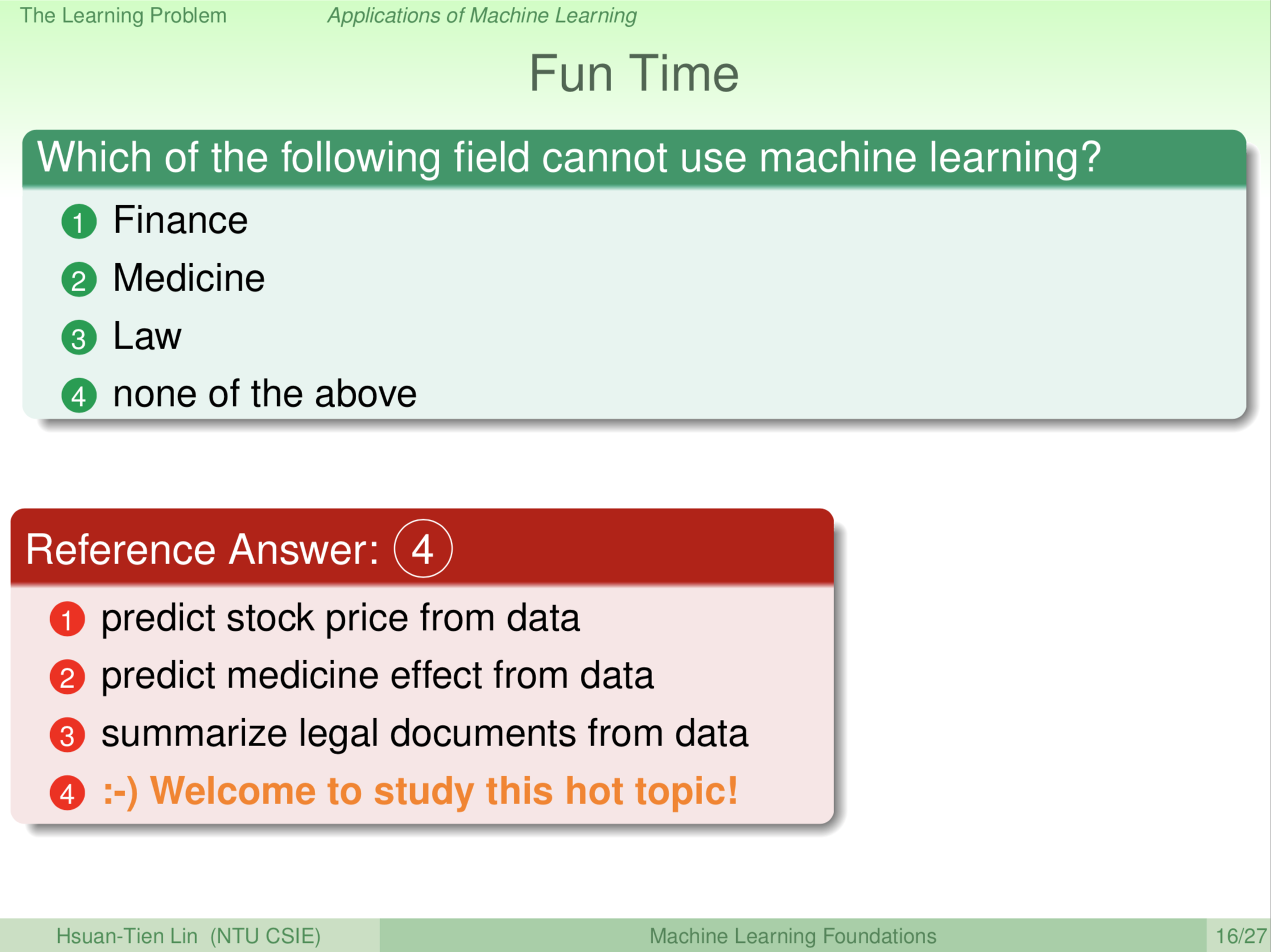
正确答案是4。
- 机器学习可以预测股票的涨跌。
- 医药领域,机器学习可以用来分析药效。
- 在法律领域,法院里面有一堆的法律公文,从这里面来分析,然后自动给出摘要。因为法律的文书往往很长很长,自动的用机器学习的方式给出摘要,让你比较容易搜寻跟阅读。

讲完机器学习可能的这些应用之后,我想要进一步的开始跟大家说,到底我们有了一个机器学习基本的这个流程之后,机器学习细部到底长什么样子。希望大家从比较抽象的描述进入到具体的机器学习。我会用的一个比喻是我们前文看过的一个例子。今天如果有一个银行它要决定要不要给顾客发信用卡,发卡后,顾客到底有没有好好用,还是欠钱不还,这是银行想要决定的事情。我们现在有了这些机器学习的基本概念以后,我们可能会想,银行手里有什么资料呢?银行手里可能有的资料就是所谓的顾客的资料,申请人的资料。比如说某个顾客,她23岁,女性,她的年收入多少?等等。银行就从你填写的申请表上这些资料最后决定要不要发信用卡给你。所以,我们希望机器能够学到的是,银行怎么样发卡,会让银行获利或者改善服务。

那我们就开始用一些符号来跟大家表示这个问题,这个符号会慢慢的抽象化,然后我们以后会讲很多问题的时候都是相通的。我们把你的申请书上面有关的这些资料叫做 x,这是我们机器学习的输入。有点像说我们如果有一个新的申请人来,我们就把这个x喂给机器算出来的东西后,然后说到底我要不要发卡给这个人。然后我们想要机器告诉我们的答案我们叫做 y。所以,在这个例子里面,我们只有两种选择,一个是发卡一个是不发卡,或者说,发卡是好还是坏,good or bad,这就是y。所以我们有一个输入申请人,一个是输出要不要发卡。机器学习底下要有某个可能可以学到的东西,这个可以学到的东西,我们把它取个名字,叫做 target function,目标函数,我们用 f来表示,f 是我们不知道的方法(如果知道直接编程可实现)。f 这个函数是从哪里到哪里呢?从大 X 集合到大 Y 集合(Y 是我们输出所在的集合)。我们不知道 f ,我么怎么开始机器学习呢?我们说机器学习要有资料。最简单的例子,我们现在有 n 笔资料,(x\(_1\), y\(_1\)) 一直到 (x\(_N\), y\(_N\)) ,这些资料可能是银行之前收集的,过去一年、两年、五年,这些以前的顾客给他们信用卡是好还是不好。这些资料,我们用大 D 表示,这是银行以前有的东西。机器学习学到了什么?它不见得能够学到 f,f 是我们想象但是我们不知道的。我们希望机器学习演算法告诉我们一个函数,我们把希望机器告诉我们的函数叫做 hypothesis,就是假说。机器看到这些资料以后,猜猜看到底好的公式应该长什么样,那这个函数我们把它叫做 g。实际上机器最后告诉我们的是 g,我们希望 g 的表现很好,机器然后拿 g 去衡量要不要给未来的顾客信用卡。所以,如果有这些符号以后,我们就大概可以把我们原来机器学习的这个简单的流程图稍微符号化一下。我们从资料出发,从资料 (x\(_N\), y\(_N\))这个 D 出发,最后机器学习告诉我们 g。那这个资料来自哪里呢?应该来自我们想学但是学不到的那个 pattern,那个模式,那个公式。我们不知道 f ,但我们有跟 f 有关的资料,有这些资料机器学习告诉我们一个 g。
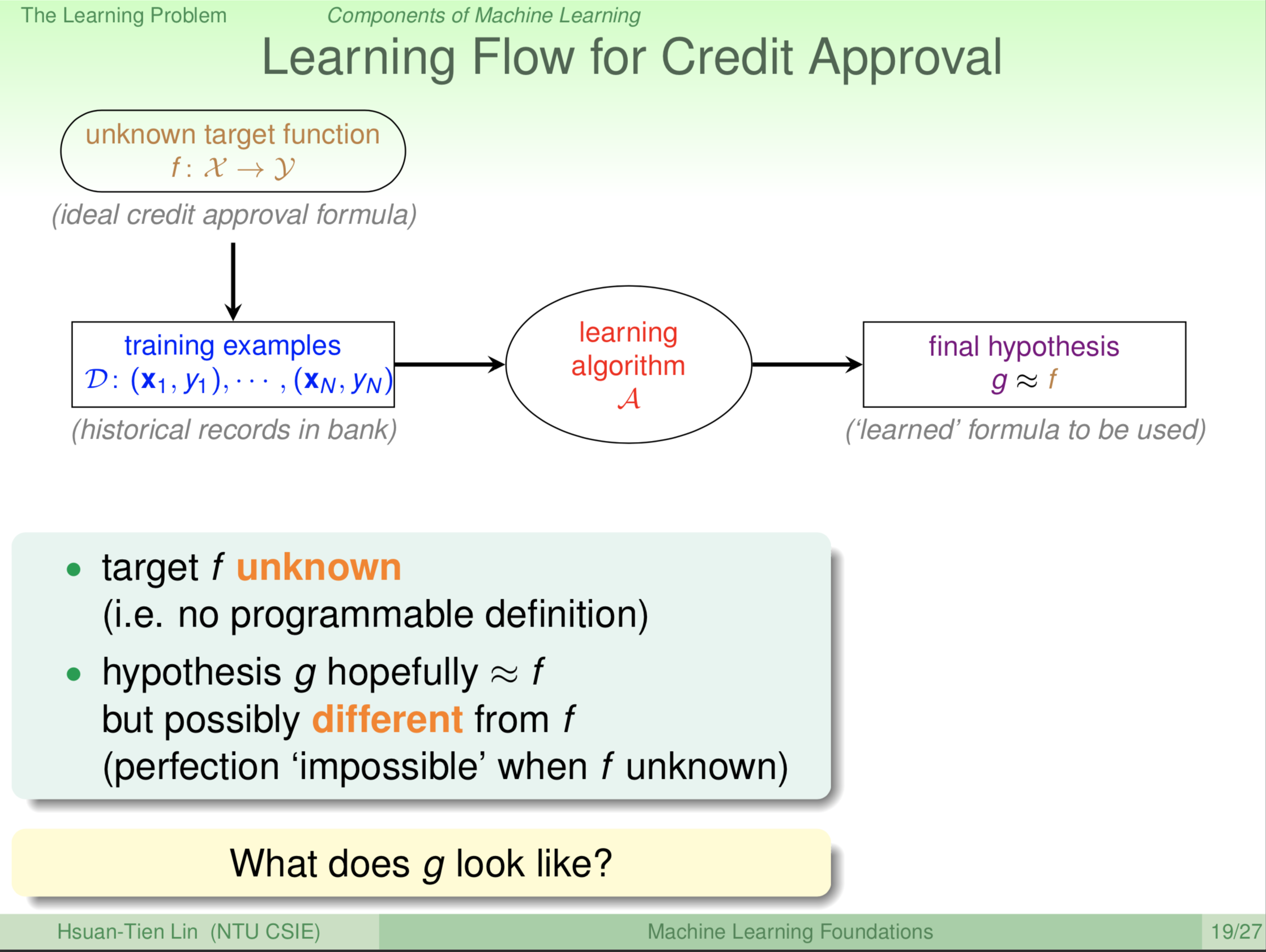
或者更进一步说,我把它列了这个更详细的流程。我们可以想象说,从左上角,这个 f ,这是一个理想的公式,这个公式产生了资料。产生资料的这个过程我们不知道,假设这事儿就这样发生。我们把资料喂给机器学习,我们一般把机器学习的核心叫做一个机器学习的演算法,我们用 A 来代表。然后机器学习的演算法就从这些资料,最后告诉我们说,到底它推荐我们哪一个 g 。我们希望的是什么?我们希望 g 代表了某一种效能的增进。所以什么叫效能增进?g 跟 f 越像越好,越像我们就说 g 很棒。如果不太像的话,我们就说 g 差很远。值得提醒的两件事,一件事是我们之前一再强调的 f 我们是不知道的,知道的话就不用机器学习了。我们不知道 f ,但是,我们希望 g 要跟 f 很像。因为我们不知道,所以通常 g 不会跟 f 一模一样。
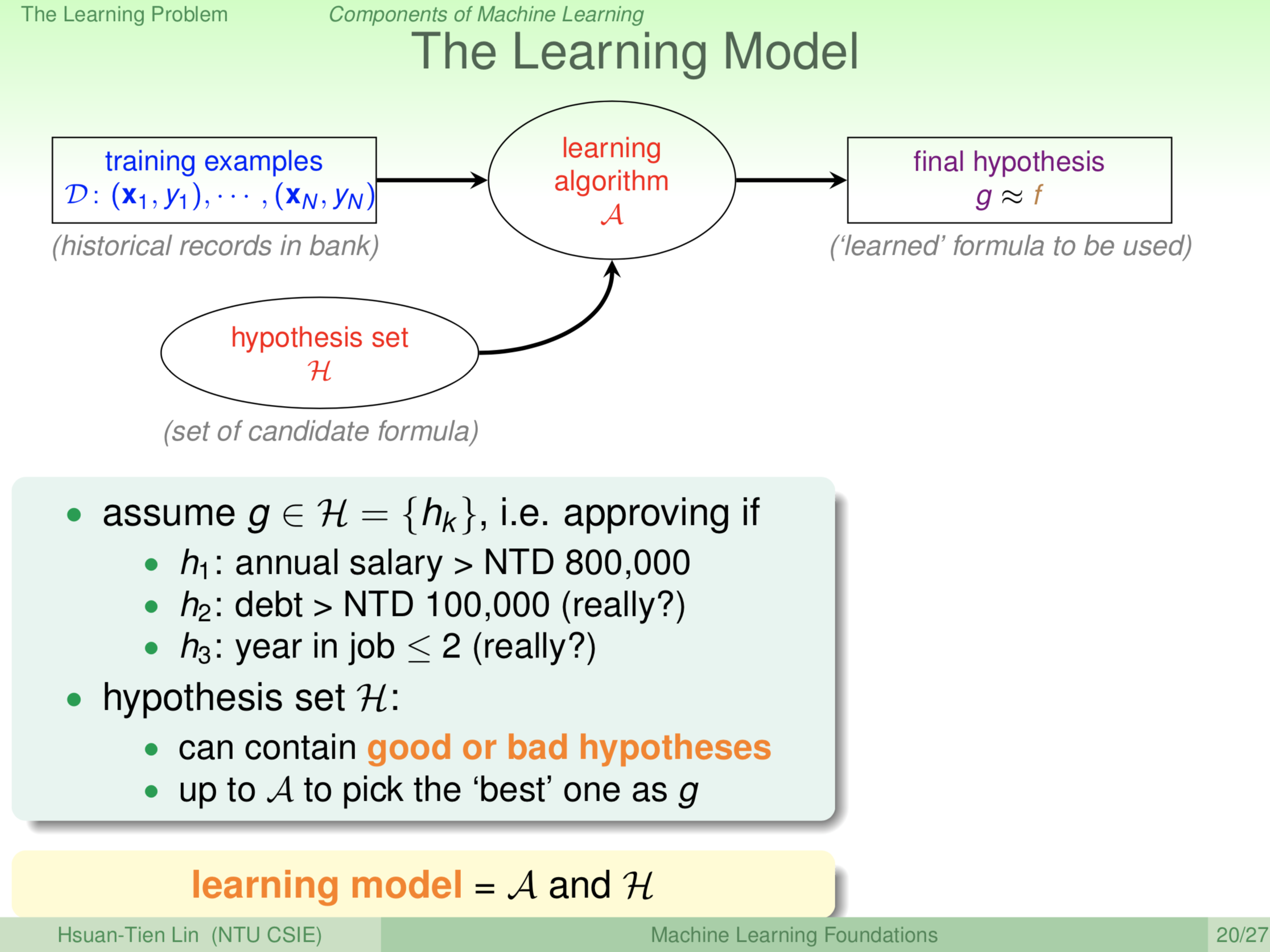
例如,今天银行决定要不要给某一顾客发信用卡。有一个可能的公式是,到底这个人的年收入有没有超过80万台币,有超过80万台币我们给他发信用卡,没有超过80万台币我们不给发信用卡,这是一个可能的 g ,机器不一定会回传这个 g ;或者如果这个人负债超过10万就给发信用卡,你可能觉得这很荒谬,但是负债多的人可能会愿意用这张信用卡赶快把负债还掉,然后再负银行一部分利息等等;亦或者这个人工作未满2年,我们就给他信用卡,这也是有可能的,年轻人花钱都比较凶,搞不好信用卡公司是要宰这种肥羊。总之,有很多很多可能的公式,我们把这些可能的公式标记为 h ,把它们集合起来放入一个大集合 H。机器学习演算法要做的事情是什么?机器学习演算法要做的就是从它看到的资料里面,从这个 H 选一个最好的 h 出来。各种可能的 g ,我们把它放在一个集合里面,这个集合我们叫做 hypothesis set ,假说的集合。然后机器学习演算法要做的事情,就是从这个 hypothesis set 里面选一个也许最符合这些资料的出来,当做它最后的这个 g ,这些 h 里面可能有好的,可能有不好的,而最后只选择一个机器学习演算法觉得最好的 h 出来。机器学习演算法实际上有两个输入,一个是看到资料,一个是你到底允许它选择哪些 hypothesis?机器学习通过这两个输入,最后决定一个 g ,这个 g 是机器学习演算法觉得最好,是不是真的最好,这是我们以后要理清的事情。未来我们会讲机器学习很多的不同模型,机器学习的模型就是指演算法。还有它所使用的这个 hypothesis set ,使用的 H 部分,这两个集合合起来叫做一个模型。你可能会说干嘛这么麻烦?干嘛要有演算法和模型的区分?为什么不把它们合为一个?我们以后会看到模型在我们做机器学习演算法的设计跟分析上面有一些重要,模型的特殊地位跟演算法其他部分不一样,所以要把模型独立出来。
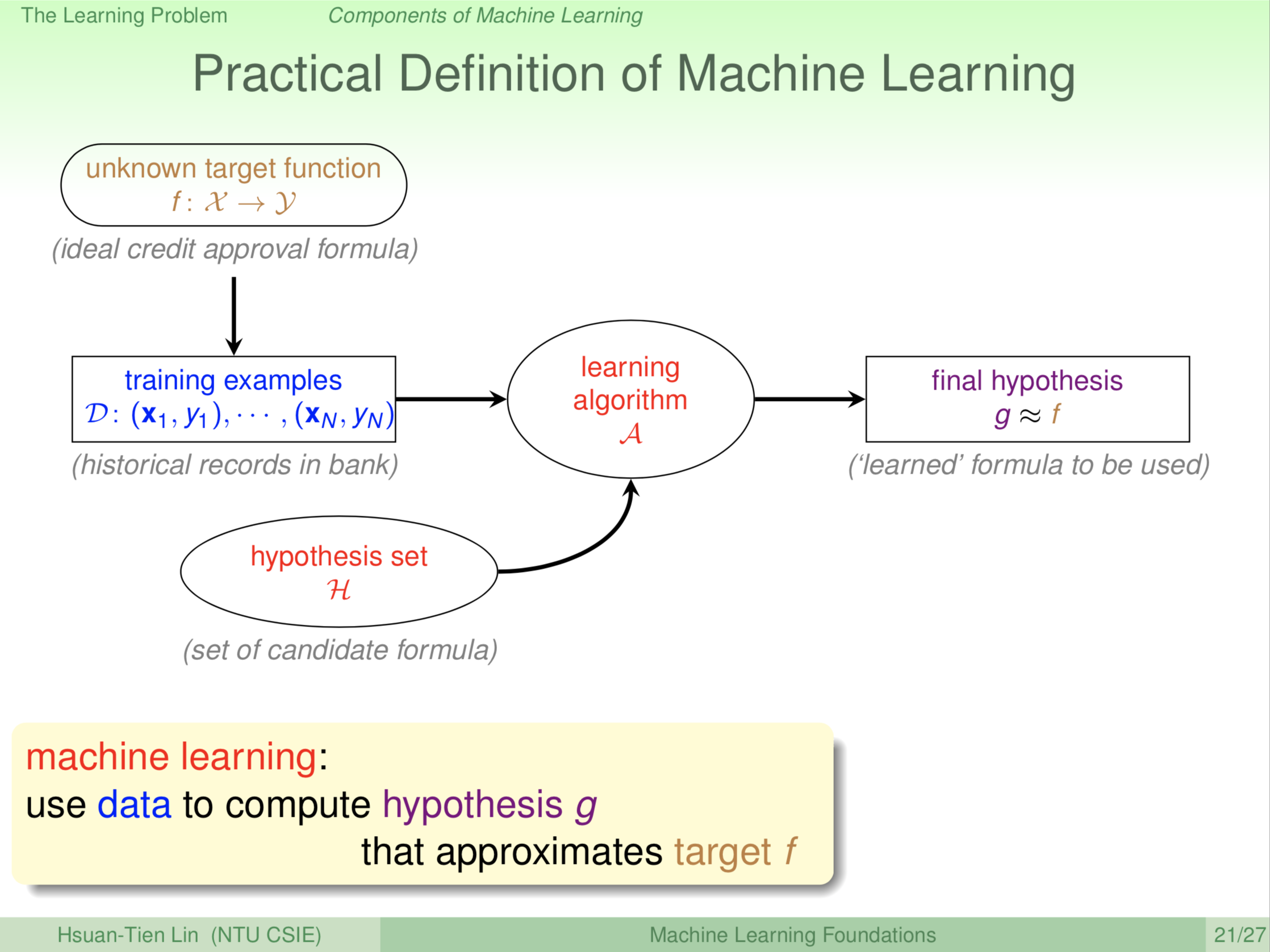
有了这个比较完整的流程以后,我们就对机器学习有一个具体的定义:机器学习就是我们从资料出发,机器学习演算法算出一个假说(一个 hypothesis),我们叫做 g 。我们希望 g 和我们正真渴望的 f 尽量接近。

我们温习一下,回到前文讲的预测每个使用者会给每首歌多少分这个问题。有 S\(_1\) ~ S\(_4\) 这四种不同的集合,哪一个是输入 X,哪一个输出 Y,哪一个是我们的 hypothesis set(H),哪一个是我们的资料 D。

参考答案是 2。我们从资料出发,把演算法用在 hypothesis set 上面,最后我们得到了这个 g ,这个 g 是一个函数,是从输入到输出的部分的一个函数。

讲完了机器学习的整个流程,我们最后给大家理清一下机器学习跟大家可能听过的一些相关领域的关系。我们要讲的第一个领域就是资料探勘,大家所知的 KDDCup 是一个资料探勘界的比赛。那你可能会说:“老师你为什么又说它是机器学习界最重要的比赛?”那我们来看一下资料探勘和机器学习有什么不一样。机器学习的定义是,机器从资料出发,找一个 hypothesis ,然后找一个和 f 很接近的 g 。资料探勘的一个简单的定义是,资料探勘希望能够用资料去找出一些有趣的事情。你可能会说这样讲很笼统,什么有趣的事情?比如说今天你是一个卖东西的人,在超市你是一个经营者,你可能会想顾客买了这个东西后,会不会也想买另一个东西。你有一堆超市的销售资料,你可能想要知道哪些东西彼此之间是有关联性的,这就是资料里面有趣或有用的地方。资料探勘通常使用非常大量的资料,然后试图找出对特定的应用有趣的或有用的一些性质。所以从这两个定义大家可以看出,机器学习和资料探勘密不可分,相辅相成。

另一个相关的领域是人工智慧。机器学习和人工智慧有什么关系?机器学习的定义前文讲过。人工智慧的定义简短就是,电脑做出某种东西可以展现出智慧行为,就是说机器要有一些聪明的表现。例如说电脑会自动下棋,这是很聪明的一件事。或者,电脑会自动开车,这也是一个聪明的事情。会预测是一件聪明的事情,机器学习要找出一个 g 和 f 很接近。从这角度出发,机器学习是实现人工智慧的一种方法。人工智慧有许多方法可以实现,那机器学习实现人工智慧有什么不同呢?大家想想下棋这个例子。传统的人工智慧在解下棋这个问题,常常会使用到 Game Tree。机器学习可能是另一个不同的方式,我们给机器看说这么多棋手是怎么下棋,这样下会赢,这样下会输,从棋手下棋的资料里面,让机器自己去分析,最后决定要怎么下棋。所以,两种不同的方式:设计算法让机器去分析 Game Tree;从棋手资料出发。

机器学习和统计的关系?两个都使用资料。统计使用资料来做一些推论,推论一些我们原来不知道的事情,比如,丢铜板正面的概率是多少?我们本来不知道,我们丢了1000次,估算一下正面朝上的概率。我们可以想象,g 是我们想要的这个 hypothesis(假说)实际上是一个推论的结果,我们想要的目标 f 实际上是我们不知道的事情。统计实际上是实现机器学习的一种方法。f 是我们不知道的,g 是我们想要从资料推论出来的东西,我们可以用统计的工具来实现机器学习。但统计是从数学出发,在统计学里面,很多东西都是先写下一些假设,然后最后证明说:在这样的情况下,在这样的统计数量之下,我们得出怎样的可证明的推论。传统统计学,更偏向数学。机器学习它是从资料出发,它的演算法常常会有很多,更重视怎么样算出来,不只是数学上的结果是怎么样。我们在机器学习里面用到的很多工具,其实有的很早很早就在统计学里有,只是,我们从统计学借过来,从机器学习的角度看看,这些统计学工具对机器学习有什么样的帮助。

这四个句子哪个是不对的?
参考答案:3
资料探勘和机器学习非常接近,但是它们有细微差别。

我希望大家了解,机器学习实际上是从资料出发,试图找到一个函数,这个函数跟我们最渴望的目标( f )是很接近的。机器学习里面核心是演算法 A 和资料 D,然后是 hypothesis set(H),然后我们最后要得到某个 hypothesis ( g )。机器学习跟其它不同的领域,资料探勘、人工智慧、统计,它们有很多联系,但也有各自不同的取向。
Preference
机器学习基石(台湾大学 林轩田),Lecture 1: The Learning Problem的更多相关文章
- 机器学习基石(台湾大学 林轩田),Lecture 2: Learning to Answer Yes/No
上一节我们跟大家介绍了一个具体的机器学习的问题,以及它的内容的设定,我们今天要继续下去做什么呢?我们今天要教大家说到底我们怎么样可以有一个机器学习的演算法来解决我们上一次提到的,判断银行要不要给顾客信 ...
- (转载)林轩田机器学习基石课程学习笔记1 — The Learning Problem
(转载)林轩田机器学习基石课程学习笔记1 - The Learning Problem When Can Machine Learn? Why Can Machine Learn? How Can M ...
- 【The VC Dimension】林轩田机器学习基石
首先回顾上节课末尾引出来的VC Bound概念,对于机器学习来说,VC dimension理论到底有啥用. 三点: 1. 如果有Break Point证明是一个好的假设集合 2. 如果N足够大,那么E ...
- 【 Logistic Regression 】林轩田机器学习基石
这里提出Logistic Regression的角度是Soft Binary Classification.输出限定在0~1之间,用于表示可能发生positive的概率. 具体的做法是在Linear ...
- 【Linear Regression】林轩田机器学习基石
这一节开始讲基础的Linear Regression算法. (1)Linear Regression的假设空间变成了实数域 (2)Linear Regression的目标是找到使得残差更小的分割线(超 ...
- 【Theory of Generalization】林轩田机器学习基石
紧接上一讲的Break Point of H.有一个非常intuition的结论,如果break point在k取到了,那么k+1, k+2,... 都是break point. 那么除此之外,我们还 ...
- 【Training versus Testing】林轩田机器学习基石
接着上一讲留下的关子,机器学习是否可行与假设集合H的数量M的关系. 机器学习是否可行的两个关键点: 1. Ein(g)是否足够小(在训练集上的表现是否出色) 2. Eout(g)是否与Ein(g)足够 ...
- 【Feasibility of Learning】林轩田机器学习基石
这一节的核心内容在于如何由hoeffding不等式 关联到机器学习的可行性. 这个PAC很形象又准确,描述了“当前的可能性大概是正确的”,即某个概率的上届. hoeffding在机器学习上的关联就是: ...
- 【Perceptron Learning Algorithm】林轩田机器学习基石
直接跳过第一讲.从第二讲Perceptron开始,记录这一讲中几个印象深的点: 1. 之前自己的直觉一直对这种图理解的不好,老按照x.y去理解. a) 这种图的每个坐标代表的是features:fea ...
随机推荐
- ajax,分页器
一.ajax请求数据 ''' $.ajax({ url: '/ajax/', # 请求路径 type: 'post', # 请求方式 data: { # get和post都以data字典方式携带数据 ...
- FFmpeg:视频转码、剪切、合并、播放速调整
原文:https://fzheng.me/2016/01/08/ffmpeg/ FFmpeg:视频转码.剪切.合并.播放速调整 2016-01-08 前阵子帮导师处理项目 ppt,因为插入视频的格式问 ...
- tp剩余未验证内容-2
如何设置一个 "资源" (文件/图片/zip/视频等)在点击时, 自动开始下载? 通常只要在这些地方, 设置 一个链接a, 让href等于这个资源就行了. 这样当点击这个资源时, ...
- c# 之partial(分部代码和分部类)
using System; namespace Partial { class Program { static void Main(string[] args) { A a = new A(); } ...
- ElasticSearch 笔记
ES集群脑裂出现的原因: 1:网络原因 内网一般不会出现此问题,可以监控内网流量状态.外网的网络出现问题的可能性大些. 2:节点负载 主节点即负责管理集群又要存储数据,当访问量大时可能会导致es实例反 ...
- MySQL GROUP BY语句
GROUP BY 语句根据一个或多个列对结果集进行分组 在分组的列上我们可以使用COUNT.SUM.AVG等函数 SELECT column_name,function(column_name) FR ...
- springboot整合thymeleaf+tiles示例
网上关于此框架的配置实在不多,因此想记录下来以防忘记 因为公司框架基于上述(公司采用gradle构建项目,楼主采用的是maven),所以楼主能少走些弯路: 1.创建springboot-maven项目 ...
- SSH KEY 设置 目录在open ~ 根目录下的.ssh 里面
当我们从github或者gitlab上clone项目或者参与项目时,需要证明我们的身份.github.gitlab支持使用SSH协议进行免密登录,而SSH协议采用了RSA算法保证了登录的安全性.我们要 ...
- command not found shell returned 127
在 vim 修改某个文件后,退出时,报了如此一个错误.日志如下: 并不是什么大问题,只是在刚入坑 ssh 时,真的被人代入坑里了. # 强制退出并保存 :wq! 不是 :!wq,不知道有没有有缘的小伙 ...
- 改变input中的placeholder样式
1.input[placeholder]{ color:#d5d5d5; } 2.input::-moz-placeholder { color: #d5d5d5; } input:-ms-input ...