OpenTSDB(时序数据库官网)
官网地址:http://opentsdb.net/
下载地址:https://github.com/OpenTSDB/opentsdb/releases
-----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------
OpenTSDB如何工作?
OpenTSDB由时间序列守护进程(TSD)和一组命令行实用程序组成。与OpenTSDB的交互主要通过运行一个或多个TSD来实现。每个TSD都是独立的。没有主服务器,没有共享状态,因此您可以根据需要运行尽可能多的TSD来处理您向其投入的任何负载。每个TSD都使用开源数据库 HBase或托管Google Bigtable服务以存储和检索时间序列数据。数据模式经过高度优化,可快速聚合相似的时间序列,从而最大限度地减少存储空间。TSD的用户永远不需要直接访问底层商店。您可以通过简单的telnet风格协议,HTTP API或简单的内置GUI与TSD进行通信。所有通信都发生在同一个端口上(TSD通过查看它接收的前几个字节来确定客户端的协议)。
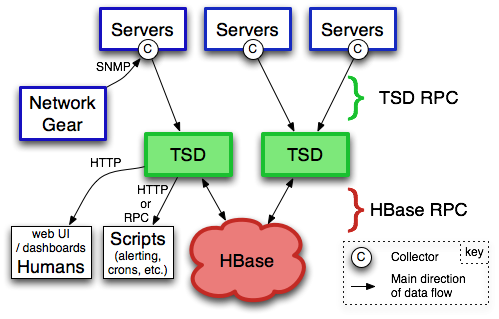
Servers:就是服务器了,上面的C就是指Collector,可以理解为OpenTSDB的agent,通过Collector收集数据,推送数据;
TSD:TSD是对外通信的无状态的服务器,Collector可以通过TSD简单的RPC协议推送监控数据;另外TSD还提供了一个web UI页面供数据查询;另外也可以通过脚本查询监控数据,对监控数据做报警
HBase:TSD收到监控数据后,是通过AsyncHbase这个库来将数据写入到HBase;AsyncHbase是完全异步、非阻塞、线程安全的Hbase客户端,使用更少的线程、锁以及内存,可以提供更高的吞吐量,特别对于大量的写操作。
写作
使用OpenTSDB的第一步是将时间序列数据发送到TSD。存在许多 工具来将来自各种源的数据提取到OpenTSDB中。如果找不到满足需求的工具,则可能需要编写从系统中收集数据的脚本(例如,通过从/procLinux上读取有趣的指标,通过SNMP从网络设备收集计数器,或者从应用程序中收集其他有趣的数据) ,通过JMX,例如Java应用程序)并定期将数据点推送到其中一个TSD。
StumbleUpon编写了一个名为Python的框架 tcollector ,用于从Linux 2.6,Apache的HTTPd,MySQL,HBase,memcached,Varnish等中收集数千个指标。这个低影响力的框架包括许多有用的收藏家,社区不断提供更多。支持OpenTSDB的替代框架包括Collectd,Statsd和Coda Hale指标发射器。
在OpenTSDB中,时间序列数据点包括:
- 度量标准名称。
- UNIX时间戳(自Epoch以来的秒数或毫秒数 )。
- 值(64位整数或单精度浮点值),JSON格式的事件或直方图/摘要。
- 一组标记(键值对),用于描述该点所属的时间序列。
标签允许您从不同的源或相关实体中分离出类似的数据点,因此您可以轻松地单独或成组地绘制它们。标签的一个常见用例包括使用生成它的机器的名称以及机器所属的集群或池的名称来注释数据点。这使您可以轻松地制作仪表板,以便在每个服务器的基础上显示服务状态,以及显示跨逻辑服务器池的聚合状态的仪表板。
mysql.bytes_sent 1287333217 6604859181710 schema = foo host = db1
mysql.bytes_received 1287333232 327812421706 schema = foo host = db1
mysql.bytes_sent 1287333232 6604901075387 schema = foo host = db1
mysql.bytes_received 1287333321 340899533915 schema = foo host = db2
mysql.bytes_sent 1287333321 5506469130707 schema = foo host = db2
此示例包含属于4个不同时间序列的6个数据点。度量标准和标记的每个不同组合构成不同的时间序列。所有4个时间序列都是针对两个指标之一 mysql.bytes_received或mysql.bytes_sent。数据点必须至少有一个标记,并且度量标准的每个时间序列应具有相同数量的标记。不建议每个数据点具有超过6-7个标签,因为与存储新数据点相关的成本很快就会超过该点之外的标签数量。
使用上面示例中的标记,可以轻松创建图形和仪表板,以在每个主机和/或每个模式的基础上显示MySQL的网络活动。OpenTSDB 2.0的新功能是能够存储非数字注释以及用于跟踪元数据,质量指标或其他类型信息的数据点。
读
时间序列数据通常以折线图的格式消耗。因此,OpenTSDB提供了一个内置的简单用户界面,用于选择一个或多个指标和标签,以生成图形作为图像。或者,可以使用HTTP API将OpenTSDB绑定到外部系统,例如监视框架,仪表板,统计包或自动化工具。
查看 社区为使用OpenTSDB提供的工具的资源页面。
-----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------

- opentsdb-2.3.1.noarch.rpm11.8 MB
- opentsdb-2.3.1.tar.gz75.1 MB
- opentsdb-2.3.1_all.deb11.4 MB
- 源代码(zip)
- 源代码(tar.gz)
- 版本2.3.1(2018-04-21)
值得注意的变化:
- 设置聚合器时,前进到等于或大于
查询开始时间戳的第一个数据点。这有助于日历下采样间隔。 - 添加对Nagios检查脚本的支持,以便对填充策略进行下采样。
Bug修复:
- 通过避免双重执行并检查两种
输出类型的布尔值来修复表达式计算。 - 修复构建中缺少的工具脚本。
- OSX安装脚本中的默认HBase 1.2.5
- 将AsyncBigtable升级到0.3.1
- 意外关闭通道时记录查询统计信息。
- 在debian init脚本中添加Java 8路径并删除Java 6。
- 将列系列名称传递给压缩调度程序中的get请求。
- 在按标签分组的UI中修复比较问题。
- 按开始时间戳过滤注释查询,不包括在
查询开始时间之前开始的行中的注释查询。 - 从Gnuplot脚本中清除反引号的微小主旨。
final从元类中删除注释,以便可以扩展它们。- 修复javacc maven插件版本。
- 修复文字或过滤器以允许单个字符过滤器。
- 修复查询开始统计日志记录以使用ms而不是nano时间。
- 出于安全原因,将Jackson和Netty移至新版本。
- 升级到AsyncHBase 1.8.2以与HBase 1.3和2.0兼容
- 修复最高电流计算以处理空时间序列。
- 将缓存命中计数器更改为long。
OpenTSDB(时序数据库官网)的更多相关文章
- Ubuntu16.04下Neo4j图数据库官网安装部署步骤(图文详解)(博主推荐)
不多说,直接上干货! 说在前面的话 首先,查看下你的操作系统的版本. root@zhouls-virtual-machine:~# cat /etc/issue Ubuntu LTS \n \l r ...
- Ubuntu14.04下Neo4j图数据库官网安装部署步骤(图文详解)(博主推荐)
不多说,直接上干货! 说在前面的话 首先,查看下你的操作系统的版本. root@zhouls-virtual-machine:~# cat /etc/issue Ubuntu 14.04.4 LTS ...
- 深入浅出时序数据库之预处理篇——批处理和流处理,用户可定制,但目前流行influxdb没有做
时序数据是一个写多读少的场景,对时序数据库以及数据存储方面做了论述,数据查询和聚合运算同样是时序数据库必不可少的功能之一.如何支持在秒级对上亿数据的查询分组聚合运算成为了时序数据库产品必须要面对的挑战 ...
- 从Oracle官网学习oracle数据库和java
网上搜索Oracle官网:oracle官网 进入Oracle官网 点击menu-Documentation-Java/Database,进入Oracle官网的文档网站 首先是Java,可以看到Java ...
- 【如何在mysql 官网下载最新版本mysql 数据库】
方法/步骤 打开百度搜索,输入MySQL,第一个是MySQL官网 点击第一个链接地址,进入MySQL官方网站,单击“Downloads”下载Tab页,进入下载界面 找到Community( ...
- 搭建mysql5.626及如何去官网下载历史版本数据库
MySQL官网下载历史版本 网上搜索MySQL官网 2 查询所有的归档文件 点击进入服务器列表 列表中默认只有Windows 版本的,可选择其它版本,但无法进行查询 查看网页元素 发现 ...
- 时序数据库(TSDB)-为万物互联插上一双翅膀
本文由 网易云发布. 时序数据库(TSDB)是一种特定类型的数据库,主要用来存储时序数据.随着5G技术的不断成熟,物联网技术将会使得万物互联.物联网时代之前只有手机.电脑可以联网,以后所有设备都会联 ...
- 时序数据库InfluxDB安装及使用
时序数据库InfluxDB安装及使用 1 安装配置 安装 wget https://dl.influxdata.com/influxdb/releases/influxdb-1.3.1.x86_64. ...
- 时序数据库InfluxDB:简介及安装
在性能测试过程中,对测试结果以及的实时监控与展示也是很重要的一部分.这篇博客,介绍下linux环境下InfluxDB的安装以及功能特点. 官网地址:influxdata 官方文档:influxdb文档 ...
随机推荐
- 当超强台风“山竹”即将冲进南海,Power BI 你怎么看?
这个周末“山竹 ”强势来袭!很多人的目光都在关注暴力水果“山竹”,这个号称70年最强最大风力超17级 台风“山竹”今天就已经在小悦家窗台肆虐咆哮了一天了!不知其他的小伙伴们是不是好好的一个周末就只能被 ...
- i.MX6 u-boot 怎么确定板级头文件
/********************************************************************** * i.MX6 u-boot 怎么确定板级头文件 * 说 ...
- 带列表写入文件出错先 json.dumps
output = json.dumps(output, ensure_ascii=False).encode('utf-8')
- mac下python安装MySQLdb模块
参考:http://blog.csdn.net/yelyyely/article/details/41114449 1.调整到anaconda下的python 2.安装有关程序 brew instal ...
- P2261 [CQOI2007]余数求和 (数论)
题目链接:传送门 题目: 题目背景 数学题,无背景 题目描述 给出正整数n和k,计算G(n, k)=k mod + k mod + k mod + … + k mod n的值,其中k mod i表示k ...
- HDU1272小希的迷宫–并查集
上次Gardon的迷宫城堡小希玩了很久(见Problem B),现在她也想设计一个迷宫让Gardon来走.但是她设计迷宫的思路不一样,首先她认为所有的通道都应该是双向连通的,就是说如果有一个通道连通了 ...
- hdu4336 Card Collector 容斥原理
In your childhood, do you crazy for collecting the beautiful cards in the snacks? They said that, fo ...
- ionic1实现热更新以版本检测更新安装包的方法
1.需要下载热更新插件:插件名称是cordova-hot-code-push 首先打开cli,执行命令 npm install -g cordova-hot-code-push-cli 此功能主要是为 ...
- 【BZOJ3244】【UOJ#122】【NOI2013]树的计数
NOI都是酱的题怎么玩啊,哇.jpg 原题: 我们知道一棵有根树可以进行深度优先遍历(DFS)以及广度优先遍历(BFS)来生成这棵树的DFS序以及BFS序.两棵不同的树的DFS序有可能相同,并且它们的 ...
- Axure RP chrome插件显示已损坏或者无法安装的解决方法
http://www.cnplugins.com/zhuanti/arux-rp-bug.html 1.Axure RP chrome插件无法安装的解决方法. 首先Axure RP chrome插件的 ...