(原)CNN中的卷积、1x1卷积及在pytorch中的验证
转载请注明处处:
http://www.cnblogs.com/darkknightzh/p/9017854.html
参考网址:
https://pytorch.org/docs/stable/nn.html?highlight=conv2d#torch.nn.Conv2d
https://www.cnblogs.com/chuantingSDU/p/8120065.html
https://blog.csdn.net/chaolei3/article/details/79374563
1x1卷积
https://blog.csdn.net/u014114990/article/details/50767786
https://www.quora.com/How-are-1x1-convolutions-used-for-dimensionality-reduction
理解错误的地方敬请谅解。
1. 卷积
才发现一直理解错了CNN中的卷积操作。
假设输入输出大小不变,输入是N*Cin*H*W,输出是N*Co*H*W。其中N为batchsize。卷积核的大小是k*k。实际上共有Cin*Co个k*k的卷积核,总共的参数是Cin*k*k*Co(无bias)或者Cin*k*k*Co+Co(有bias)。
pytorch中给出了conv2d的计算公式
(https://pytorch.org/docs/stable/nn.html?highlight=conv2d#torch.nn.Conv2d):
$out({{N}_{i}},C{{o}_{j}})=bias(C{{o}_{j}})+\sum\limits_{k=0}^{Cin-1}{weight(C{{o}_{j}},k)*input({{N}_{i}},k)}$
其中weight即为卷积核,上式中输出的batch中的第Ni个特征图的第Coj个特征,即为输入的第Ni个特征图的第k个特征,和第Coj个卷积核中的第k个核进行卷积(cross-correlation)。
如下图所示,对于某个输入特征图,其某局域分别于Co个卷积核进行卷积,得到对应的特征Coi,而后将这些特征拼接起来,得到最终的特征图。实际上每个卷积核都是k*k*Cin的大小。
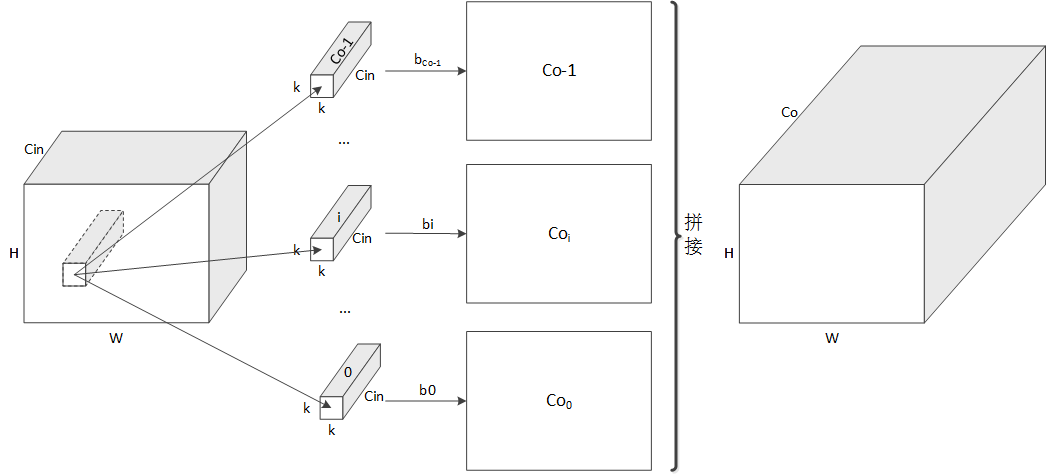
经过上面的卷积,就可以将输入的不同的通道的信息融合了(权重不同,类似于加权融合)。
如果输出Co数量大于输入Cin数量,输出特征数量就多于输入特征。否则输出就少于输入特征数量。
2. 1*1卷积
上面的卷积理解了,1*1卷积就好理解了。
1*1主要用于降维或者升维(看Cin和Co哪个更大),其核大小为1*1。
实际上卷积核的数量为Cin*1*1*Co=Cin*Co(无bias)或者Cin*Co+Co(有bias)。
计算时,通道方向上每个卷积核将输入按照通道进行加权,得到对应的输出特征,之后将这些特征拼接起来,即可得到最终的特征图。
3. pytorch中的验证
代码:
from __future__ import print_function
from __future__ import division import torch.nn as nn
import numpy as np class testNet(nn.Module):
def __init__(self):
super(testNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=10, kernel_size=5, stride=1, padding=1, bias=True) def forward(self, x):
x = self.conv1(x)
return x def get_total_params(model):
model_parameters = filter(lambda p: p.requires_grad, model.parameters())
num_params = sum([np.prod(p.size()) for p in model_parameters])
return num_params def main():
net = testNet()
print(get_total_params(net)) if __name__ == '__main__':
main()
上面代码中get_total_params用于得到模型总共的参数。
当kernel_size=5,bias=True时,参数共计760个:3*5*5*10+10=760。
当kernel_size=5,bias=False时,参数共计750个:3*5*5*10=750。
当kernel_size=1,bias=True时,参数共计40个:3*1*1*10+10=40。
当kernel_size=1,bias=False时,参数共计30个:3*1*1*10=30。
(原)CNN中的卷积、1x1卷积及在pytorch中的验证的更多相关文章
- 基于卷积神经网络的面部表情识别(Pytorch实现)----台大李宏毅机器学习作业3(HW3)
一.项目说明 给定数据集train.csv,要求使用卷积神经网络CNN,根据每个样本的面部图片判断出其表情.在本项目中,表情共分7类,分别为:(0)生气,(1)厌恶,(2)恐惧,(3)高兴,(4)难过 ...
- 转pytorch中训练深度神经网络模型的关键知识点
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/weixin_42279044/articl ...
- PyTorch中的C++扩展
今天要聊聊用 PyTorch 进行 C++ 扩展. 在正式开始前,我们需要了解 PyTorch 如何自定义module.这其中,最常见的就是在 python 中继承torch.nn.Module,用 ...
- 深度拾遗(06) - 1X1卷积/global average pooling
什么是1X1卷积 11的卷积就是对上一层的多个feature channels线性叠加,channel加权平均. 只不过这个组合系数恰好可以看成是一个11的卷积.这种表示的好处是,完全可以回到模型中其 ...
- CNN笔记:通俗理解卷积神经网络【转】
本文转载自:https://blog.csdn.net/v_july_v/article/details/51812459 通俗理解卷积神经网络(cs231n与5月dl班课程笔记) 1 前言 2012 ...
- CNN笔记:通俗理解卷积神经网络
CNN笔记:通俗理解卷积神经网络 2016年07月02日 22:14:50 v_JULY_v 阅读数 250368更多 分类专栏: 30.Machine L & Deep Learning 机 ...
- 图像卷积、相关以及在MATLAB中的操作
图像卷积.相关以及在MATLAB中的操作 2016年7月11日 20:34:35, By ChrisZZ 区分卷积和相关 图像处理中常常需要用一个滤波器做空间滤波操作.空间滤波操作有时候也被叫做卷积滤 ...
- 深度学习卷积网络中反卷积/转置卷积的理解 transposed conv/deconv
搞明白了卷积网络中所谓deconv到底是个什么东西后,不写下来怕又忘记,根据参考资料,加上我自己的理解,记录在这篇博客里. 先来规范表达 为了方便理解,本文出现的举例情况都是2D矩阵卷积,卷积输入和核 ...
- [PyTorch]PyTorch中反卷积的用法
文章来源:https://www.jianshu.com/p/01577e86e506 pytorch中的 2D 卷积层 和 2D 反卷积层 函数分别如下: class torch.nn.Conv2d ...
随机推荐
- 《精通Spring 4.x 企业应用开发实战》学习笔记
第四章 IoC容器 4.1 IoC概述 IoC(Inverse of Control 控制反转),控制是指接口实现类的选择控制权,反转是指这种选择控制权从调用类转移到外部第三方类或容器的手中. 也就是 ...
- Struts2中的数据处理的三种方式对比(Action中三种作用域request,session,application对象)
1:在Action中如何获得作用域(request,session,application)对象: 取得Map(键值对映射集)类型的requet,session,application; 对数据操作的 ...
- 060 关于Hive的调优(本身,sql,mapreduce)
1.关于hive的优化 ->大表拆分小表 ->过滤字段 ->按字段分类存放 ->外部表与分区表 ->外部表:删除时只删除元数据信息,不删除数据文件 多人使用多个外部表操作 ...
- 一些日常工具集合(C++代码片段)
一些日常工具集合(C++代码片段) ——工欲善其事,必先利其器 尽管不会松松松,但是至少维持一个比较小的常数还是比较好的 在此之前依然要保证算法的正确性以及代码的可写性 本文依然会持久更新,因为一次写 ...
- 一款易搭建,运行快的Git服务器:Gitea安装教程
说明:Gitea是从Gogs发展而来,同样的拥有极易安装,运行快速的特点,而且更新比Gogs频繁很多,维护的人也多,个人认为Gitea还是更好一些的,这里就说下安装方法. 截图 简介 Gitea是一个 ...
- R1题解
估分 大佬们都去写题解了,我不写可能会被老师训诶.... 预计分数:100 + 100 + 5 + 100 + 25 + 100 = 430 实际 :80 + 100 + 0 + 100 + 25 + ...
- BZOJ.2453.维护队列([模板]带修改莫队)
题目链接 带修改莫队: 普通莫队的扩展,依旧从[l,r,t]怎么转移到[l+1,r,t],[l,r+1,t],[l,r,t+1]去考虑 对于当前所在的区间维护一个vis[l~r]=1,在修改值时根据是 ...
- 潭州课堂25班:Ph201805201 第四课:Linux的命令以及VIM的使用 (课堂笔记)
Linux的常用命令 引入 1:如果我们要在Linux里面实现一些比如查看文件和文件夹.新建文件夹之类的操作,应该是通过什么来实现 2:讲解Linux目录树 3:讲解Linux只区分文件名,Linux ...
- [HackerRank]Choosing White Balls
[HackerRank]Choosing White Balls 题目大意: 有\(n(n\le30)\)个球排成一行,每个球的颜色为黑或白. 执行\(k\)次操作,第\(i\)次操作形式如下: 从\ ...
- 面向对象&网络编程
1 接口与归一化设计 1.1 归一化概念: 归一化的好处: 1.归一化让使用者无需关心对象的类是什么,只需要知道这些对象都具备某些功能就可以了,这极大降低了使用者的使用难度. 2.归一化使得高层的外部 ...