HDFS存入文件的整个流程
本文结合HDFS的副本和分块从宏观上描述HDFS存入文件的整个流程。HDFS体系中包含Client、NameNode、DataNode、SeconderyNameode四个角色,其中Client是客户端,NN负责管理,DN负责存储、SN协助管理。
先来看一个官网上的图
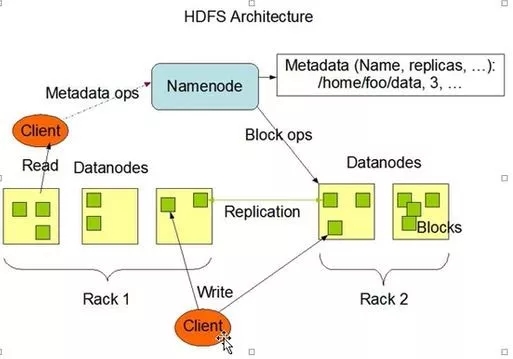
# 图 0 -HDFS的体系结构
HDFS的副本存储有如下规则:
1.client将第一副本放到最靠近的一台DN
2.第二副本优先放到另一个机架
3.以此类推,尽量保证副本放在不同的机架
由于副本和分块机制的存在,当从本地文件系统向HDFS上传文件时,其内部的流程相对比较复杂,可以通过下图及步骤说明进行理解。

# 图 1-1 -hdfs副本存储机制(3副本)
A.对于可存于单块的小文件:
1.client向NN(NameNode)发起存储请求,
2.NN查找自身是否已有相应的文件,
3.若无则,NN向client返回DN1(DataNode)路径,
4.client向DN1传送副本,
5.DN1通过管道异步向DN2传副本,
6.DN2通过管道异步向DN3传副本,
7.DN3通知DN2接收完成,
8.DN2通知DN1接收完成,
9.DN1通知NN接收完成。
B.对于需要分块的大文件:
大致流程同上,但在步骤3NN还会进行块的划分,随后步骤4client会将各块分别发送到分配的DN执行步骤4~9
从前述可见,在向HDFS传输文件的过程中,NameNode节点至关重要。NN负责掌管元数据。其作用相当于物理硬盘中的文件分配表FAT,NN中的数据如果发生丢失,DN中存储的数据也就没有了意义。
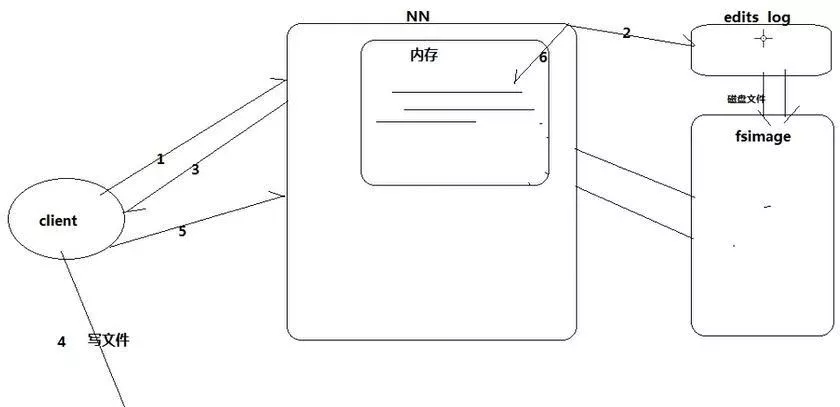
# 图 1-2 -NN元数据存储机制
1.client向NN请求写,
2.NN将分配block写入editslog文件,
3.NN响应client,
4.client向DN写文件,
5.client通知NN写完成,
6.NN将editslog更新到内存。
ps:常用及最新元数据放在内存,最新元数据放editslog,老元数据放fsimage,editslog写满之前将edits log(新元数据)转换并合并到fsimage。
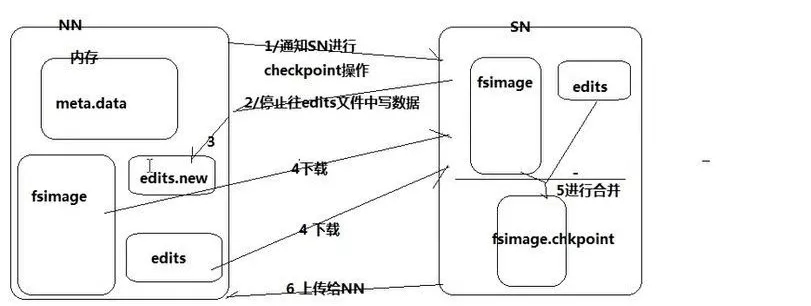
# 图 1-3 -edits log合并机制
当editslog写满:
1.NN通知SecondryNameNode执行checkpoint操作,
2.NN停止向已满editslog写入,
3.NN创建新edits log维持写入,
4.SN下载NN的fsimage和已满editslog,
5.SN执行合并生成fsimage。checkpoint,
6.SN向NN上传fsi。cp,
7.NN将fsi。cp改名fsimage,
8.NN删除已满editslog。
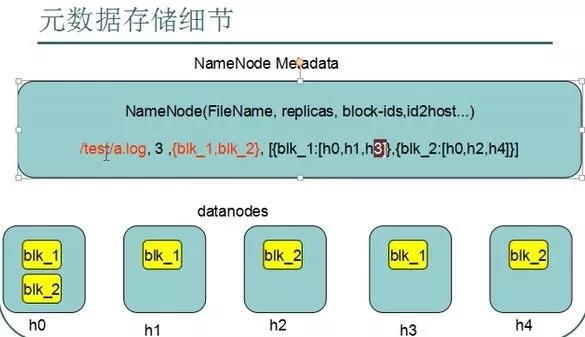
# 图3 -元数据格式:文件全路径,副本数,块编号,块-所在DN的映射。
HDFS存入文件的整个流程的更多相关文章
- hadoop 提高hdfs删文件效率----hadoop删除文件流程解析
前言 这段时间在用hdfs,由于要处理的文件比较多,要及时产出旧文件,但是发现hdfs的blocks数一直在上涨,经分析是hdfs写入的速度较快,而block回收较慢,所以分心了一下hadoop删文件 ...
- 【Hadoop】HDFS - 创建文件流程详解
1.本文目的 通过解析客户端创建文件流程,认知hadoop的HDFS系统的一些功能和概念. 2.主要概念 2.1 NameNode(NN): HDFS系统核心组件,负责分布式文件系统的名字空间管理.I ...
- hadoop学习笔记(六):HDFS文件的读写流程
一.HDFS读取文件流程: 详解读取流程: Client调用FileSystem.open()方法: 1 FileSystem通过RPC与NN通信,NN返回该文件的部分或全部block列表(含有blo ...
- HDFS写文件过程分析
转自http://shiyanjun.cn/archives/942.html HDFS是一个分布式文件系统,在HDFS上写文件的过程与我们平时使用的单机文件系统非常不同,从宏观上来看,在HDFS文件 ...
- 使用oracle的大数据工具ODCH访问HDFS数据文件
软件下载 Oracle Big Data Connectors:ODCH 下载地址: http://www.oracle.com/technetwork/bdc/big-data-connectors ...
- (转)distcp从ftp到hdfs拷贝文件
link :http://blog.csdn.net/sptoor/article/details/11523469 distcp从ftp到hdfs拷贝文件: hadoop distcp ftp:// ...
- Spark中加载本地(或者hdfs)文件以及SparkContext实例的textFile使用
默认是从hdfs读取文件,也可以指定sc.textFile("路径").在路径前面加上hdfs://表示从hdfs文件系统上读 本地文件读取 sc.textFile("路 ...
- HDFS的Java客户端操作代码(HDFS删除文件或目录)
1.HDFS删除文件或目录 package Hdfs; import java.io.IOException; import java.net.URI; import org.apache.hadoo ...
- Hadoop HDFS分布式文件系统设计要点与架构
Hadoop HDFS分布式文件系统设计要点与架构 Hadoop简介:一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群 ...
随机推荐
- hdu4585Shaolin
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4585 题意: 第一个人ID为1,战斗力为1e9. 给定n,给出n个人的ID和战斗力. 每个人必须和战斗 ...
- ZOJ 3195 Design the city (LCA 模板题)
Cerror is the mayor of city HangZhou. As you may know, the traffic system of this city is so terribl ...
- ARTS-S docker里程序通过ip访问外部数据库
要先确保外部数据库能通过ip访问,然后启动docker的时间加参数--network host,如 docker run \ --name fcheck_async_worker \ -it \ -v ...
- Mybatis 报错 java.lang.IllegalArgumentException: Result Maps collection does not contain value for java.lang.Inte
like ‘%java.lang.IllegalArgumentException: Result Maps collection does not contain value for java.la ...
- 使用iCamera 测试MT9F002 1400w高分辨率摄像头说明 续集2
使用iCamera 测试MT9F002 1400w高分辨率摄像头说明 续集2 本方案测试三种分辨率输出(其他更多分辨率设置,可以参考手册配置) 3776*3288=1241万像素 3776*2832= ...
- Linux环境(服务器)下非root用户安装Python3.6
Linux环境(服务器)下非root用户安装Python3.6 在管理实验室集群时候,遇到的问题--非root用户在搭建自己环境时候,如何搭建. 注意: root用户的根目录是root,非root用户 ...
- Xshell连接阿里云服务器
1.遇到的问题 直接用阿里云的终端,还需要登录浏览器很是麻烦,所以用Xshell,ssh远程登录这样就轻松方便了很多. 2.打开 打开安装好的Xshell,点击新建 出现了这个界面,首先注意主 ...
- 【Webpack】320- Webpack4 入门手册(共 18 章)(下)
介绍 1. 背景 最近和部门老大,一起在研究团队[EFT - 前端新手村]的建设,目的在于:帮助新人快速了解和融入公司团队,帮助零基础新人学习和入门前端开发并且达到公司业务开发水平. 本文也是属于[E ...
- HTML5变化
HTML5变化 新的语义化元素 header footer nav main article section 删除了一些纯样式的标签 表单增强 新API 离线 (applicationCache ) ...
- django基础之day04,必知必会13条,双下划线查询,字段增删改查,对象的跨表查询,双下划线的跨表查询
from django.test import TestCase # Create your tests here. import os import sys if __name__ == " ...