微调(Fine-tune)原理
在自己的数据集上训练一个新的深度学习模型时,一般采取在预训练好的模型上进行微调的方法。什么是微调?这里已VGG16为例进行讲解,下面贴出VGGNet结构示意图。
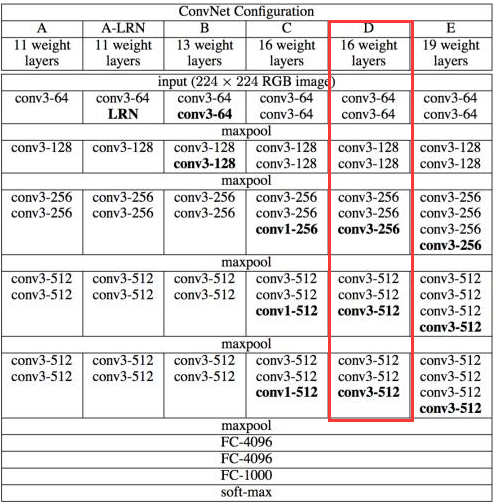
上面圈出来的是VGG16示意图,也可以用如下两个图表示。


如上图所示 ,VGG16的结构为卷积+全连接层。卷积层分为5个部分共13层,即图中的conv1~conv5。还有3层是全连接层,即图中的fc6、fc7、fc8。卷积层加上全连接层合起来一共为16层,因此它被称为VGG16。如果要将VGG16的结构用于一个新的数据集,首先要去掉fc8这一层。原因是fc8层的输入是fc7的特征,输出是1000类的概率,这1000类正好对应了ImageNet模型中的1000个类别。在自己的数据中,类别数一般不是1000类,因此fc8层的结构在此时是不适用的,必须将fc8层去掉,重新采用符合数据集类别数的全连接层,作为新的fc8。比如数据集为5类,那么新的fc8的输出也应当是5类。
此外,在训练的时候,网络的参数的初始值并不是随机化生成的,而是采用VGG16在ImageNet上已经训练好的参数作为训练的初始值。这样做的原因在于,在ImageNet数据集上训练过的VGG16中的参数已经包含了大量有用的卷积过滤器,与其从零开始初始化VGG16的所有参数,不如使用已经训练好的参数当作训练的起点。这样做不仅可以节约大量训练时间,而且有助于分类器性能的提高。
载入VGG16的参数后,就可以开始训练了。此时需要指定训练层数的范围。一般来说,可以选择以下几种范围进行训练:
(1):只训练fc8。训练范围一定要包含fc8这一层。因为fc8的结构被调整过,所有它的参数不能直接从ImageNet预训练模型中取得。可以只训练fc8,保持其他层的参数不动。这就相当于将VGG16当作一个“特征提取器”:用fc7层提取的特征做一个Softmax模型分类。这样做的好处是训练速度快,但往往性能不会太好。
(2):训练所有参数。还可以对网络中的所有参数进行训练,这种方法的训练速度可能比较慢,但是能取得较高的性能,可以充分发挥深度模型的威力。
(3):训练部分参数。通常是固定浅层参数不变,训练深层参数。如固定conv1、conv2部分的参数不训练,只训练conv3、conv4、conv5、fc6、fc7、fc8的参数
微调的原理大致意思就是先看懂网络的结构图,然后把网络的一部分修改成自己需要的模型。这种训练方法就是所谓的对神经网络模型做微调。借助微调,可以从预训练模型出发,将神经网络应用到自己的数据集上。
微调(Fine-tune)原理的更多相关文章
- [机器学习]Fine Tune
Fine Tune顾名思义,就是微调.在机器学习中,一般用在迁移学习中,通过控制一些layer调节一些layer来达到迁移学习的目的.这样可以利用已有的参数,稍微变化一些,以适应新的学习任务.所以说, ...
- caffe简易上手指南(三)—— 使用模型进行fine tune
之前的教程我们说了如何使用caffe训练自己的模型,下面我们来说一下如何fine tune. 所谓fine tune就是用别人训练好的模型,加上我们自己的数据,来训练新的模型.fine tune相当于 ...
- caffe fine tune 复制预训练model的参数和freeze指定层参数
复制预训练model的参数,只需要重新copy一个train_val.prototxt.然后把不需要复制的层的名字改一下,如(fc7 -> fc7_new),然后fine tune即可. fre ...
- L23模型微调fine tuning
resnet185352 链接:https://pan.baidu.com/s/1EZs9XVUjUf1MzaKYbJlcSA 提取码:axd1 9.2 微调 在前面的一些章节中,我们介绍了如何在只有 ...
- [NLP] TextCNN模型原理和实现
1. 模型原理 1.1 论文 Yoon Kim在论文(2014 EMNLP) Convolutional Neural Networks for Sentence Classification提出Te ...
- 【原创】TextCNN原理详解(一)
最近一直在研究textCNN算法,准备写一个系列,每周更新一篇,大致包括以下内容: TextCNN基本原理和优劣势 TextCNN代码详解(附Github链接) TextCNN模型实践迭代经验总结 ...
- (原)torch中微调某层参数
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/6221664.html 参考网址: https://github.com/torch/nn/issues ...
- 深度学习笔记(六)finetune
转自Caffe fine-tuning 微调网络 一般来说我们自己需要做的方向,比如在一些特定的领域的识别分类中,我们很难拿到大量的数据.因为像在ImageNet上毕竟是一个千万级的图像数据库,通常我 ...
- 目标检测(六)YOLOv2__YOLO9000: Better, Faster, Stronger
项目链接 Abstract 在该论文中,作者首先介绍了对YOLOv1检测系统的各种改进措施.改进后得到的模型被称为YOLOv2,它使用了一种新颖的多尺度训练方法,使得模型可以在不同尺寸的输入上运行,并 ...
- 【目标检测】R-CNN系列与SPP-Net总结
目录 1. 前言 2. R-CNN 2.0 论文链接 2.1 概述 2.2 pre-training 2.3 不同阶段正负样本的IOU阈值 2.4 关于fine-tuning 2.5 对文章的一些思考 ...
随机推荐
- ESP8266开发之旅 网络篇③ Soft-AP——ESP8266WiFiAP库的使用
1. 前言 在前面的篇章中,博主给大家讲解了ESP8266的软硬件配置以及基本功能使用,目的就是想让大家有个初步认识.并且,博主一直重点强调 ESP8266 WiFi模块有三种工作模式: St ...
- Java网络编程(一)Socket套接字
一.基础知识 1.TCP:传输控制协议. 2.UDP:用户数据报协议. 二.IP地址封装 1.InetAddress类的常用方法 getLocalHost() 返回本地主机的InetAddress对象 ...
- spring源码学习(二)
本篇文章,来介绍finishBeanFactoryInitialization(beanFactory);这个方法:这个方法主要是完成bean的实例化,invokeBeanFactoryPostPro ...
- Computer English Notes
Chapter 1 : About Computer Answer the following - Abbreviation LBS - Location-Based Services HTML - ...
- GCC中,可以使用未声明过的函数
今天代码中使用了一个函数,这个函数也是自定义的,但是还没来得及声明和定义,可以编译时竟然未报错,网上查了下果然,GCC中可以使用未声明的函数http://bbs.csdn.net/topics/390 ...
- Kong04- Kong 四大参考说明
Kong 四大参考说明 Kong 的官方有很多详细的参考说明,比如配置文件.命令行.Admin API.代理.负载均衡,接下来我们简单看一下,都提供什么内容. 本文主要基于 Kong 1.3 版本进行 ...
- [考试反思]1009csp-s模拟测试66:依旧
依旧是好一场烂一场. 依旧是那么菜. 依旧是难止颓废. 依旧是在此方仰望,幻想? 上面这段中二的东西是为了防止Parisb说我的标题与内容无关而diss我莫名其妙115的语文. 但是菜是的确是菜... ...
- NOIP模拟测试36考试反思
这次考试..炸裂,归根到底是心态问题,考试的时候T1秒正解,但是调了三个小时死活没调出来,最后弃了,T2极水,没时间打了,T3题看都没看,总而言之就是不行. 教练说的对,一时强不一定一直强,心态其实也 ...
- python学习之【第四篇】:Python中的列表及其所具有的方法
1.前言 列表是Python中最常用的数据类型之一,是以[ ]括起来,每个元素以逗号隔开,而且里面可以存放各种数据类型,而且列表是有序的,有索引值,可切片,方便取值. 2.创建列表 li = ['he ...
- inux下vi命令大全
分类: LINUX 进入vi的命令 vi filename :打开或新建文件,并将光标置于第一行首 vi +n filename :打开文件,并将光标置于第n行首 vi + filename :打开文 ...