基于Pytorch的简单小案例
神经网络的理论知识不是本文讨论的重点,假设读者们都是已经了解RNN的基本概念,并希望能用一些框架做一些简单的实现。这里推荐神经网络必读书目:邱锡鹏《神经网络与深度学习》。本文基于Pytorch简单实现CIFAR-10、MNIST手写体识别,读者可以基于此两个简单案例进行拓展,实现自己的深度学习入门。
环境说明
python 3.6.7
Pytorch的CUP版本
Pycharm编辑器
部分可能报错:参见pytorch安装错误及解决
基于Pytorch的CIFAR-10图片分类
代码实现
# coding = utf-8 import torch
import torch.nn
import numpy as np
from torchvision.datasets import CIFAR10
from torchvision import transforms
from torch.utils.data import DataLoader
from torch.utils.data.sampler import SubsetRandomSampler
import torch.nn.functional as F
import torch.optim as optimizer '''
The compose function allows for multiple transforms.
transform.ToTensor() converts our PILImage to a tensor of
shape (C x H x W) in the range [0, 1]
transform.Normalize(mean, std) normalizes a tensor to a (mean, std)
for (R, G, B)
'''
_task = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
]) # 注意:此处数据集在本地,因此download=False;若需要下载的改为True
# 同样的,第一个参数为数据存放路径
data_path = '../CIFAR_10_zhuanzhi/cifar10'
cifar = CIFAR10(data_path, train=True, download=False, transform=_task) # 这里只是为了构造取样的角标,可根据自己的思路进行拓展
# 此处使用了前百分之八十作为训练集,百分之八十到九十的作为验证集,后百分之十为测试集
samples_count = len(cifar)
split_train = int(0.8 * samples_count)
split_valid = int(0.9 * samples_count) index_list = list(range(samples_count))
train_idx, valid_idx, test_idx = index_list[:split_train], index_list[split_train:split_valid], index_list[split_valid:] # 定义采样器
# create training and validation, test sampler
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
test_samlper = SubsetRandomSampler(test_idx ) # create iterator for train and valid, test dataset
trainloader = DataLoader(cifar, batch_size=256, sampler=train_sampler)
validloader = DataLoader(cifar, batch_size=256, sampler=valid_sampler)
testloader = DataLoader(cifar, batch_size=256, sampler=test_samlper ) # 网络设计
class Net(torch.nn.Module):
"""
网络设计了三个卷积层,一个池化层,一个全连接层
"""
def __init__(self):
super(Net, self).__init__() self.conv1 = torch.nn.Conv2d(3, 16, 3, padding=1)
self.conv2 = torch.nn.Conv2d(16, 32, 3, padding=1)
self.conv3 = torch.nn.Conv2d(32, 64, 3, padding=1)
self.pool = torch.nn.MaxPool2d(2, 2)
self.linear1 = torch.nn.Linear(1024, 512)
self.linear2 = torch.nn.Linear(512, 10) # 前向传播
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 1024)
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x)) return x if __name__ == "__main__": net = Net() # 实例化网络
loss_function = torch.nn.CrossEntropyLoss() # 定义交叉熵损失 # 定义优化算法
optimizer = optimizer.SGD(net.parameters(), lr=0.01, weight_decay=1e-6, momentum=0.9, nesterov=True) # 迭代次数
for epoch in range(1, 31):
train_loss, valid_loss = [], [] net.train() # 训练开始
for data, target in trainloader:
optimizer.zero_grad() # 梯度置0
output = net(data)
loss = loss_function(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
train_loss.append(loss.item()) net.eval() # 验证开始
for data, target in validloader:
output = net(data)
loss = loss_function(output, target)
valid_loss.append(loss.item()) print("Epoch:{}, Training Loss:{}, Valid Loss:{}".format(epoch, np.mean(train_loss), np.mean(valid_loss)))
print("======= Training Finished ! =========") print("Testing Begining ... ") # 模型测试
total = 0
correct = 0
for i, data_tuple in enumerate(testloader, 0): data, labels = data_tuple
output = net(data)
_, preds_tensor = torch.max(output, 1) total += labels.size(0)
correct += np.squeeze((preds_tensor == labels).sum().numpy())
print("Accuracy : {} %".format(correct/total))
实验结果
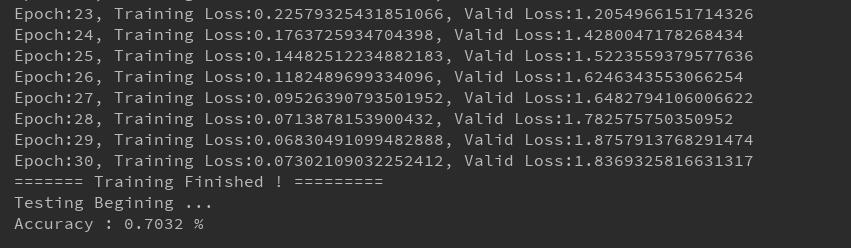
经验总结
1.激活函数的选择。
- 激活函数可选择sigmoid函数或者Relu函数,亲测使用Relu函数后,分类的正确率会高使用sigmoid函数很多;
- Relu函数的导入有两种:import torch.nn.functional as F, 然后F.relu(),还有一种是torch.nn.Relu() 两种方式实验结果没区别,但是推荐使用后者;因为前者是以函数的形式导入的,在模型保存时,F中相关参数会被释放,无法保存下去,而后者会保留参数。
2.预测结果的处理。
Pytorch预测的结果,返回的是一个Tensor,需要处理成数值才能进行准确率计算,.numpy()方法能将Tensor转化为数组,然后使用squeeze能够将数组转化为数值。
3. 数据加载。Pytorch是采用批量加载数据的,因此使用for循环迭代从采样器中加载数据,batch_size参数指定每次加载数据量的大小
4.注意维度。
- 网络设计中的维度。网络层次设计中,要谨记前一层的输出是后一层的输入,维度要对应的上。
- 全连接中的维度。全连接中要从特征图中选取特征,这些特征不是一维的,而全连接输出的结果是一维的,因此从特征图中选取特征作为全连接层输入前,需要将特征展开,例如:x = x.view(-1, 28*28)
基于Pytorch的MNIST手写体识别
代码实现
# coding = utf-8
import numpy as np
import torch
from torchvision import transforms _task = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(
[0.5], [0.5]
)
]) from torchvision.datasets import MNIST # 数据集加载
mnist = MNIST('./data', download=False, train=True, transform=_task) # 训练集和验证集划分
from torch.utils.data import DataLoader
from torch.utils.data.sampler import SubsetRandomSampler # create training and validation split
index_list = list(range(len(mnist))) split_train = int(0.8*len(mnist))
split_valid = int(0.9*len(mnist)) train_idx, valid_idx, test_idx = index_list[:split_train], index_list[split_train:split_valid], index_list[split_valid:] # create sampler objects using SubsetRandomSampler
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
test_sampler = SubsetRandomSampler(test_idx) # create iterator objects for train and valid dataset
trainloader = DataLoader(mnist, batch_size=256, sampler=train_sampler)
validloader = DataLoader(mnist, batch_size=256, sampler=valid_sampler)
test_loader = DataLoader(mnist, batch_size=256, sampler=test_sampler ) # design for net
import torch.nn.functional as F
class NetModel(torch.nn.Module):
def __init__(self):
super(NetModel, self).__init__()
self.hidden = torch.nn.Linear(28*28, 300)
self.output = torch.nn.Linear(300, 10) def forward(self, x):
x = x.view(-1, 28*28)
x = self.hidden(x)
x = F.relu(x)
x = self.output(x)
return x if __name__ == "__main__":
net = NetModel() from torch import optim
loss_function = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, weight_decay=1e-6, momentum=0.9, nesterov=True) for epoch in range(1, 12):
train_loss, valid_loss = [], []
# net.train()
for data, target in trainloader:
optimizer.zero_grad()
# forward propagation
output = net(data)
loss = loss_function(output, target)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
# net.eval()
for data, target in validloader:
output = net(data)
loss = loss_function(output, target)
valid_loss.append(loss.item())
print("Epoch:", epoch, "Training Loss:", np.mean(train_loss), "Valid Loss:", np.mean(valid_loss)) print("testing ... ")
total = 0
correct = 0
for i, test_data in enumerate(test_loader, 0):
data, label = test_data
output = net(data)
_, predict = torch.max(output.data, 1) total += label.size(0)
correct += np.squeeze((predict == label).sum().numpy())
print("Accuracy:", (correct/total)*100, "%")
实验结果
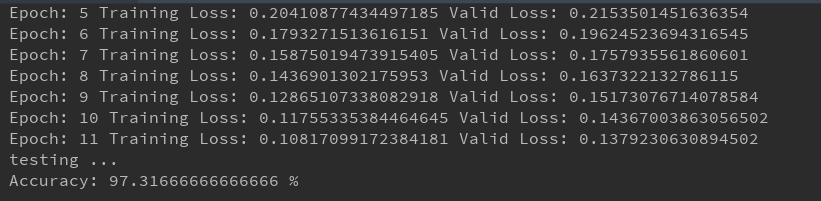
经验总结
1.网络设计的使用只用了一个隐层,单隐层神经网络经过10词迭代,对手写体识别准确率高达97%!!简直变态啊!
2.loss.item()和loss.data[0]。好像新版本的pytorch放弃了loss.data[0]的表达方式。
3.手写体识别的图片是单通道图片,因此在transforms.Compose()中做标准化的时候,只需要指定一个值即可;而cifar中的图片是三通道的,因此需要指定三个参数。
基于Pytorch的简单小案例的更多相关文章
- Angular.js路由 简单小案例
代码案例: <html> <head> <meta charset="utf-8"> <title>AngularJS 路由实例&l ...
- touch滑动事件---简单小案例
html: <!--导航栏头部--><div class="type_nav"> <ul class="clearfix " v- ...
- Vuex-全局状态管理【简单小案例】
前言: Vuex个人见解: 1.state :所有组件共享.共用的数据.理解为不是一个全局变量,不能直接访问以及操作它.2.mutations : 如何操作 state 呢?需要有一个能操作state ...
- angular前端框架简单小案例
一.angular表达式 <head> <meta charset="UTF-8"> <title>Title</title> &l ...
- Session小案例-----简单购物车的使用
Session小案例-----简单购物车的使用 同上篇一样,这里的处理请求和页面显示相同用的都是servlet. 功能实现例如以下: 1,显示站点的全部商品 2.用户点击购买后,可以记住用户选择的商品 ...
- Netty学习——基于netty实现简单的客户端聊天小程序
Netty学习——基于netty实现简单的客户端聊天小程序 效果图,聊天程序展示 (TCP编程实现) 后端代码: package com.dawa.netty.chatexample; import ...
- 一个简单的Maven小案例
Maven是一个很好的软件项目管理工具,有了Maven我们不用再费劲的去官网上下载Jar包. Maven的官网地址:http://maven.apache.org/download.cgi 要建立一个 ...
- 基于C语言libvirt API简单小程序
libvirt API简单小程序 1.程序代码如下 #include<stdio.h> #include<libvirt/libvirt.h> int getDomainInf ...
- Nancy之基于Nancy.Owin的小Demo
前面做了基于Nancy.Hosting.Aspnet和Nancy.Hosting.Self的小Demo 今天我们来做个基于Nancy.Owin的小Demo 开始之前我们来说说什么是Owin和Katan ...
随机推荐
- ios发送短信验证码计时器的swift实现
转载自:http://www.jianshu.com/p/024dd2d6e6e6# Update: Xcode 8.2.1 Swift 3 先介绍一下 属性观测器(Property Observer ...
- 【已解决】ArcGIS Engine无法创建拓扑的问题(CreateTopology)
也许,你的问题是这样的 ①System.Runtime.InteropServices.COMException:"未找到拓扑." ②myTopology结果是null,程序跳转到 ...
- Java 高并发之魂
前置知识 了解Java基本语法 了解多线程基本知识 知识介绍 Synchronized简介:作用.地位.不控制并发的后果 两种用法:对象锁和类锁 多线程访问同步方法的7种情况:是否是static.Sy ...
- mysql设计规范一
原文地址:http://www.jianshu.com/p/33b7b6e0a396 主键 表中每一行都应该有可以唯一标识自己的一列(或一组列). 一个顾客可以使用顾客编号列,而订单可以使用订单ID, ...
- [考试反思]0815NOIP模拟测试22
40分,15名. 1-4:120 75 70 70 35分20名...总之差距极小不想说了 昨天教练说:以后的考试还是联赛知识点,但是难度比联赛高. 没听进去,以为是对于所有人而言的,也就是T1难度变 ...
- NOIP模拟 31
补坑 skyh又AK 赛时榜搜索我的姓: 下一条 ... 自闭了. (只是表达对B哥强烈的崇敬) (如果B哥介意我把名字贴出来请联系我删掉) T1一打眼,好像就一个gcd 康了眼大样例,觉得没啥问题 ...
- EffectiveJava-2
一.使用类库 使用类库的好处: 无须关心方法是如何实现的,由算法专家花了大量时间设计.实现和测试这个方法,不仅保证了正确性,而且一旦有缺陷,下一个版本就会修复. 不必浪费时间为哪些与工作不太相关的问题 ...
- EffectiveJava-1
最近在看EffectiveJava,记录一下,分享一下自己的心得. 一.将局部变量的作用于最小化 在第一次使用的地方进行声明,过早的声明局部变量,会延长局部变量的生命周期,若在代码块外声明变量,当程序 ...
- Python基本数据结构之集合
一道python面试的一个小问题,说怎么使用一行代码将一个列表里的重复元素,其实这里只要将列表转换成集合就可以了. 定义 集合跟我们学的列表有点像,也是可以存一堆数据,不过它有几个独特的特点,令其在整 ...
- Comparable接口的实现和使用
1.什么是Comparable接口 此接口强行对实现它的每个类的对象进行整体排序.此排序被称为该类的自然排序 ,类的 compareTo 方法被称为它的自然比较方法 .实现此接口的对象列表(和数组)可 ...