Spark中Task,Partition,RDD、节点数、Executor数、core数目(线程池)、mem数
Spark中Task,Partition,RDD、节点数、Executor数、core数目的关系和Application,Driver,Job,Task,Stage理解
有部分图和语句摘抄别的博客,有些理解是自己的
梳理一下Spark中关于并发度涉及的几个概念File,Block,Split,Task,Partition,RDD以及节点数、Executor数、core数目的关系。
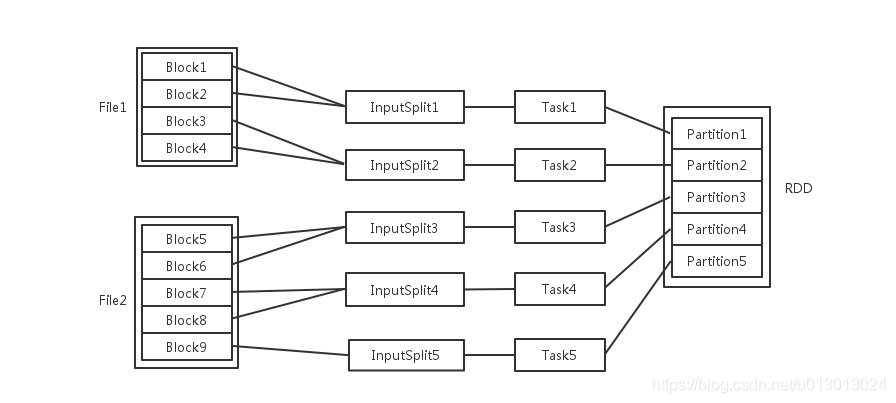
输入可能以多个文件的形式存储在HDFS上,每个File都包含了很多块,称为Block。
当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片,称为InputSplit,注意InputSplit不能跨越文件。
随后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系。
随后这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行。
- 每个节点可以起一个或多个Executor。
- 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
- 每个Task执行的结果就是生成了目标RDD的一个partiton。
注意: 这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程。
而 Task被执行的并发度 = Executor数目 * 每个Executor核数。
至于partition的数目:
- 对于数据读入阶段,例如sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task。
- 在Map阶段partition数目保持不变。
- 在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的。
1,Application
application(应用)其实就是用spark-submit提交的程序。比方说spark examples中的计算pi的SparkPi。一个application通常包含三部分:从数据源(比方说HDFS)取数据形成RDD,通过RDD的transformation和action进行计算,将结果输出到console或者外部存储(比方说collect收集输出到console)。
2,Driver
Spark中的driver感觉其实和yarn中Application Master的功能相类似。主要完成任务的调度以及和executor和cluster manager进行协调。有client和cluster联众模式。client模式driver在任务提交的机器上运行,而cluster模式会随机选择机器中的一台机器启动driver。从spark官网截图的一张图可以大致了解driver的功能。
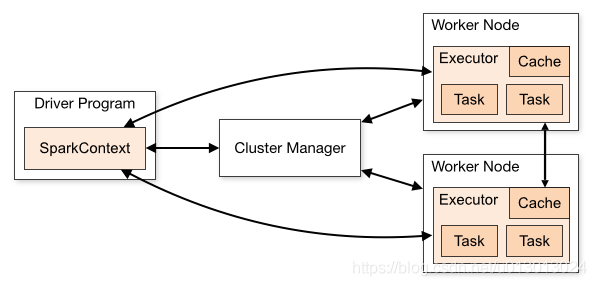
3,Job
Spark中的Job和MR中Job不一样不一样。MR中Job主要是Map或者Reduce Job。而Spark的Job其实很好区别,一个action算子就算一个Job,比方说count,first等。
4, Task
Task是Spark中最新的执行单元。RDD一般是带有partitions的,每个partition的在一个executor上的执行可以任务是一个Task。
5, Stage
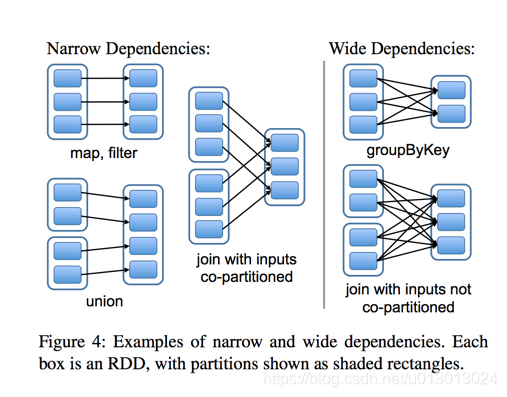
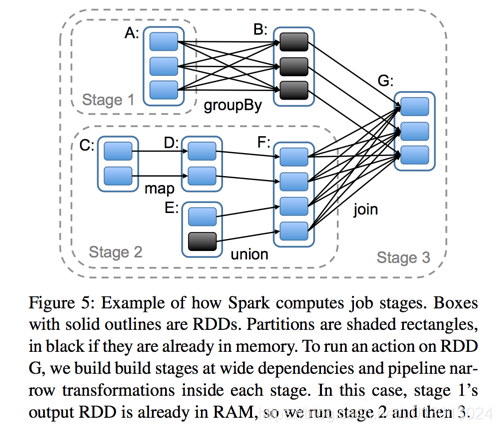
Stage概念是spark中独有的。一般而言一个Job会切换成一定数量的stage。各个stage之间按照顺序执行。至于stage是怎么切分的,首选得知道spark论文中提到的narrow dependency(窄依赖)和wide dependency( 宽依赖)的概念。其实很好区分,看一下父RDD中的数据是否进入不同的子RDD,如果只进入到一个子RDD则是窄依赖,否则就是宽依赖。宽依赖和窄依赖的边界就是stage的划分点
--class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client --driver-memory 4g --num-executors 2 --executor-memory 2g --executor-cores 2 /opt/apps/spark-1.6.0-bin-hadoop2.6/lib/spark-examples*.jar 10参数说明如下所示:
| 参数 | 参考值 | 说明 |
|---|---|---|
| class | org.apache.spark.examples.SparkPi | 作业的主类。 |
| master | yarn | 因为 E-MapReduce 使用 yarn 的模式,所以这里只能是 yarn 模式。 |
| yarn-client | 等同于 –-master yarn —deploy-mode client, 此时不需要指定deploy-mode。 | |
| yarn-cluster | 等同于 –-master yarn —deploy-mode cluster, 此时不需要指定deploy-mode。 | |
| deploy-mode | client | client 模式表示作业的 AM 会放在 Master 节点上运行。要注意的是,如果设置这个参数,那么需要同时指定上面 master 为 yarn。 |
| cluster | cluster 模式表示 AM 会随机的在 worker 节点中的任意一台上启动运行。要注意的是,如果设置这个参数,那么需要同时指定上面 master 为yarn。 | |
| driver-memory | 4g | driver 使用的内存,不可超过单机的 core 总数。 |
| num-executors | 2 | 创建多少个 executor。 |
| executor-memory | 2g | 各个 executor 使用的最大内存,不可超过单机的最大可使用内存。 |
| executor-cores | 2 | 各个 executor 使用的并发线程数目,也即每个 executor 最大可并发执行的 Task 数目。 |
资源计算
- yarn-client 模式的资源计算
节点 资源类型 资源量(结果使用上面的例子计算得到) master core 1 mem driver-memroy = 4G worker core num-executors * executor-cores = 4 mem num-executors * executor-memory = 4G - 作业主程序(Driver 程序)会在 master 节点上执行。按照作业配置将分配 4G(由 —driver-memroy 指定)的内存给它(当然实际上可能没有用到)。
- 会在 worker 节点上起 2 个(由 —num-executors 指定)executor,每一个 executor 最大能分配 2G(由 —executor-memory 指定)的内存,并最大支持 2 个(由—executor-cores 指定)task 的并发执行。
- yarn-cluster 模式的资源计算
节点 资源类型 资源量(结果使用上面的例子计算得到) master 一个很小的 client 程序,负责同步 job 信息,占用很小。 worker core num-executors * executor-cores+spark.driver.cores = 5 mem num-executors * executor-memory + driver-memroy = 8g 说明 这里的 spark.driver.cores 默认是 1,也可以设置为更多。
资源使用的优化
- yarn-client 模式
若您有了一个大作业,使用 yarn-client 模式,想要多用一些这个集群的资源,请参见如下配置:
--master yarn-client --driver-memory 5g –-num-executors 20 --executor-memory 4g --executor-cores 4注意- Spark 在分配内存时,会在用户设定的内存值上溢出 375M 或 7%(取大值)。
- Yarn 分配 container 内存时,遵循向上取整的原则,这里也就是需要满足 1G 的整数倍。
按照上述的资源计算公式,
master 的资源量为:
- core:1
- mem:6G (5G + 375M 向上取整为 6G)
workers 的资源量为:
- core: 20*4 = 80
- mem: 20*5G (4G + 375M 向上取整为 5G) = 100G
可以看到总的资源没有超过集群的总资源,那么遵循这个原则,您还可以有很多种配置,例如:--master yarn-client --driver-memory 5g --num-executors 40 --executor-memory 1g --executor-cores 2--master yarn-client --driver-memory 5g --num-executors 15 --executor-memory 4g --executor-cores 4--master yarn-client --driver-memory 5g --num-executors 10 --executor-memory 9g --executor-cores 6原则上,按照上述的公式计算出来的需要资源不超过集群的最大资源量就可以。但在实际场景中,因为系统,hdfs 以及 E-MapReduce 的服务会需要使用 core 和 mem 资源,如果把 core 和 mem 都占用完了,反而会导致性能的下降,甚至无法运行。
executor-cores 数一般也都会被设置成和集群的可使用核一致,因为如果设置的太多,CPU 会频繁切换,性能并不会提高。
- yarn-cluster 模式
当使用 yarn-cluster 模式后,Driver 程序会被放到 worker 节点上。资源会占用到 worker 的资源池里面,这时若想要多用一些这个集群的资源,请参加如下配置:
--master yarn-cluster --driver-memory 5g --num-executors 15 --executor-memory 4g --executor-cores 4
Spark中Task,Partition,RDD、节点数、Executor数、core数目(线程池)、mem数的更多相关文章
- Spark中Task数量的分析
本文主要说一下Spark中Task相关概念.RDD计算时Task的数量.Spark Streaming计算时Task的数量. Task作为Spark作业执行的最小单位,Task的数量及运行快慢间接决定 ...
- 【原】 Spark中Task的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Stage的提交 http://www.cnblogs.com/yourarebest/p/5356769.html Spark中 ...
- Spark中的partition和block的关系
hdfs中的block是分布式存储的最小单元,类似于盛放文件的盒子,一个文件可能要占多个盒子,但一个盒子里的内容只可能来自同一份文件.假设block设置为128M,你的文件是250M,那么这份文件占3 ...
- 【Java 并发】Executor框架机制与线程池配置使用
[Java 并发]Executor框架机制与线程池配置使用 一,Executor框架Executor框架便是Java 5中引入的,其内部使用了线程池机制,在java.util.cocurrent 包下 ...
- Spark中Task,Partition,RDD、节点数、Executor数、core数目的关系和Application,Driver,Job,Task,Stage理解
梳理一下Spark中关于并发度涉及的几个概念File,Block,Split,Task,Partition,RDD以及节点数.Executor数.core数目的关系. 输入可能以多个文件的形式存储在H ...
- spark——spark中常说RDD,究竟RDD是什么?
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark专题第二篇文章,我们来看spark非常重要的一个概念--RDD. 在上一讲当中我们在本地安装好了spark,虽然我们只有lo ...
- ThreadPoolExecutor中策略的选择与工作队列的选择(java线程池)
工作原理 1.线程池刚创建时,里面没有一个线程.任务队列是作为参数传进来的.不过,就算队列里面有任务,线程池也不会马上执行它们. 2.当调用 execute() 方法添加一个任务时,线程池会做如下判断 ...
- Spring Boot中使用@Async的时候,千万别忘了线程池的配置!
上一篇我们介绍了如何使用@Async注解来创建异步任务,我可以用这种方法来实现一些并发操作,以加速任务的执行效率.但是,如果只是如前文那样直接简单的创建来使用,可能还是会碰到一些问题.存在有什么问题呢 ...
- spark中的pair rdd,看这一篇就够了
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark专题的第四篇文章,我们一起来看下Pair RDD. 定义 在之前的文章当中,我们已经熟悉了RDD的相关概念,也了解了RDD基 ...
随机推荐
- consul集群搭建以及ACL配置
由于时间匆忙,要是有什么地方没有写对的,请大佬指正,谢谢.文章有点水,大佬勿喷这篇博客不回去深度的讲解consul中的一些知识,主要分享的我在使用的时候的一些操作和遇见的问题以及解决办法.当然有些东西 ...
- Altera PLL Locked 失锁的原因
Altera PLL 有时可能会出现失锁的情况,查找了官网资料,有总结到有几个情况下会出现失锁. 官网中的网页如下,是英文的: https://www.altera.com.cn/support/su ...
- 问题三:Appium 的 UIAutomator2 模式下使用 sendKeys 出现错误
在Appium默认的模式下,可以对TextFiled控件进行sendKeys操作: 设置capabilities.setCapability("automationName",&q ...
- c++基础(五)——关联容器
1.关联容器 关联容器中的元素时按照关键字来保存和访问的,与之相对的,顺序容器中的元素时按它们在容器中的位置来顺序保存和访问的.两个主要关联容器是 map 和 set.标准库提供了8个关联容器,这8个 ...
- day38——线程queue、事件event、协程
day38 线程queue 多线程抢占资源 只能让其串行--用到互斥锁 线程queue 队列--先进先出(FIFO) import queue q = queue.Queue(3) q.put(1) ...
- "CreateProcess error=206, 文件名或扩展名太长。",用gradle构建项目创建mapper文件时提示这个错误,是Windows Gradle长类路径问题,官方已经修复
用gradle构建项目mapper文件时,提示这个错误,这个是Windows Gradle长类路径问题, gradle官方已经解决了这个问题. 官网给出的解决方法地址:https://plugins. ...
- 如何访问Pod
本章看点: 理清Deployment,ReplicaSet和Pod的关系,以及三者之间的网络关系,ip地址和端口号 通过Pod进入docker容器修改里面的内容 外部网络访问Pod里面的应用 一.通过 ...
- Java对list进行分页,subList()方法实现分页
/** * 自定义List分页工具 * @author hanwl */ public class PageUtil { /** * 开始分页 * @param list * @param pageN ...
- 9 同时搜索多个index,或多个type
搜索所有index(慎用): GET /_search 搜一个索引下,所有type,(不指定type即可) GET /beauties/_search 搜多个索引,则多个索引间,用逗号(,)分隔开 ...
- ubuntu ufw 配置
ubuntu ufw 配置 Ubuntu 18.04 LTS 系统中已经默认附带了 UFW 工具,如果您的系统中没有安装,可以在「终端」中执行如下命令进行安装: 1 sudo apt install ...