12、基于yarn的提交模式
一、三种提交模式
1、Spark内核架构,其实就是第一种模式,standalone模式,基于Spark自己的Master-Worker集群。 2、第二种,是基于YARN的yarn-cluster模式。 3、第三种,是基于YARN的yarn-client模式。 4、如果,你要切换到第二种和第三种模式,很简单,将我们之前用于提交spark应用程序的spark-submit脚本,加上--master参数,设置为yarn-cluster,或yarn-client,即可。
如果你没设置,那么,就是standalone模式。
二、基于YARN的提交模式
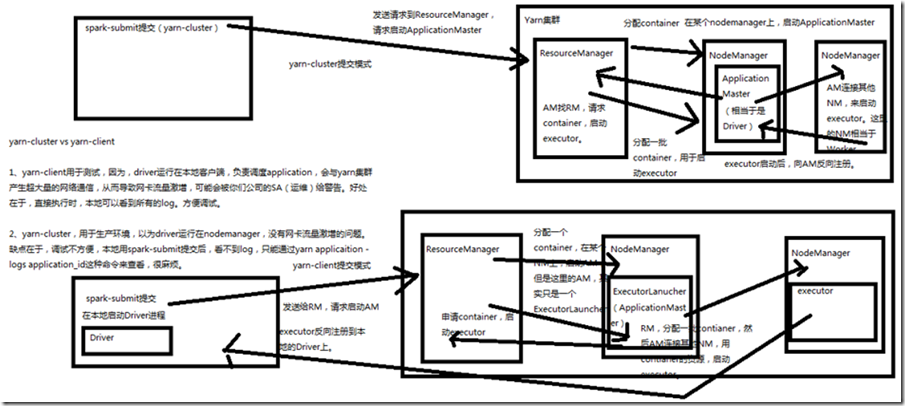
1、基于YARN的yarn-cluster模式
流程详细分析: spark-submit提交(yarn-cluster),发送请求到ResourceManager,请求启动ApplicationMaster,ResourceManager接收到请求后,会在某个NodeManager上分配container,启动ApplicationMaster
ResourceManager分配Container,在某个NodeManager上,启动ApplicationMaster ApplicationMaster(相当于是Driver) ApplicationMaster找ResourceManager,请求container,启动Executor ResourceManager分配一批container,用于启动Executor
ApplicationMaster所在的NodeManager上,可能会启动Executor ApplicationMaster连接其他NodeManager,来启动Executor,这里的NameNode相当于Wroker
Executor启动后,向ApplicationMaster反向注册
2、基于YARN的yarn-client模式
流程详细分析:
spark-submit提交(yarn-client),会在本地启动Driver进程
发送给ResourceManager,请求启动ApplicationMaster ResourceManager分配Container,在某个NodeManager上启动ApplicationMaster,但这里的ApplicationMaster,其实只是一个ExecutorLauncher ExecutorLauncher(ApplicationMaster)申请Container,启动executor ResourceManager分配一批Container
,ExecutorLauncher(ApplicationMaster)所在的NodeManager上,可能会启动Executor ExecutorLauncher(ApplicationMaster)连接其他NodeManager,用Container资源,启动Executor
Executor反向注册到本地的Driver上
3、以上两种模式对比
1、yarn-client模式用于测试,因为driver运行在本地客户端,负责调度application,会与yarn集群产生超大量的网络通信,从而导致网卡流量激增,
可能会被公司的运维给警告,好处在于,直接执行时,本地可以看到所有log,方便调试 2、
yarn-cluster,用于生产环境,因为driver运行在NodeManager,没有网卡流量激增的问题,缺点在于,调试不方便,本地用spark-submit提交后,看不到log,
只能通过yarn application -logs application_id这种命令来查看,很麻烦
4、设置
##修改spark-env.sh
[root@spark1 ~]# vim /usr/local/spark/conf/spark-env.sh #写入hadoop的home
export HADOOP_HOME=/usr/local/hadoop ###脚本文件 yarn-cluster: /opt/module/spark/bin/spark-submit \ --class com.zj.spark.core.WordCountCluster \ --master yarn-cluster \ --num-executors 3 \ --driver-memory 100m \ --executor-memory 100m \ --executor-cores 3 \
/opt/module/datas/sparkstudy/java/mysparkstudy-1.0-SNAPSHOT-jar-with-dependencies.jar \ yarn-client:
/opt/module/spark/bin/spark-submit \ --class com.zj.spark.core.WordCountCluster \ --master yarn-client \ --num-executors 3 \ --driver-memory 100m \ --executor-memory 100m \ --executor-cores 3 \ /opt/module/datas/sparkstudy/java/mysparkstudy-1.0-SNAPSHOT-jar-with-dependencies.jar \
12、基于yarn的提交模式的更多相关文章
- spark基于yarn的两种提交模式
一.spark的三种提交模式 1.第一种,Spark内核架构,即standalone模式,基于Spark自己的Master-Worker集群. 2.第二种,基于YARN的yarn-cluster模式. ...
- Spark剖析-宽依赖与窄依赖、基于yarn的两种提交模式、sparkcontext原理剖析
Spark剖析-宽依赖与窄依赖.基于yarn的两种提交模式.sparkcontext原理剖析 一.宽依赖与窄依赖 二.基于yarn的两种提交模式深度剖析 2.1 Standalne-client 2. ...
- Spark运行模式_基于YARN的Resource Manager的Custer模式(集群)
使用如下命令执行应用程序: 和"基于YARN的Resource Manager的Client模式(集群)"运行模式,区别如下: 在Resource Manager端提交应用程序,会 ...
- Flink源码阅读(一)——Flink on Yarn的Per-job模式源码简析
一.前言 个人感觉学习Flink其实最不应该错过的博文是Flink社区的博文系列,里面的文章是不会让人失望的.强烈安利:https://ververica.cn/developers-resource ...
- 基于事件的异步模式(EAP)
什么是EAP异步编程模式 EAP基于事件的异步模式是.net 2.0提出来的,实现了基于事件的异步模式的类将具有一个或者多个以Async为后缀的方法和对应的Completed事件,并且这些类都支持异步 ...
- Entity Framework 实体框架的形成之旅--基于泛型的仓储模式的实体框架(1)
很久没有写博客了,一些读者也经常问问一些问题,不过最近我确实也很忙,除了处理日常工作外,平常主要的时间也花在了继续研究微软的实体框架(EntityFramework)方面了.这个实体框架加入了很多特性 ...
- Event-based Asynchronous Pattern Overview基于事件的异步模式概览
https://msdn.microsoft.com/zh-cn/library/wewwczdw(v=vs.110).aspx Applications that perform many task ...
- 基于Java 生产者消费者模式(详细分析)
Java 生产者消费者模式详细分析 本文目录:1.等待.唤醒机制的原理2.Lock和Condition3.单生产者单消费者模式4.使用Lock和Condition实现单生产单消费模式5.多生产多消费模 ...
- spark提交模式
spark基本的提交语句: ./bin/spark-submit \ --class <main-class> \ --master <master-url> \ --depl ...
随机推荐
- VS使用日常
一.快捷键 1.Ctrl R+E 选中变量快捷自动生成属性
- webpack+vue搭建vue项目
阅读地址: https://www.jianshu.com/p/23beadfa4aa5 源码地址:https://github.com/Ezoio/IMI-SOURCE-CODE
- trie树(前缀树)详解——PHP代码实现
trie树常用于搜索提示.如当输入一个网址,可以自动搜索出可能的选择.当没有完全匹配的搜索结果,可以返回前缀最相似的可能. 一.Tire树的基本性质 根节点不包含字符,除根节点外每一个节点都只包含一个 ...
- 【阿里云开发】- 安装MySQL数据库
我用的机器配置是 阿里云轻量服务器,系统:CentOS7.3,内存:2G,系统盘40G,1核. 在CentOS中默认安装有MariaDB,这个是MySQL的分支,但为了需要,还是要在系统中安装MySQ ...
- PHP 中使用ajax时一些常见错误总结整理
这篇文章主要介绍了PHP 中使用ajax时一些常见错误总结整理的相关资料,需要的朋友可以参考下 PHP作为后端时,前端js使用ajax技术进行相互信息传送时,经常会出错误,对于新手来说有些手足无措.总 ...
- SSM框架之MyBatis入门介绍
一.什么是MyBatis? MyBatis源自Apache的iBatis开源项目, 从iBatis3.x开始正式更名为MyBatis.它是一个优秀的持久层框架. 二.为什么使用MyBatis? 为了和 ...
- PS1变量设置
\d :代表日期,格式为weekday month date \H :完整的主机名 \h :主机的第一个名字 \t :显示时间为24小时格式(HH:MM:SS) \T :显示时间为12小时格式 \A ...
- Kconfig和Makefile
内核源码树的目录下都有Kconfig和Makefile.在内核配置make menuconfig时,从Kconfig中读出菜单,用户勾选后保存到.config中.在内核编译时,Makefile调用这个 ...
- Mysql8.0.17安装(windows10)
1.因为系统重装 又双叒叕开始了装mysql数据库 下载安装包 https://dev.mysql.com/downloads/mysql/ 2.解压到你想安装的地方 3.解压完是没有图红色框中的文 ...
- Redhat下Oracle 12c单节点安装
操作系统:Redhat6.7 64位[root@Oracle12CDB ~]# more /etc/redhat-release Red Hat Enterprise Linux Server rel ...