Spark GraphX图算法应用【分区策略、PageRank、ConnectedComponents,TriangleCount】
一.分区策略
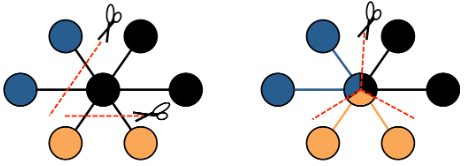
GraphX采用顶点分割的方式进行分布式图分区。GraphX不会沿着边划分图形,而是沿着顶点划分图形,这可以减少通信和存储的开销。从逻辑上讲,这对应于为机器分配边并允许顶点跨越多台机器。分配边的方法取决于分区策略PartitionStrategy并且对各种启发式方法进行了一些折中。用户可以使用Graph.partitionBy运算符重新划分图【可以使用不同分区策略】。默认的分区策略是使用图形构造中提供的边的初始分区。但是,用户可以轻松切换到GraphX中包含的2D分区或其他启发式方法。
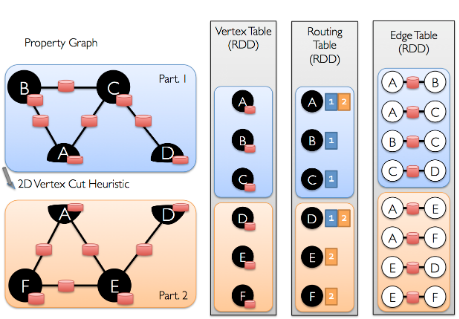
一旦对边进行了划分,高效图并行计算的关键挑战就是将顶点属性和边有效结合。由于现实世界中的图通常具有比顶点更多的边,因此我们将顶点属性移到边上。由于并非所有分区都包含与所有顶点相邻的边,因此我们在内部维护一个路由表,该路由表在实现诸如triplets操作所需要的连接时,标示在哪里广播顶点aggregateMessages。
二.测试数据
1.users.txt

2.followers.txt

3.数据可视化

三.PageRank网页排名
1.简介
使用PageRank测量图中每个顶点的重要性,假设从边u到v表示的认可度x。例如,如果一个Twitter用户被许多其他用户关注,则该用户将获得很高的排名。GraphX带有PageRank的静态和动态实现,作为PageRank对象上的方法。静态PageRant运行固定的迭代次数,而动态PageRank运行直到排名收敛【变化小于指定的阈值】。GraphOps运行直接方法调用这些算法。
2.代码实现
package graphx
import org.apache.log4j.{Level, Logger}
import org.apache.spark.graphx.GraphLoader
import org.apache.spark.sql.SparkSession
/**
* Created by Administrator on 2019/11/27.
*/
object PageRank {
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val spark = SparkSession.builder()
.master("local[2]")
.appName(s"${this.getClass.getSimpleName}")
.getOrCreate()
val sc = spark.sparkContext
val graph = GraphLoader.edgeListFile(sc, "D:\\software\\spark-2.4.4\\data\\graphx\\followers.txt")
// 调用PageRank图计算算法
val ranks = graph.pageRank(0.0001).vertices
// join
val users = sc.textFile("D:\\software\\spark-2.4.4\\data\\graphx\\users.txt").map(line => {
val fields = line.split(",")
(fields(0).toLong, fields(1))
})
// join
val ranksByUsername = users.join(ranks).map{
case (id, (username, rank)) => (username, rank)
}
// print
ranksByUsername.foreach(println)
}
}
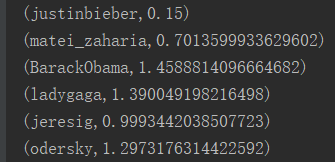
3.执行结果
四.ConnectedComponents连通体算法
1.简介
连通体算法实现把图划分为多个子图【不进行节点切分】,清除孤岛子图【只要一个节点的子图】。其使用子图中编号最小的顶点ID标记子图。
2.代码实现
package graphx
import org.apache.log4j.{Level, Logger}
import org.apache.spark.graphx.GraphLoader
import org.apache.spark.sql.SparkSession
/**
* Created by Administrator on 2019/11/27.
*/
object ConnectedComponents {
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val spark = SparkSession.builder()
.master("local[2]")
.appName(s"${this.getClass.getSimpleName}")
.getOrCreate()
val sc = spark.sparkContext
val graph = GraphLoader.edgeListFile(sc, "D:\\software\\spark-2.4.4\\data\\graphx\\followers.txt")
// 调用connectedComponents连通体算法
val cc = graph.connectedComponents().vertices
// join
val users = sc.textFile("D:\\software\\spark-2.4.4\\data\\graphx\\users.txt").map(line => {
val fields = line.split(",")
(fields(0).toLong, fields(1))
})
// join
val ranksByUsername = users.join(cc).map {
case (id, (username, rank)) => (username, rank)
}
val count = ranksByUsername.count().toInt
// print
ranksByUsername.map(_.swap).takeOrdered(count).foreach(println)
}
}
3.执行结果

五.TriangleCount三角计数算法
1.简介
当顶点有两个相邻的顶点且它们之间存在边时,该顶点是三角形的一部分。GraphX在TriangleCount对象中实现三角计数算法,该算法通过确定经过每个顶点的三角形的数量,从而提供聚类的度量。注意,TriangleCount要求边定义必须为规范方向【srcId < dstId】,并且必须使用Graph.partitionBy对图进行分区。
2.代码实现
package graphx
import org.apache.log4j.{Level, Logger}
import org.apache.spark.graphx.{PartitionStrategy, GraphLoader}
import org.apache.spark.sql.SparkSession
/**
* Created by Administrator on 2019/11/27.
*/
object TriangleCount {
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val spark = SparkSession.builder()
.master("local[2]")
.appName(s"${this.getClass.getSimpleName}")
.getOrCreate()
val sc = spark.sparkContext
val graph = GraphLoader.edgeListFile(sc, "D:\\software\\spark-2.4.4\\data\\graphx\\followers.txt", true)
.partitionBy(PartitionStrategy.RandomVertexCut)
// 调用triangleCount三角计数算法
val triCounts = graph.triangleCount().vertices
// map
val users = sc.textFile("D:\\software\\spark-2.4.4\\data\\graphx\\users.txt").map(line => {
val fields = line.split(",")
(fields(0).toLong, fields(1))
})
// join
val triCountByUsername = users.join(triCounts).map { case (id, (username, tc)) =>
(username, tc)
}
val count = triCountByUsername.count().toInt
// print
triCountByUsername.map(_.swap).takeOrdered(count).foreach(println)
}
}
3.执行结果
Spark GraphX图算法应用【分区策略、PageRank、ConnectedComponents,TriangleCount】的更多相关文章
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
- Spark GraphX从入门到实战
第1章 Spark GraphX 概述 1.1 什么是 Spark GraphX Spark GraphX 是一个分布式图处理框架,它是基于 Spark 平台提供对图计算和图挖掘简洁易用的而丰 ...
- Spark Graphx编程指南
问题导读1.GraphX提供了几种方式从RDD或者磁盘上的顶点和边集合构造图?2.PageRank算法在图中发挥什么作用?3.三角形计数算法的作用是什么?Spark中文手册-编程指南Spark之一个快 ...
- 2. Spark GraphX解析
2.1 存储模式 2.1.1 图存储模式 巨型图的存储总体上有边分割和点分割两种存储方式 1)边分割(Edge-Cut):每个顶点都存储一次,但有的边会被打断分到两台机器上.这样做的好处是节省存储空间 ...
- Spark—GraphX编程指南
Spark系列面试题 Spark面试题(一) Spark面试题(二) Spark面试题(三) Spark面试题(四) Spark面试题(五)--数据倾斜调优 Spark面试题(六)--Spark资源调 ...
- 明风:分布式图计算的平台Spark GraphX 在淘宝的实践
快刀初试:Spark GraphX在淘宝的实践 作者:明风 (本文由团队中梧苇和我一起撰写,并由团队中的林岳,岩岫,世仪等多人Review,发表于程序员的8月刊,由于篇幅原因,略作删减,本文为完整版) ...
- Apache Spark GraphX的体系结构
1. 整体架构 GraphX 的整体架构(如图 1所示)可以分为三部分. 图 1 GraphX 架构 存储和原语层: Graph 类是图计算的核心类.内部含有 VertexRDD. EdgeRDD ...
- 1. Spark GraphX概述
1.1 什么是Spark GraphX Spark GraphX是一个分布式图处理框架,它是基于Spark平台提供对图计算和图挖掘简洁易用的而丰富的接口,极大的方便了对分布式图处理的需求.那么什么是图 ...
- Spark Graphx
Graphx 概述 Spark GraphX是一个分布式图处理框架,它是基于Spark平台提供对图计算和图挖掘简洁易用的而丰富的接口,极大的方便了对分布式图处理的需求. ...
随机推荐
- 【Java】Spring
AnnotationConfigApplicationContext:从一个或多个基于Jav a的配置类中加载Spring应用上下文.AnnotationConfigWebApplicationCon ...
- JDOJ3010 核反应堆
JDOJ3010 核反应堆 https://neooj.com/oldoj/problem.php?id=3010 题目描述 某核反应堆有两类事件发生: 高能质点碰击核子时,质点被吸收,放出3个高能质 ...
- F5 开发
产品试用申请 https://www.f5.com/trials 默认终端登录密码 root/default 默认网页登录信息 admin/admin logstash添加user agent插件 h ...
- [LeetCode] 45. Jump Game II 跳跃游戏之二
Given an array of non-negative integers, you are initially positioned at the first index of the arra ...
- Go Windows 环境安装及配置(一)
首先安装windows的包 go1.12.6.windows-amd64.msi cmd 查看下环境变量 go env set GOARCH=amd64 --架构 amd64/arm set GOBI ...
- win10配置jdk1.8环境变量
1,安装好jdk之后,目录如下 2,右键计算机 - 属性 - 高级系统设置 3,环境变量 4,新增系统变量JAVA_HOME,输入内容D:\work\Program Files\Java\jdk1.8 ...
- visual studio远程调试 remote debugger
下载远程debug工具: https://docs.microsoft.com/zh-cn/visualstudio/debugger/remote-debugging?view=vs-2015 或者 ...
- Qt 操作SQLite数据库
项目中通常需要采用各种数据库(如 Qracle.SQL Server.MySQL等)来实现对数据的存储.查询等功能.下面讲解如何在 Qt 中操作 SQlite 数据库. 一.SQLite 介绍 Sql ...
- contentType: 'application/json' C#后台怎么处理
contentType: 'application/json' 的处理如下: $(function () { $.ajax({ 'url': "/Home/Send2SHengPi" ...
- Loj #2570. 「ZJOI2017」线段树
Loj #2570. 「ZJOI2017」线段树 题目描述 线段树是九条可怜很喜欢的一个数据结构,它拥有着简单的结构.优秀的复杂度与强大的功能,因此可怜曾经花了很长时间研究线段树的一些性质. 最近可怜 ...