基于图的异常检测(三):GraphRAD
基于图的异常检测(三):GraphRAD

论文:《GraphRAD: A Graph-based Risky Account Detection System》
作者:Jun Ma(Amazon),Danqing Zhang(Berkeley)
来源:MLG ' 18
本文介绍Amazon基于图的欺诈交易账户检测系统,相比LOCKINFER 和 OddBall,本文是面向实际业务设计的检测系统,并使用了标签数据。
早期做过十分类似的项目,在可视化关联分析的基础上,为案件调查人员提供智能风险团伙分析服务。所以个人还是比较认可的,在整个系统设计及社区发现模块比较有借鉴价值。
1.背景
应用场景:黑产通过窃取支付信息在Amazon的在线零售商户购买商品获利。
假设:在“欺诈社区”中欺诈账户间连接紧密,而与社区外的账户连接稀疏。
检测系统目标:给予账户之间关系图和一批黑种子,系统检测出有潜在风险的社区及账户供专家调查。并满足以下特性:
- 检测需要做到准实时,以及时止损。
- 返回的可疑社区不能太大和重叠,减少专家工作量。
- 每个账户需要有风险评分,专家根据评分决定优先级。
- 目标是对已有规则引擎的补充,额外发现未识别的欺诈账户。
2.系统框架
大概思路是:通过最近交易事件提取一批黑种子账户,构建账户之间关系网络,然后识别和过滤社区,然后为社区中节点打分,然后返回结果。
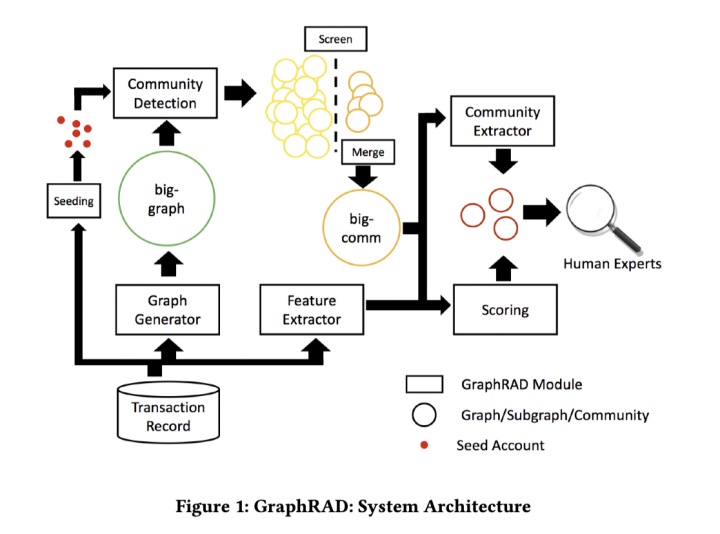
流程介绍:
- Transaction Record:交易事件数据查询接口模块,交易事件字段包括交易时间、账户id、收货地址、决策引擎结果(Trusted、Fraud、Risky),提供一段时间查询交易事件的接口。
- Graph Generator:构建账户之间关系图“big-graph”模块,通过某些共享属性(如收货地址等)建立连边。
- Seeding:筛选黑种子模块,决策引擎中标记为Fraud 以及 部分Risky的账户(根据启发式规则)。
- Community Detection:局部社区发现模块,以黑种子账户为输入,识别出围绕种子的一个个局部社区。算法是Personal PageRank变种ACL,线性复杂度。
- Screen + Merge:过滤及合并:根据风险大小过滤一些局部社区,然后合并成这些局部社区成“big-comm”(局部社区之间会部分重叠,合并减少冗余)。
- Community Extractor:最终社区抽取,基于上面ACL算法得到的基于PPR向量,通过层次聚类得到最终的社区
- Feature Extractor:提取“big-comm”中节点特征,基于交易数据,特征使用决策引擎规则
- Scoring:基于图的惩罚项,训练半监督模型,为每个节点评分
最后给专家提供社区结构和节点评分以供调查使用。
3.核心模块
3.1 构建网络(Graph Generator)
数据来源:最近的交易事件
例如 有两个交易事件:
- 交易事件1:账户A,收货地址为:杭州市西湖区蒋村花园23幢
- 交易事件2:账户B,收货地址为:杭州市西湖区蒋村花园23幢
因为账户A和账户B共享同一个收货地址,故他们会有一条边,以此来建立账户与账户之间关系网络。
实践中如共享同一个设备、同一个IP都可以作为连边条件。
3.2 社区发现及过滤
该模块是本文的比较有意思的地方,不是对网络进行全局的划分,而是先以欺诈账户为种子节点,找到每一个种子节点所在的局部社区,然后对这一个个局部社区进行过滤和合并成一个大社区,最后对这大社区进行划分,得到一个个不重叠的社区。
这样做的优势是:
- 计算复杂度非常低,局部社区发现计算复杂度仅跟输出的结果线性相关。
- 个人认为还有个优势是降噪和考虑用户需求,通过加入黑种子、社区过滤等人为干预方式,降低数据噪声,控制社区规模和冗余,方便专家进行案件审查。
下图比较是直观的一个全局和局部社区发现的对比:
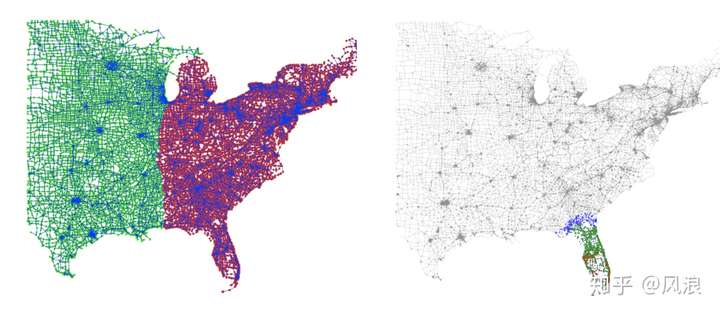
3.2.1 局部社区发现(Community Detection)
以黑种子节点为输入,使用基于Personal Pagerank局部社区算法ACL,该算法比较经典, 复杂度仅取决于输出结果。
算法使用电阻率(conductance)作为评价指标(模块度是全局的):

后面会补上对ACL的解读。
3.2.2 过滤和合并(Screen + Merge)
因为局部社区发现返回的结果是一个个围绕着黑种子的局部社区,必然会有冗余
另外局部社区规模非常小,可能是不存在是个体风险,而不是群体风险。
故需要对局部社区进行过滤,本文是先过滤掉规模较小的局部社区,然后对每个局部社区建一个风险评分模型,再过滤掉风险较低局部社区(y怎么定义用什么特征没仔细说)。
(个人觉得过滤环节不用做太多的操作,简单原则。另外对社区评分模型不好做的,考验泛化能力,还不如用规则)
过滤完后再对这一个个局部社区进行合并,组成一个“大社区“(其实就是将所有节点和边都放在一起)。
3.2.3 社区提取(Community Extractor)
因为局部社区发现用的是基于personal pagerank 的方法,可以得到每个节点的一个pagerank 向量,表示节点与其他节点的相似度。将该一个个向量转换成矩阵,并用层次聚类的方法得到最终的社区。 社区数量k的设置控制社区规模,方便专家分析。
3.3 节点评分(Scoring)
在“大社区”上为每个节点打上一个分数,方便专家分析时确定优先级及过滤低评分的节点。
本文对比了Node2vec、GCN和在基于图惩罚项的模型给节点评分,发现基于图惩罚项的模型效果是最好的(也许是样本量有限?按理说应该是GCN好)。
基于图惩罚项的模型即在有监督损失如交叉熵中加入图的惩罚项(相邻节点的预测结果是相近的),这样在训练时不仅考虑了有标签节点,也考虑了无标签的相邻节点,故称为半监督学习。
特征是用了决策引擎中的规则,标签y定义即是否欺诈。
3.4 例子
“大社区“
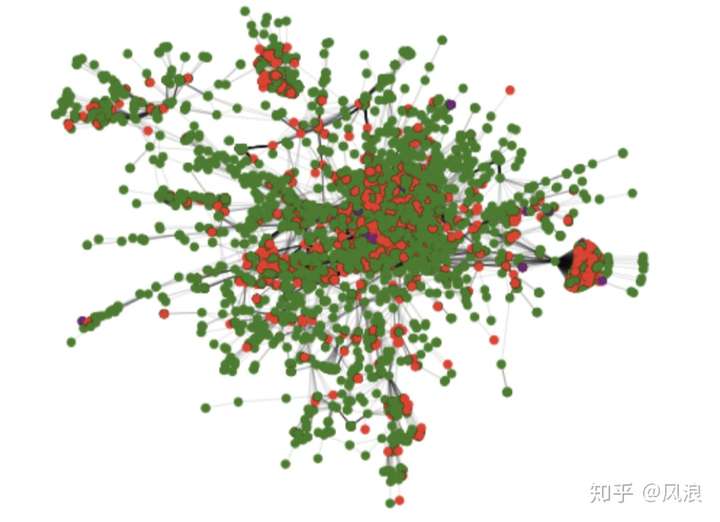
最终返回的一个个社区
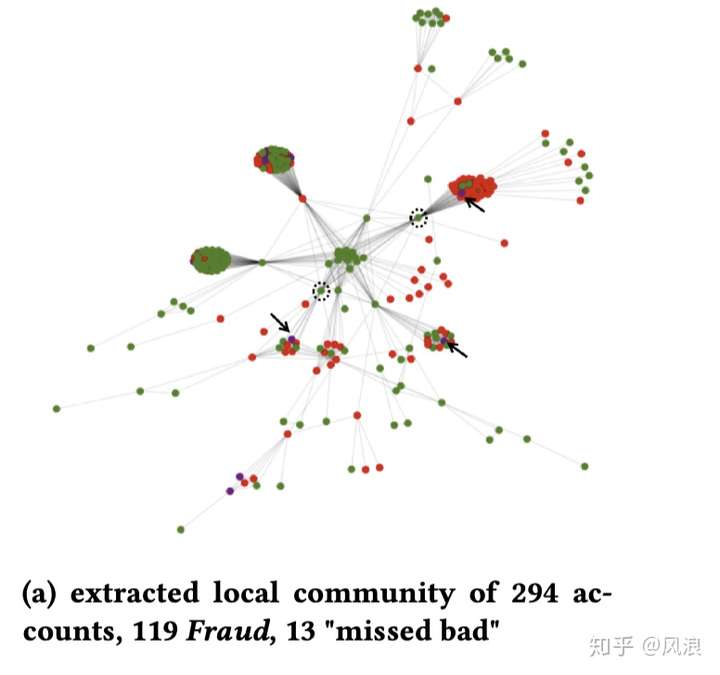
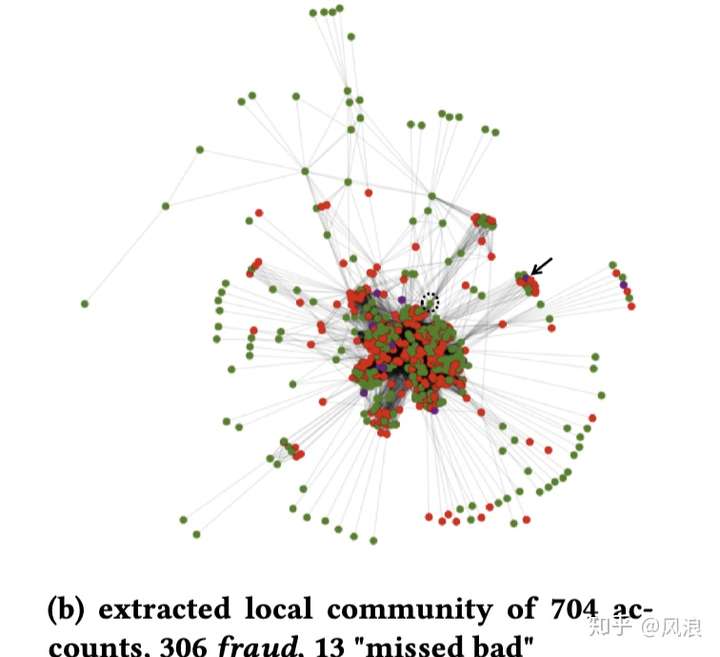
4. 效果评估
该检测系统目标是 发现更多规则引擎没有发现的欺诈账户,而不是去跟规则引擎去PK,故评价标准是“missed bad” ——检测到的未发现的欺诈账户占比 (通过专家标注,用比例的原因是对于准确率的考量)
首先与随机抽样对比,系统每一个模块的missed bad情况,证明好的系统每一个模块检测比例应该是递增的:
- 随机抽样:0.017%
- 经过局部社区发现和过滤合并得到的大社区上:0.054%
- 经过社区提取后:1.51%
- 根据节点评分排序和过滤: 2.77%
上述模块中的missed bad 没有考虑,被决策引擎判为正常的欺诈账户,故真实结果应该会更高。
另外对比简单规则——欺诈节点直接相连的邻居认为是欺诈的对比,GraphRAD检测还是有比较大的增益的。

基于图的异常检测(三):GraphRAD的更多相关文章
- 基于高斯分布的异常检测(Anomaly Detection)算法
记得在做电商运营初期,每每为我们频道的促销活动锁取得的“超高”销售额感动,但后来随着工作的深入,我越来越觉得这里面水很深.商家运营.品类运营不断的通过刷单来获取其所需,或是商品搜索排名,或是某种kpi ...
- kaggle信用卡欺诈看异常检测算法——无监督的方法包括: 基于统计的技术,如BACON *离群检测 多变量异常值检测 基于聚类的技术;监督方法: 神经网络 SVM 逻辑回归
使用google翻译自:https://software.seek.intel.com/dealing-with-outliers 数据分析中的一项具有挑战性但非常重要的任务是处理异常值.我们通常将异 ...
- 基于变分自编码器(VAE)利用重建概率的异常检测
本文为博主翻译自:Jinwon的Variational Autoencoder based Anomaly Detection using Reconstruction Probability,如侵立 ...
- 异常检测-基于孤立森林算法Isolation-based Anomaly Detection-1-论文学习
论文http://202.119.32.195/cache/10/03/cs.nju.edu.cn/da2d9bef3c4fd7d2d8c33947231d9708/tkdd11.pdf 1. INT ...
- Abnormal Detection(异常检测)和 Supervised Learning(有监督训练)在异常检测上的应用初探
1. 异常检测 VS 监督学习 0x1:异常检测算法和监督学习算法的对比 总结来讲: . 在异常检测中,异常点是少之又少,大部分是正常样本,异常只是相对小概率事件 . 异常点的特征表现非常不集中,即异 ...
- LSTM UEBA异常检测——deeplog里其实提到了,就是多分类LSTM算法,结合LSTM预测误差来检测异常参数
结合CNN的可以参考:http://fcst.ceaj.org/CN/article/downloadArticleFile.do?attachType=PDF&id=1497 除了行为,其他 ...
- 网络KPI异常检测之时序分解算法
时间序列数据伴随着我们的生活和工作.从牙牙学语时的“1, 2, 3, 4, 5, ……”到房价的走势变化,从金融领域的刷卡记录到运维领域的核心网性能指标.时间序列中的规律能加深我们对事物和场景的认识, ...
- 异常检测LOF
局部异常因子算法-Local Outlier Factor(LOF)在数据挖掘方面,经常需要在做特征工程和模型训练之前对数据进行清洗,剔除无效数据和异常数据.异常检测也是数据挖掘的一个方向,用于反作弊 ...
- 时间序列异常检测算法S-H-ESD
1. 基于统计的异常检测 Grubbs' Test Grubbs' Test为一种假设检验的方法,常被用来检验服从正太分布的单变量数据集(univariate data set)\(Y\) 中的单个异 ...
随机推荐
- 解决飞秋绑定TCP错误
电脑不能打开网页,局域网的飞秋不能运行:提示TCP/IP错误,错误事件代码:10106.重装TCP/IP协议后就OK了…… 步骤如下:1.删除这两个注册表选项:(打开注册表命令regedit.如果不能 ...
- python 读写.tar.gz文件 -- UnicodeDecodeError
在用pip install 安装库的时候,偶尔会出现编码错误(如:UnicodeDecodeError: 'gbk' codec can't decode byte),对此我们可先将包下载下来(一般为 ...
- MDK编译优化笔记
在一次使用MDk的编译优化等级比较高的时候发现编译不优化时功能正常,开了优化等级02就出现异常,调试中看了很多博客总结一下. 一个变量,如果你的主程序要用到,同时中断还要用到,要加volatile修饰 ...
- luoguP4331 [BOI2004]Sequence 数字序列
题意 大力猜结论. 首先将所有\(a_i\)变为\(a_i-i\),之后求不严格递增的\(b_i\),显然答案不变,最后\(b_i\)加上\(i\)即可. 考虑两种特殊情况: 1.\(a[]\)是递增 ...
- git使用遇到问题1
1.上传代码过程中遇到 git help gc错误解决方法,有两种方式,推荐第一种方式. $ git fsck $ git gc --prune=now 如果执行完上面的命令还是不行的话,可以尝试删掉 ...
- 2019 SDN上机第一次作业
2019 SDN上机第一次作业 1. 安装轻量级网络仿真工具Mininet 安装Mininet的步骤 - git clone git://github.com/mininet/mininet - cd ...
- Educational Codeforces Round 69 (Rated for Div. 2) D. Yet Another Subarray Problem 背包dp
D. Yet Another Subarray Problem You are given an array \(a_1, a_2, \dots , a_n\) and two integers \( ...
- Paper | Compression artifacts reduction by a deep convolutional network
目录 1. 故事 2. 方法 3. 实验 这是继SRCNN(超分辨)之后,作者将CNN的战火又烧到了去压缩失真上.我们看看这篇文章有什么至今仍有启发的故事. 贡献: ARCNN. 讨论了low-lev ...
- mybatis报错:Invalid bound statement (not found)
mybatis报错:Invalid bound statement (not found)的原因很多,但是正如报错提示一样,找不到xml中的sql语句,报错的情况分为三种: 第一种:语法错误 Java ...
- Rust从入门到放弃(1)—— hello,world
安装及环境配置 特点:安全,性能,并发 rust源配置 RLS安装 cargo rust管理工具,该工具可以愉快方便的管理rust工程 #!/bin/bash mkdir learn cd learn ...