Python I/O编程 --读写文件、StringIO/ BytesIO
I/O编程
Input/Output 输入/输出
Stream(流)是一个很重要的概念,可以把流想象成一个水管,数据就是水管里的水
Input Stream就是数据从外面(磁盘、网络)流进内存,Output Stream就是数据从内存流到外面去
由于CPU和内存的速度远远高于外设的速度,所以,在I/O编程中,存在速度严重不匹配的问题。例子:比如要把100M的数据写入磁盘(这是output),CPU输出100M只需要0.01s,可是磁盘要接收这100M数据可能需要10s,怎么办呢?有两种解决方法:
第一种:CPU等着,这种模式称为同步IO
第二种:CPU不等着,这种模式称为异步IO
同步和异步的区别:在于是否等待IO执行的结果.
例子:好比你去麦当劳点餐,你说“来个汉堡”,服务员告诉你,对不起,汉堡要现做,需要等待5分钟, 有两种处理方式:
(1)你站在收银台前等了5分钟,拿到汉堡再去逛商场,这是同步IO
(2)你先逛商场,等做好了,服务员再通知你,这样你可以立刻去干别的事情(逛商场),这是异步IO
结论:很明显,使用异步IO来编写程序性能会远远高于同步IO,但是异步IO的缺点是编程模型复杂。而服务员如何通知你汉堡做好了,方法各不相同。
(1) 如果是服务员跑过来找你,这是回调模式
(2)如果服务员发短信通知你,你就要不停地检查手机,这是轮询模式
总之,异步IO的复杂度远远高于同步IO
操作IO的能力都是由操作系统提供的,每一种编程语言都会把操作系统提供的低级C接口封装起来方便使用,Python也不例外
文件读写
读文件(read)和写文件(write)
注意:由于“ \ ”是字符串中的转义符,所以表示路径时,使用“ \\ ”或者 “ / ”或者“ \\ ”
Python对文本文件和二进制文件采用统一的操作步骤,即“ 打开 - 操作 - 关闭”
读写文件的模式说明:
| 访问模式 | 说明 |
| r | 默认模式,以只读方式打开文件,文件的指针将会放在文件的开头。如果文件不存在,返回异常FileNotFoundError |
| w | 打开一个文件只用于写入。如果文件已存在,则将其覆盖。如果文件不存在,创建新文件 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也即是,新的内容会被追加到已有内容之后。如果文件不存在,创建新文件进行写入。 |
| x | 创建写模式,文件不存在则创建,存在则返回异常FileExistsError |
| t | 文本文件模式,默认值 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 |
| wb | 以二进制格式打开,……(其余的与相应模式的用法相同) |
| ab | 以二进制格式打开,……(其余的与相应模式的用法相同) |
| + | 与r/w/x/a/rb/wb/ab一同使用,在原功能基础上,使其同时具有读写功能 |
| b | 二进制文件模式 |
注意:(追加append)
open( )函数:打开一个文件对象
格式:open( 文件名,文件模式)
文件模式:“r”模式表示读取utf-8编码的文本文件; “rb”模式表示读取二进制文件
文件模式:“w”模式表示写文本文件;“wb”模式表示写二进制文件
二进制文件:图片、视频、声音
字符编码:
读取非utf-8编码的文本文件,使用encoding参数,
文本文件夹杂一些非法编码的字符时,open()函数使用errors参数,表示如果遇到编码错误后如何处理,最简单的方式是直接忽略。
f = open('/Users/michael/notfound.txt', 'rb',encoding='gbk',errors='ignore')
读文件——文件存在
如果文件成功打开,读取文件的方式:
read( )方法:一次读取文件的全部内容,Python把内容读到内存,用一个str对象表示;如果文件有10G,内存就爆了,所以保险起见,可以反复调用read(size)方法。
read(size)方法:每次最多读取size个字节的内容。
readline( ):每次读取一行内容
readlines( ):一次读取所有内容并按行返回一个列表list,列表中的每一个元素为文件中的每一行数据。同时,每一个元素结尾都带一个 \n标志。
readlines(h):参数可选,如果给出,读入h行
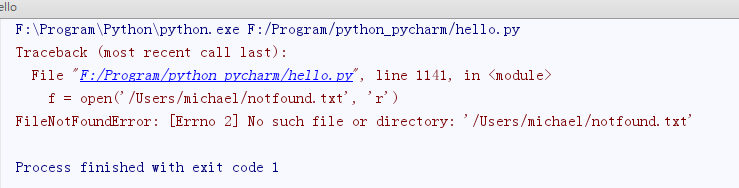
读文件——文件不存在
如果文件不存在,ope( )函数会抛出一个IOError错误,并且给出错误码和详细的信息告诉你文件不存在:
f = open('/Users/michael/notfound.txt', 'r')
运行结果:
写文件
f.write( s ):向文件写入一个字符串或字节流。 要显示地使用 ' \n '对写入文本进行分行,如果不进行分行,每次写入的字符串会被连接起来。
f.writelines( lines ):将一个元素为字符串的列表整体写入文件。 直接将列表类型的各元素连接起来写入文件f。
当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。
只有调用close( )方法时,操作系统才保证把没有写入的数据全部写入磁盘。
忘记调用close( )的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险:
with open('/Users/michael/test.txt', 'w') as f:
f.write('Hello, world!')
close( )方法
文件使用完毕后必须关闭,有两方面原因:
(1)文件对象会占用操作系统的资源。 (2)操作系统同一时间能打开的文件数量也是有限的。
为了保证无论是否出错都能正确地关闭文件,有两种实现方式:
(1)使用try ... finally来实现,因为finally语句块一定会被执行。
(2)with语句:是因为with语句能自动调用close( )方法
使用try ... finally来实现:
try:
f = open('/path/to/file', 'r')
print(f.read())
finally:
if f:
f.close()
with语句:
with open('/path/to/file', 'r') as f:
print(f.read())
这和前面的try ... finally是一样的,但是代码更佳简洁,并且不必调用f.close()方法。
文件的定位读写
背景:在实际开发中,可能会需要从文件的某个特定位置开始读写。此时,需要对文件的读写位置进行定位。
两种定位方式:
(1)获取文件当前的读写位置:tell( )方法
(2)定位到文件的指定读写位置:seek (offset, whence )方法
1、使用tell方法来获取文件当前的读写位置
tell方法返回文件的当前位置,即文件指针当前位置
f=open("theima.txt","r")
str=f.read(4)
print("读取的数据是:",str)
#查找当前位置
position=f.tell()
print("当前文件位置:",position)
2、使用seek方法定位到文件的指定读写位置
格式: seek( offset [ , whence ] )
offset:偏移量,即需要移动的字节数
whence表示方向,有三个值:
(1)SEEK_SET或者0:默认值,表示从文件的起始位置开始偏移
(2)SEEK_CUR或者1:表示从文件的当前位置开始偏移
(3)SEEK_END或者2:表示从文件末尾开始偏移
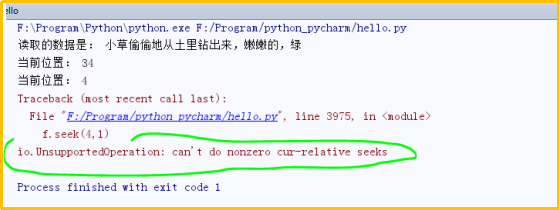
io.UnsupportedOperation: can't do nonzero cur-relative seeks错误
实例:
f=open("E:/test/悯农.txt",'r')
str=f.read(17)
print("读取的数据是:",str)
position=f.tell()
print("当前位置:",position)
f.seek(4,0) #从头开始,偏移4个字节
position=f.tell()
print("当前位置:",position)
f.seek(4,1) #从当前位置开始,偏移4个字节
position=f.tell()
print("当前位置:",position)
f.seek(-4,2)
position=f.tell()
print("当前位置:",position)
f.close()
运行结果:
总结:
seek中whence参数的值:
0:open函数以r,w,带b的二进制模式,就是以任何模式打开文件,都能正常运行
1和2:open函数只能以二进制模式打开文件,才能正常运行,否则就会报出上面的错误
Python的官方文档的解释:
链接地址:https://docs.python.org/3/tutorial/inputoutput.html?highlight=seek
>In text files (those opened without a b in the mode string), only seeks relative to the beginning of the file are allowed (the exception being seeking to the very file end with seek(0, 2)) and the only valid offset values are those returned from the f.tell(), or zero. Any other offset value produces undefined behaviour.
翻译:
在文本文件中(那些在模式字符串中没有b打开的文件),只允许相对于文件的开头进行查找(例外情况是使用seek(0,2)查找文件的结尾),并且唯一有效的偏移值是从f.tell()或零返回的偏移值。任何其他偏移值都会产生未定义的行为。
StringIO和BytesIO
StringIO和BytesIO是在内存中操作str 和bytes(注意:加了s)的方法,使得和读写文件具有一致的接口。
写入时,可以用write 写入,而查看写入的值:使用 getvalue( )函数
读取时,查看值,使用 readline( )、read( )函数
StringIO
只能在内存中操作字符串str
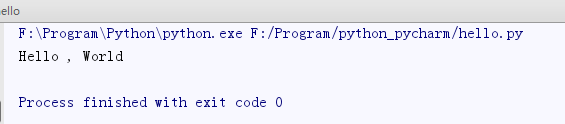
from io import StringIO f=StringIO()
f.write('Hello')
f.write(' , ')
f.write('World')
print(f.getvalue())
要读取StringIO,可以用一个str初始化StringIO,然后,像读文件一样读取:
# read from StringIO:
from io import StringIO
f = StringIO('水面细风生,\n菱歌慢慢声。\n客亭临小市,\n灯火夜妆明。')
while True:
s=f.readline()
if s=="":
break
print('start to print:')
print(s.strip())
运行结果: 可以看出是一行一行打印出来的

BytesIO
BytesIO在内存中读写bytes
注意:1、utf-8编码,使用的是encode参数,中间是英文句号点(.)
2、写入的不是str,而是经过UTF-8编码的bytes。
from io import BytesIO f=BytesIO()
f.write('中文'.encode('utf-8'))
print(f.getvalue())

和StringIO类似,可以用一个bytes初始化BytesIO,然后,像读文件一样读取:
from io import BytesIO
f=BytesIO(b'\xe4\xb8\xad\xe6\x96\x87')
print(f.read())

Python I/O编程 --读写文件、StringIO/ BytesIO的更多相关文章
- Python之IO编程——文件读写、StringIO/BytesIO、操作文件和目录、序列化
IO编程 IO在计算机中指Input/Output,也就是输入和输出.由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘.网络等,就需要IO接口.从 ...
- Python IO编程-读写文件
1.1给出规格化得地址字符串,这些字符串是经过转义的能直接在代码里使用的字符串 需要导入os模块 import os >>>os.path.join('user','bin','sp ...
- Python学习笔记系列——读写文件以及敏感词过滤器的实现
一.读文件 #打开文件,传入文件名和标识符,r代表读 f= open('\\Users\ZC\Desktop\zc.txt','r') #调用read方法一次性读取文件的全部内容,存入内存,用str对 ...
- Python文件读写、StringIO和BytesIO
1 IO的含义 在计算机中,IO是Input/Output的简写,也就是输入和输出. 由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘.网络等,就 ...
- python同步IO编程——StringIO、BytesIO和stream position
主要介绍python两个内存读写IO:StringIO和BytesIO,使得读写文件具有一致的接口 StringIO 内存中读写str.需要导入StringIO >>> from i ...
- Python3 IO编程之文件读写
读写文件是最常见的IO操作.python内置了读写文件的函数,用法和C是兼容的. 读写文件前,我们先必须了解一个,在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序终结操作磁盘, ...
- Python中IO编程-StringIO和BytesIO
Python在内存中读写数据,用到的模块是StringIO和BytesIO StringIO >>> from io import StringIO >>> f = ...
- media静态文件统一管理 操作内存的流 - StringIO | BytesIO PIL:python图片操作库 前端解析二进制流图片(了解) Admin自动化数据管理界面
一.media ''' 1. 将用户上传的所有静态文件统一管理 -- settings.py -- MEDIA_ROOT = os.path.join(BASE_DIR, 'media') 2. 服务 ...
- python同步IO编程——基本概念和文件的读写
IO——Input/Output,即输入输出.对于计算机来说,程序运行时候数据是在内存中的,涉及到数据交换的地方,通常是磁盘.网络等.比如通过浏览器访问一个网站,浏览器首先把请求数据发送给网站服务器, ...
随机推荐
- Java学习:数组的使用和注意事项
数组 数组的概念:是一种容器,可以同时存放多个数据值 数组的特点: 数组是一种引用数据类型 数组当中的多个数据,类型必须统一 数组的长度在程序运行期间不可以改变 数组的初始化:在内存当中创建一个数组, ...
- MVC+Ninject+三层架构+代码生成 -- 总结(一、數據庫)
一.數據表 是參照 別人的庫建表的 ,主鍵都是用int 自增,若是跨數據庫的話,建議使用GUID為主鍵.
- (转载) js 单引号替换成双引号,双引号替换成单引号 操作
引言:刚开始用js遇到不少问题,表示看不懂,为什么替换单引号需要/g,现在知道/g是正则中的匹配全部 原文:http://blog.csdn.net/joyhen/article/details/43 ...
- C# 从注册表判断指定ocx控件是否已注册 以及获取它的注册路径
/// <summary> /// 注册控件 /// </summary> /// <returns></returns> public bool Re ...
- IDEA 环境下更改Maven的仓库镜像提高下载速度
Maven把所有常用的jar包存放在一个集中的仓库(repository)中,项目需要什么jar包和他相关的依赖,只要在pom.xml文件中声明就可了,还是很方便的.repository分两种,一个是 ...
- IDEA控制台中文乱码问题
Tomcat启动时乱码 在tomcat启动时,控制台中的中文为乱码 在idea安装路径的bin文件夹下,找到idea64.exe.vmoptions这个配置文件,添加如下代码 -Dfile.encod ...
- 面试题:android的安全机制有哪些
1 uid . gid . gids Android 的权限分离的基础是建立在 Linux 已有的 uid . gid . gids 基础上的 . UID: Android 在 安装一个应用程序,就会 ...
- xen虚拟化环境安装
1. 操作系统安装 OEL下载地址大全: http://koumm.blog.51cto.com/703525/1283801 # uname -a Linux localhost 2.6.39-40 ...
- ZooKeeper基本介绍
一.入门 1.1 概述 Zookeeper是一个开源的分布式的,为分布式应用提供协调的Apache项目.可用于服务发现,分布式锁,分布式领导选举,配置管理等. Zookeeper从设计模式角度来理解: ...
- js创建对象的三种方式
<script> //创建对象的三种方式 // 1.利用对象字面量(传说中的大括号)创建对象 var obj1 = { uname: 'ash', age: 18, sex: " ...