python selenium IE Firxfor pyinstaller
以前在python环境下selenium 主要用的是chromdriver,这次发现老是报错(Timeout), 实际又是正确的, 可能是和chrome版本不正确,再加上我程序蹦来就在windows环境下。
IE浏览器驱动下载链接:http://selenium-release.storage.googleapis.com/index.html,我这里安装的是v3.0(担心最新的有问题),运行代码发现成功。
Firefox 浏览器下载链接:https://github.com/mozilla/geckodriver/releases/, 我这里安装的是
geckodriver-v0.24.0-win64.zip ,Firefox 是最新的68.0\
如果是在linux(ubuntu)下, 首先下载文件,然后切换到下载目录 执行以下语句:
tar -xvzf geckodriver*
chmod +x geckodriver
sudo mv geckodriver /usr/local/bin/
可以参考 https://blog.csdn.net/qq_23926575/article/details/77268924
把下载文件放在python的安装目录的Scripts下比较方便(这样就可以不用指定路径了)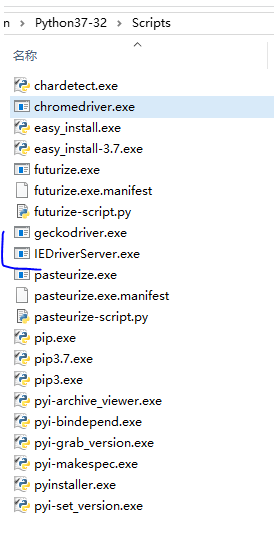
我们在爬网的时候经常需要用到requests(发送http请求)和BeautifulSoup 分析网页的返回内容
csdn:
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.common.exceptions import TimeoutException
import requests
from bs4 import BeautifulSoup
import time opts = Options()
#opts.headless =True
opts.add_argument("--headless")
#br = webdriver.Ie(r'D:/python/IEDriverServer.exe') url="https://blog.csdn.net/xxx/article/list/"
for i in range():
try:
#br = webdriver.Firefox(firefox_options=opts)
br = webdriver.Firefox(options=opts)
#br = webdriver.Ie(r'D:/python/IEDriverServer.exe')
r = requests.get(url+str(i))
soup = BeautifulSoup(r.text,"lxml")
s= soup.find_all("div",class_ ="article-item-box csdn-tracking-statistics")
for item in s:
temp=item.h4.a.get("href")
if temp.startswith("https://blog.csdn.net/xxx"):
try:
print(temp)
br.get(temp)
time.sleep()
except TimeoutException:
br.execute_script("window.stop()")
except Exception as et:
print("Error detail:",et)
except Exception as e:
print("Error:",e)
finally:
br.quit()
cnblogs:
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.common.exceptions import TimeoutException
import requests
from bs4 import BeautifulSoup
import time opts = Options()
opts.add_argument("--headless")
url="https://www.cnblogs.com/xxx/default.html?page="
for i in range():
try:
#br = webdriver.Firefox(firefox_options=opts)
br = webdriver.Firefox(options=opts)
r = requests.get(url+str(i))
soup = BeautifulSoup(r.text,"lxml")
soup = soup.find(id='content')
s= soup.find_all("h2")
for item in s:
temp=item.a.get("href")
if temp.startswith("https://www.cnblogs.com/xxx/"):
try:
print(temp)
br.get(temp)
time.sleep()
except TimeoutException:
br.execute_script("window.stop()")
except Exception as et:
print("Error detail:",et)
except Exception as e:
print("Error:",e)
finally:
br.quit()
然后运行 pyinstaller -F xxx.py来打包成exe文件
在windows用如下语句
opts.headless =True
br = webdriver.Firefox(options=opts)
在ubuntu需要改为
opts.add_argument("--headless")
br = webdriver.Firefox(firefox_options=opts)
如果windows下会有如下提示:


但是在处理https的时候需要注意了:
调用IE来打开对应的网页问题,但是在实际测试中,有些网站是采用https协议的,这时候IE浏览器会弹出如下窗口,一般手动选择后,才可进入登录界面,而在webdriver调用浏览器后,无法继续操作,那么该如何解决呢?
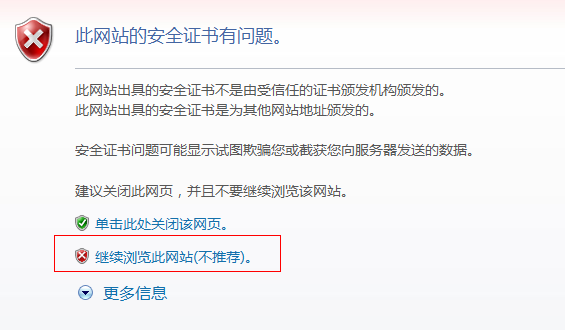
方法一:代码增加配置
首先,我们可以可以查看该网页的源码,分析下代码,可以看到下面部分信息:
<h4 id="continueToSite">
<img src="red_shield.png" ID="ImgOverride" border="0" alt="不推荐图标" class="actionIcon">
<A href='' ID="overridelink" NAME="overridelink" >继续浏览此网站(不推荐)。 </A>
</h4>
述标记部分的,则是上图标记的地方,一般我们点击该图标后即可进入登录窗口,下面代码中通过调用javascript来操作浏览器的提示框,来跳过该提示即可:
#coding=utf-
from selenium import webdriver driver=webdriver.Ie()
firsturl='https://172.172.110.8/Terminal/logon.do'
driver.get(firsturl)
driver.get("javascript:document.getElementById('overridelink').click();")#解决IE提示问题
driver.close()
方法二:浏览器配置
方法二则是通过配置浏览器的方法,解决证书问题,方法如下:
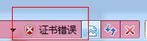
1、点击【继续浏览此网页】后进入登录窗口,此时地址栏后面会出现【证书错误】提示
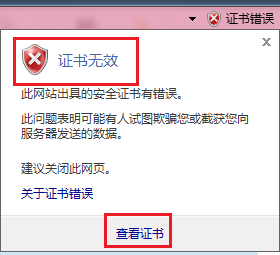
2、点击证书错误——查看证书,提示证书无效,则是因为证书不被信息,需要安装证书
3、弹出证书界面,选择安装证书
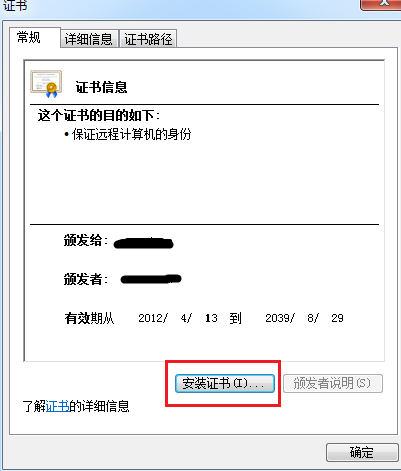
4、按向导操作,注意在下列步骤中需要选择证书位置
5、配置完成后,此时依然是无法登陆的,点击继续浏览后,弹出的错误提示为:不匹配的地址,如下,还需要继续配置
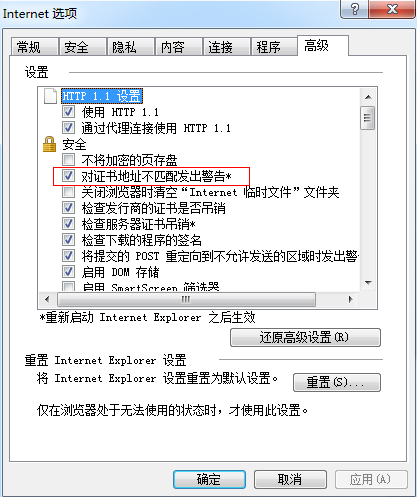
6、Internnet选项——高级下,去除下图中标记项的勾,然后保存
7、重新打开地址,此时仍然会弹出提示,选择继续浏览后,会发现上方的地址栏变为一个小锁,如右图,说明已经配置OK,后续在打开该地址就不会弹出错误选项了。

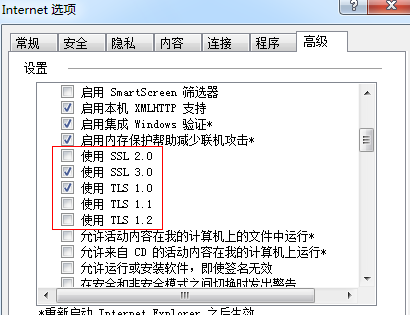
8、若还是无法登陆,可以在Internet选项—安全中:设置安全等级为低等级,并在高级选项下,将下属五项全部勾选后重启浏览器即可
关于调用IE浏览器的错误处理
运行过程中如果出现错误:WebDriverException: Message: u'Unexpected error launching Internet Explorer. Protected Mode settings are not the same for all zones. Enable Protected Mode must be set to the same value (enabled or disabled) for all zones.
解决方法
更改IE的internet选项->安全,将Internet/本地Internet/受信任的站定/受限制的站点中的启用保护模式全部去掉勾,或者全部勾上
python selenium IE Firxfor pyinstaller的更多相关文章
- python+selenium 浏览器的问题
以前用selenium调用firefox是不需要驱动的,最近安装了python3.52+最新的firefox 发现调不起来了 搜索以后发现Firefox 47+需要搞个firefox的驱动 gecko ...
- 一次完整的自动化登录测试-基于python+selenium进行cnblog的自动化登录测试
Web登录测试是很常见的测试!手动测试大家再熟悉不过了,那如何进行自动化登录测试呢!本文作者就用python+selenium结合unittest单元测试框架来进行一次简单但比较完整的cnblog自动 ...
- Python + Selenium 实现登录Office 365
最近捡起之前用的Python + Selenium实现工作中需要的登录Office 365功能.(吐槽:国内网络真是卡,登录Office 365实属不易.另外Selenium这样的网站都要墙,无法理解 ...
- python+selenium+Robot
准备工作: 1.下载python2.7 http://python.org/getit/ 2.下载下载setuptools [python 的基础包工具] 可以帮助我们轻松的下载,构建,安装,升级,卸 ...
- python+selenium运行报错UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
使用python+selenium运行自动化脚本时,打印某一段文字出现UnicodeEncodeError: 'ascii' codec can't encode characters in posi ...
- Functional testing - python, selenium and django
Functional testing - python selenium django - Source Code : from selenium import webdriverfrom sele ...
- python selenium自动化(二)自动化注册流程
需求:使用python selenium来自动测试一个网站注册的流程. 假设这个网站的注册流程分为三步,需要提供比较多的信息: 在这个流程里面,需要用户填入信息.在下拉菜单中选择.选择单选的radio ...
- 使用python selenium进行自动化functional test
Why Automation Testing 现在似乎大家都一致认同一个项目应该有足够多的测试来保证功能的正常运作,而且这些此处的‘测试’特指自动化测试:并且大多数人会认为如果还有哪个项目依然采用人工 ...
- Python+Selenium WebDriver API:浏览器及元素的常用函数及变量整理总结
由于网页自动化要操作浏览器以及浏览器页面元素,这里笔者就将浏览器及页面元素常用的函数及变量整理总结一下,以供读者在编写网页自动化测试时查阅. from selenium import webdrive ...
随机推荐
- mysql的常用查询创建命令
查看所有数据库Show databases;创建数据库Create database 数据库名删除数据库Drop database 数据库名创建表CREATE TABLE t_bookType( ...
- 尚硅谷MySQL高级学习笔记
目录 数据库MySQL学习笔记高级篇 写在前面 1. mysql的架构介绍 mysql简介 mysqlLinux版的安装 mysql配置文件 mysql逻辑架构介绍 mysql存储引擎 2. 索引优化 ...
- Cron Expressions——Cron 表达式(QuartZ调度时间配置)
如果你需要像日历那样按日程来触发任务,而不是像SimpleTrigger 那样每隔特定的间隔时间触发,CronTriggers通常比SimpleTrigger更有用. 使用CronTrigger,你可 ...
- MySQL数据库(一)-- 数据库介绍、MySQL安装、基础SQL语句
一.数据库介绍 1.什么是数据库 数据库即存储数据的仓库 2.为什么要用数据库 (1)用文件存储是和硬盘打交道,是IO操作,所以有效率问题 (2)管理不方便 (3)一个程序不太可能仅运行在同一台电脑上 ...
- PHP的SOLID设计原则
SOLID Design Principles, 这是一个比设计模式更高级别的概念, 以构建良好代码为目标,真正掌握了就是大师级别了. 我~~~仅知晓~ /*SOLID Design Principl ...
- 项目1:ATM+购物商城项目
项目1:ATM+购物商城 1.项目介绍 项目需求: # 项目需求如下:'''- 额度 15000或自定义- 实现购物商城,买东西加入购物车,调用信用卡接口结账- 可以提现,手续费5%- 支持多账 ...
- tomcat相关知识点
Tomcat 服务器是一个免费的开放源代码的Web 应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用. tomcat的文件结构: bin:用于存放启动和关闭tom ...
- Java 字符流读写文件
据说,java读写文件要写很多,贼麻烦,不像c艹,几行代码就搞定.只能抄抄模板拿来用了. 输入输出流分字节流和字符流.先看看字符流的操作,字节转化为字符也可读写. 一.写入文件 1.FileWrite ...
- python基础之六:编码简介以及python3中的编码
1.常见的四种编码方式的编码过程: ascii A : 00000010 8位 一个字节 unicode A : 00000000 00000001 00000010 00000100 32位 四个字 ...
- html--前端css样式初识
一.CSS概述 css是英文Cascading Style Sheets的缩写,称为层叠样式表,用于对页面进行美化,CSS的可以使页面更加的美观.基本上所有的html页面都或多或少的使用css. CS ...