HDFS中的fsck命令(检查数据块是否健康)
在HDFS中,提供了fsck命令,用于检查HDFS上文件和目录的健康状态、获取文件的block信息和位置信息等。
我们在master机器上执行hdfs fsck就可以看到这个命令的用法。
[hadoop-twq@master ~]$ hdfs fsck
Usage: hdfs fsck <path> [-list-corruptfileblocks | [-move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]]] [-includeSnapshots] [-storagepolicies] [-blockId <blk_Id>]
<path> start checking from this path
-move move corrupted files to /lost+found
-delete delete corrupted files
-files print out files being checked
-openforwrite print out files opened for write
-includeSnapshots include snapshot data if the given path indicates a snapshottable directory or there are snapshottable directories under it
-list-corruptfileblocks print out list of missing blocks and files they belong to
-blocks print out block report
-locations print out locations for every block
-racks print out network topology for data-node locations
-storagepolicies print out storage policy summary for the blocks
-blockId print out which file this blockId belongs to, locations (nodes, racks) of this block, and other diagnostics info (under replicated, corrupted or not, etc)
查看文件目录的健康信息
执行如下的命令:
hdfs fsck /user/hadoop-twq/cmd可以查看/user/hadoop-twq/cmd目录的健康信息:
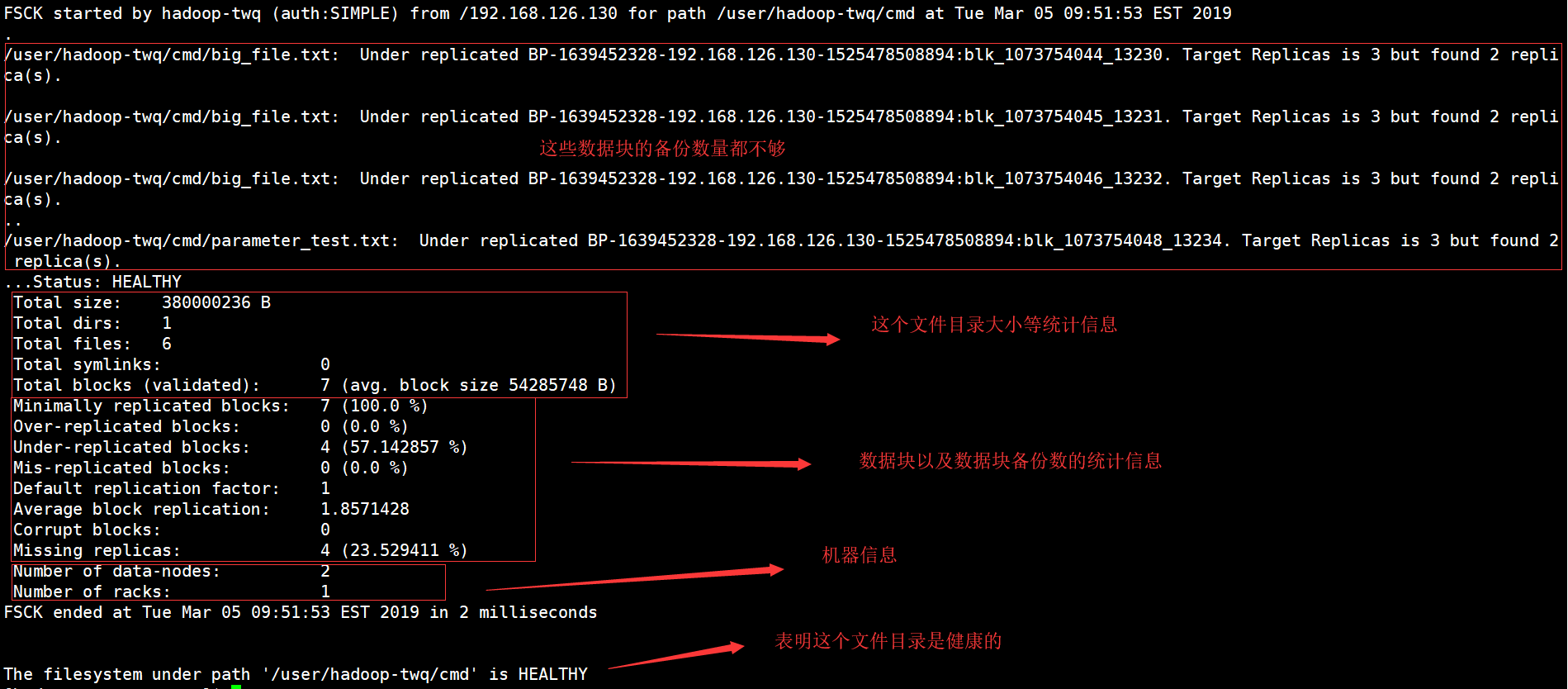
其中有一个比较重要的信息,就是Corrupt blocks,表示损坏的数据块的数量
查看文件中损坏的块 (-list-corruptfileblocks)
[hadoop-twq@master ~]$ hdfs fsck /user/hadoop-twq/cmd -list-corruptfileblocks
Connecting to namenode via http://master:50070/fsck?ugi=hadoop-twq&listcorruptfileblocks=1&path=%2Fuser%2Fhadoop-twq%2Fcmd
The filesystem under path '/user/hadoop-twq/cmd' has 0 CORRUPT files
上面的命令可以找到某个目录下面的损坏的数据块,但是上面表示没有看到坏的数据块
损坏文件的处理
将损坏的文件移动至/lost+found目录 (-move)
hdfs fsck /user/hadoop-twq/cmd -move
删除有损坏数据块的文件 (-delete)
hdfs fsck /user/hadoop-twq/cmd -delete
检查并列出所有文件状态(-files)
执行如下的命令:
hdfs fsck /user/hadoop-twq/cmd -files
显示结果如下:
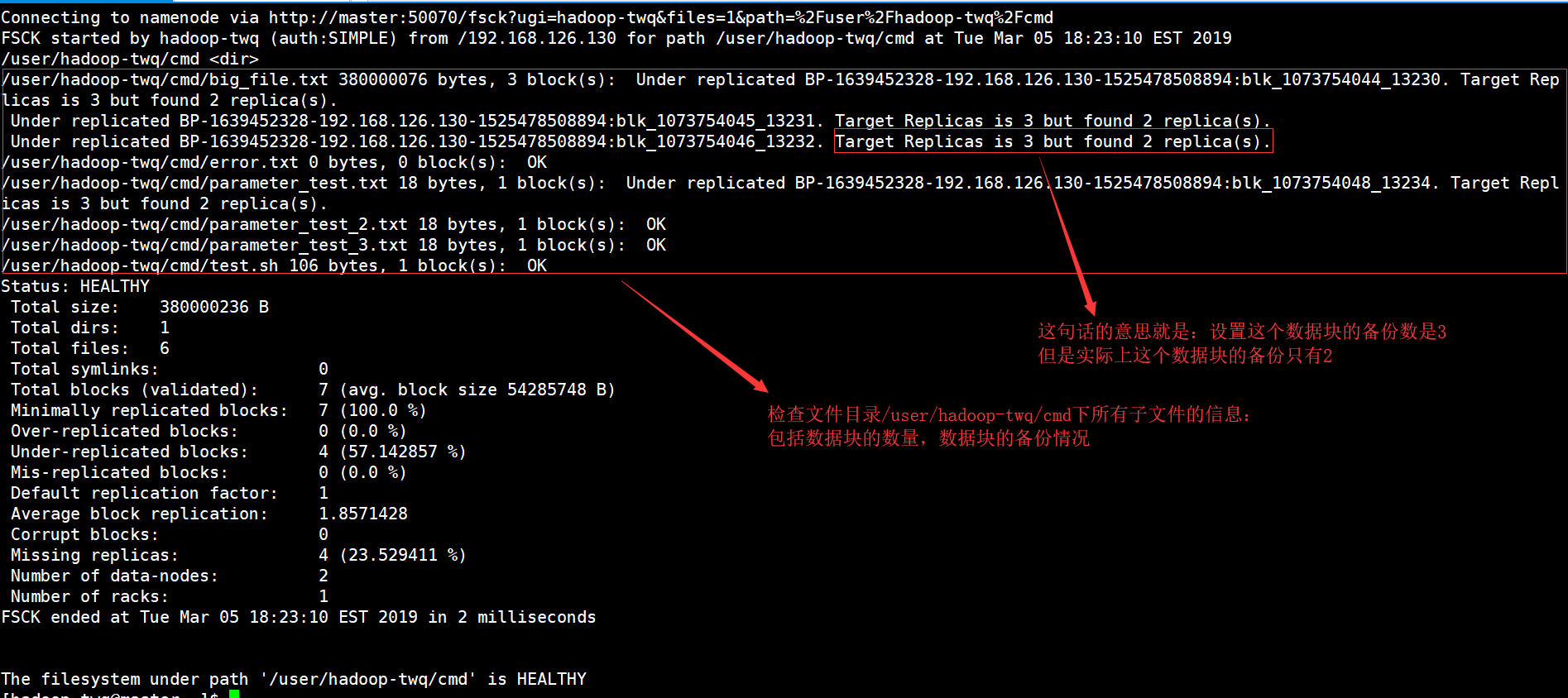
上面的命令可以检查指定路径下的所有文件的信息,包括:数据块的数量以及数据块的备份情况
检查并打印正在被打开执行写操作的文件(-openforwrite)
执行下面的命令可以检查指定路径下面的哪些文件正在执行写操作:
hdfs fsck /user/hadoop-twq/cmd -openforwrite
打印文件的Block报告(-blocks)
执行下面的命令,可以查看一个指定文件的所有的Block详细信息,需要和-files一起使用:
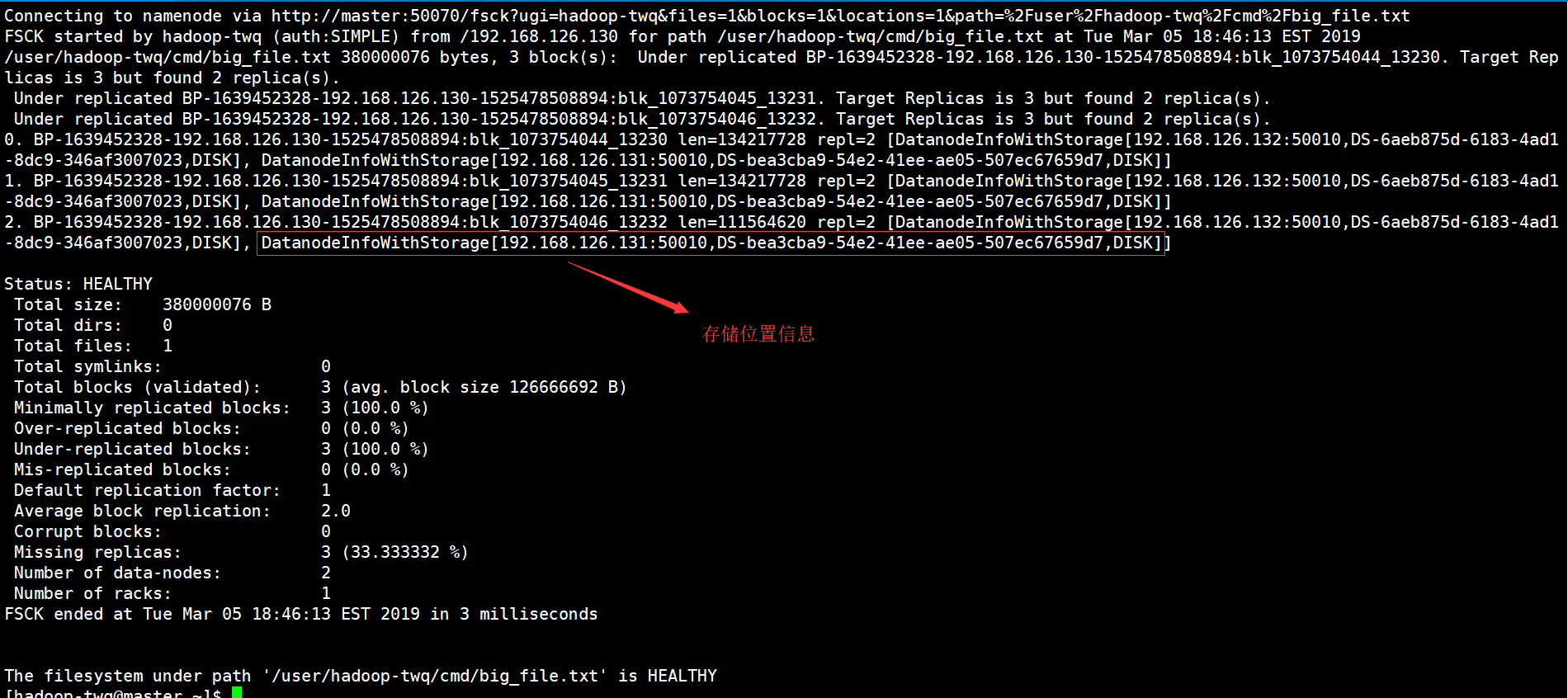
hdfs fsck /user/hadoop-twq/cmd/big_file.txt -files -blocks
结果如下:

如果,我们在上面的命令再加上-locations的话,就是表示还需要打印每一个数据块的位置信息,如下命令:
hdfs fsck /user/hadoop-twq/cmd/big_file.txt -files -blocks -locations
结果如下:
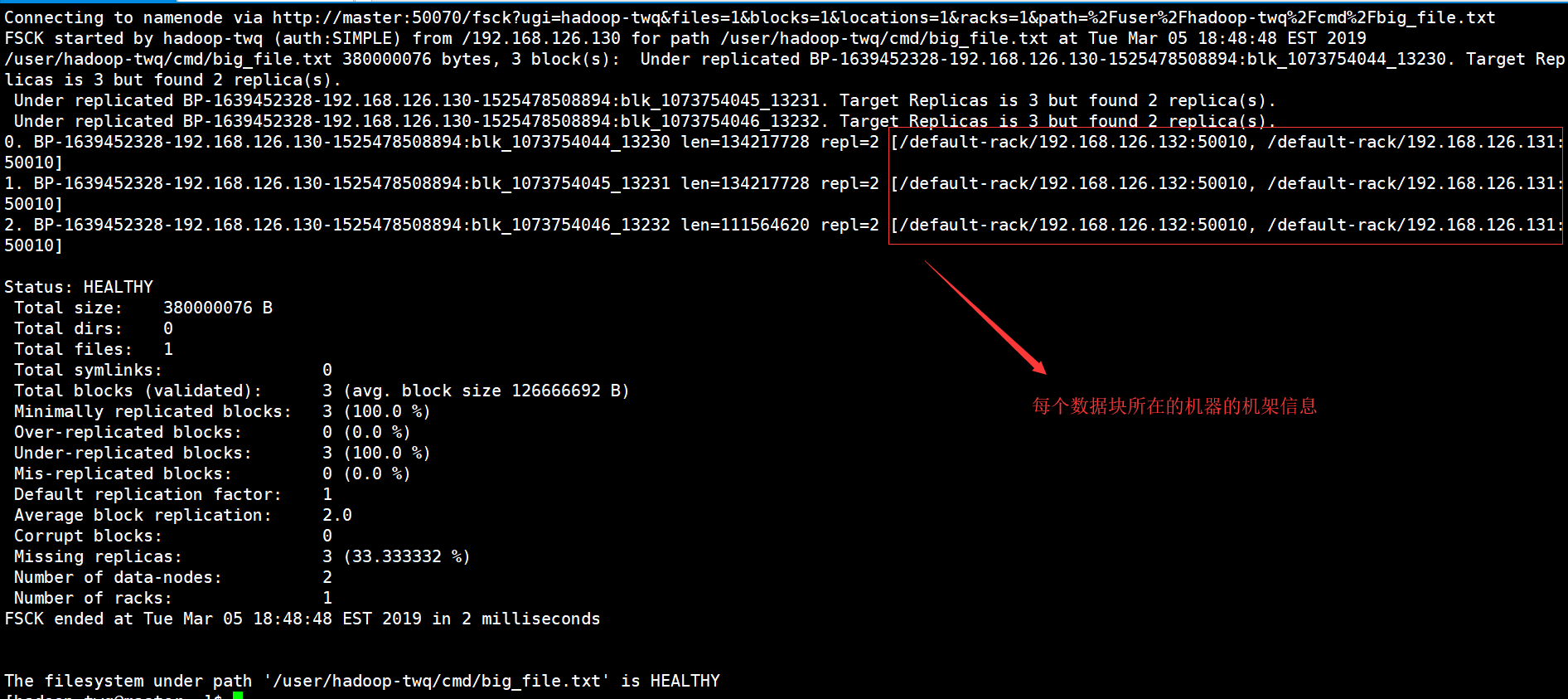
如果,我们在上面的命令再加上-racks的话,就是表示还需要打印每一个数据块的位置所在的机架信息,如下命令:
hdfs fsck /user/hadoop-twq/cmd/big_file.txt -files -blocks -locations -racks
结果如下:
hdfs fsck的使用场景
场景一
当我们执行如下的命令:
hdfs fsck /user/hadoop-twq/cmd
可以查看/user/hadoop-twq/cmd目录的健康信息:
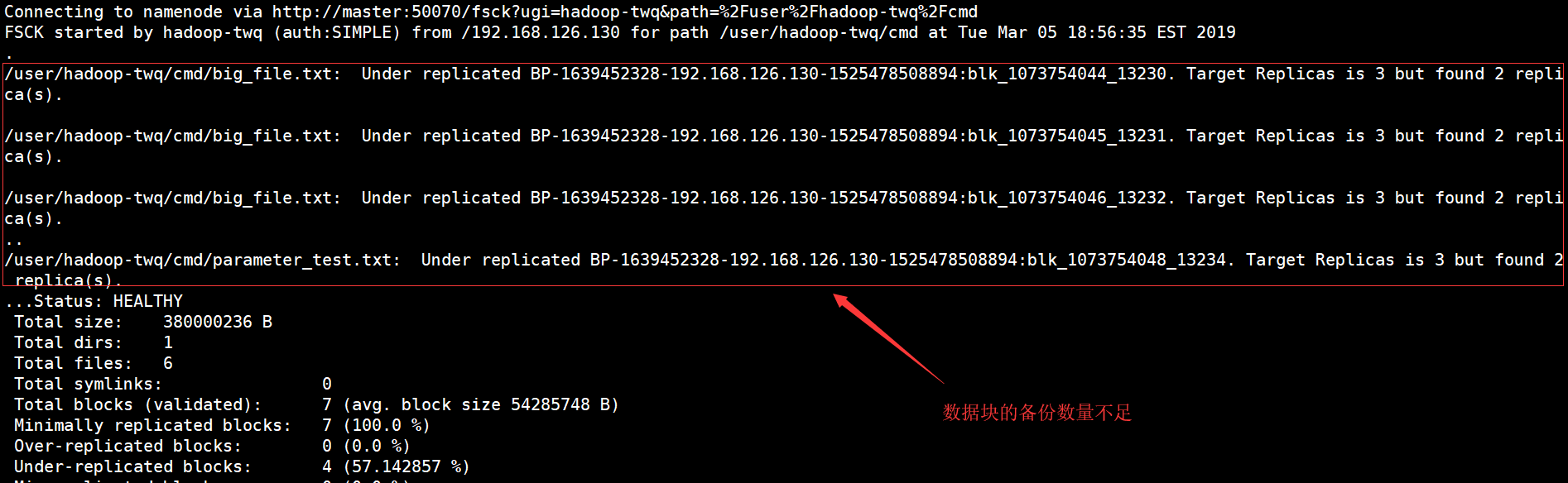
我们可以看出,有两个文件的数据块的备份数量不足,这个我们可以通过如下的命令,重新设置两个文件数据块的备份数:
## 将文件big_file.txt对应的数据块备份数设置为1
hadoop fs -setrep -w 1 /user/hadoop-twq/cmd/big_file.txt
## 将文件parameter_test.txt对应的数据块备份数设置为1
hadoop fs -setrep -w 1 /user/hadoop-twq/cmd/parameter_test.txt
上面命令中 -w 参数表示等待备份数到达指定的备份数,加上这个参数后再执行的话,则需要比较长的时间
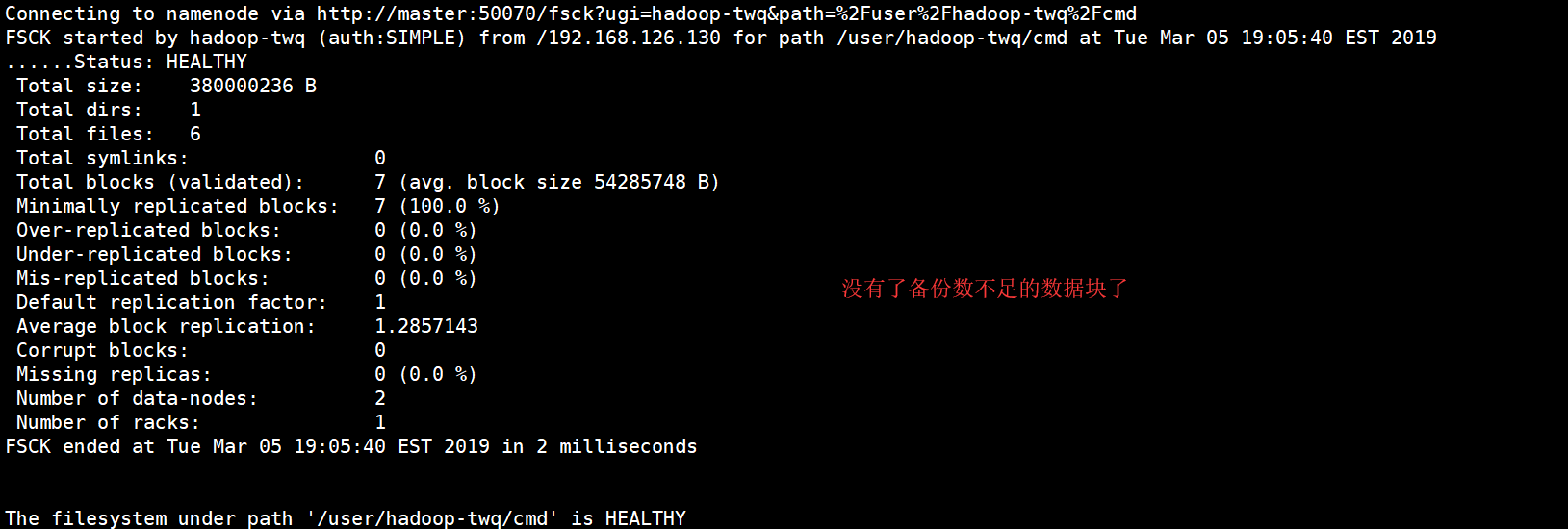
执行完上面的命令后,我们再来执行下面的命令:
hdfs fsck /user/hadoop-twq/cmd
结果如下:
场景二
当我们访问HDFS的WEB UI的时候,出现了如下的警告信息:
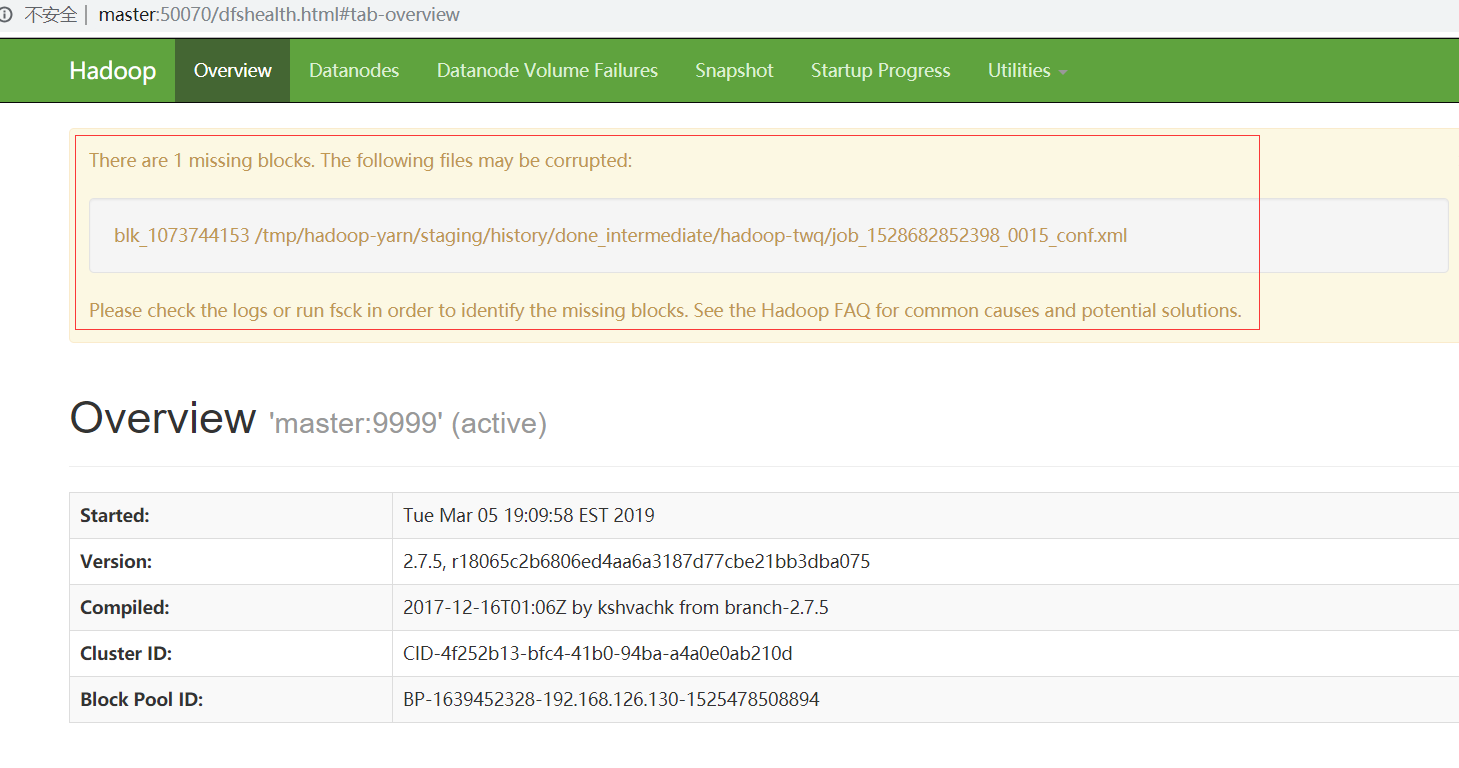
表明有一个数据块丢失了,这个时候我们执行下面的命令来确定是哪一个文件的数据块丢失了:
[hadoop-twq@master ~]$ hdfs fsck / -list-corruptfileblocks
Connecting to namenode via http://master:50070/fsck?ugi=hadoop-twq&listcorruptfileblocks=1&path=%2F
The list of corrupt files under path '/' are:
blk_1073744153 /tmp/hadoop-yarn/staging/history/done_intermediate/hadoop-twq/job_1528682852398_0015_conf.xml
The filesystem under path '/' has 1 CORRUPT files
发现是数据块blk_1073744153丢失了,这个数据块是淑文文件/tmp/hadoop-yarn/staging/history/done_intermediate/hadoop-twq/job_1528682852398_0015_conf.xml的。
如果出现这种场景是因为在DataNode中没有这个数据块,但是在NameNode的元数据中有这个数据块的信息,我们可以执行下面的命令,把这些没用的数据块信息删除掉,如下:
[hadoop-twq@master ~]$ hdfs fsck /tmp/hadoop-yarn/staging/history/done_intermediate/hadoop-twq/ -delete
Connecting to namenode via http://master:50070/fsck?ugi=hadoop-twq&delete=1&path=%2Ftmp%2Fhadoop-yarn%2Fstaging%2Fhistory%2Fdone_intermediate%2Fhadoop-twq
FSCK started by hadoop-twq (auth:SIMPLE) from /192.168.126.130 for path /tmp/hadoop-yarn/staging/history/done_intermediate/hadoop-twq at Tue Mar 05 19:18:00 EST 2019
....................................................................................................
..
/tmp/hadoop-yarn/staging/history/done_intermediate/hadoop-twq/job_1528682852398_0015_conf.xml: CORRUPT blockpool BP-1639452328-192.168.126.130-1525478508894 block blk_1073744153 /tmp/hadoop-yarn/staging/history/done_intermediate/hadoop-twq/job_1528682852398_0015_conf.xml: MISSING 1 blocks of total size 220262 B...................................................................................................
....................................................................................................
........................Status: CORRUPT
Total size: 28418833 B
Total dirs: 1
Total files: 324
Total symlinks: 0
Total blocks (validated): 324 (avg. block size 87712 B)
********************************
UNDER MIN REPL'D BLOCKS: 1 (0.30864197 %)
dfs.namenode.replication.min: 1
CORRUPT FILES: 1
MISSING BLOCKS: 1
MISSING SIZE: 220262 B
CORRUPT BLOCKS: 1
********************************
Minimally replicated blocks: 323 (99.69136 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 1
Average block replication: 0.99691355
Corrupt blocks: 1
Missing replicas: 0 (0.0 %)
Number of data-nodes: 2
Number of racks: 1
FSCK ended at Tue Mar 05 19:18:01 EST 2019 in 215 milliseconds
然后执行:
[hadoop-twq@master ~]$ hdfs fsck / -list-corruptfileblocks
Connecting to namenode via http://master:50070/fsck?ugi=hadoop-twq&listcorruptfileblocks=1&path=%2F
The filesystem under path '/' has 0 CORRUPT files
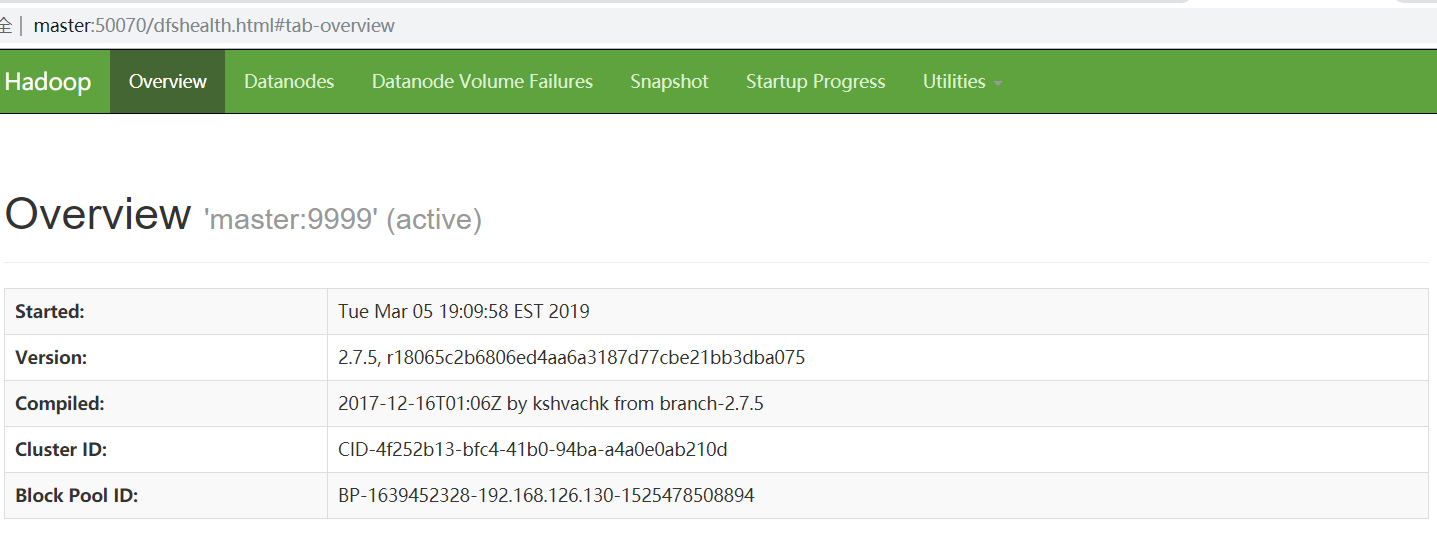
丢失的数据块没有的,被删除了。我们也可以刷新WEB UI,也没有了警告信息:
HDFS中的fsck命令(检查数据块是否健康)的更多相关文章
- 利用describe( )中的count来检查数据是否缺省
#-*- coding: utf-8 -*- #在python的pandas库中,只需要读入数据,然后使用describe()函数就可以查看数据的基本情况 import pandas as pd in ...
- HDFS源码分析之数据块Block、副本Replica
我们知道,HDFS中的文件是由数据块Block组成的,并且为了提高容错性,每个数据块Block都会在不同数据节点DataNode上有若干副本Replica.那么,什么是Block?什么又是Replic ...
- HDFS中的数据块(Block)
我们在分布式存储原理总结中了解了分布式存储的三大特点: 数据分块,分布式的存储在多台机器上 数据块冗余存储在多台机器以提高数据块的高可用性 遵从主/从(master/slave)结构的分布式存储集群 ...
- HDFS源码分析心跳汇报之数据块增量汇报
在<HDFS源码分析心跳汇报之BPServiceActor工作线程运行流程>一文中,我们详细了解了数据节点DataNode周期性发送心跳给名字节点NameNode的BPServiceAct ...
- HDFS源码分析数据块汇报之损坏数据块检测checkReplicaCorrupt()
无论是第一次,还是之后的每次数据块汇报,名字名字节点都会对汇报上来的数据块进行检测,看看其是否为损坏的数据块.那么,损坏数据块是如何被检测的呢?本文,我们将研究下损坏数据块检测的checkReplic ...
- HDFS源码分析数据块之CorruptReplicasMap
CorruptReplicasMap用于存储文件系统中所有损坏数据块的信息.仅当它的所有副本损坏时一个数据块才被认定为损坏.当汇报数据块的副本时,我们隐藏所有损坏副本.一旦一个数据块被发现完好副本达到 ...
- Oracle 数据块损坏与恢复具体解释
1.什么是块损坏: 所谓损坏的数据块,是指块没有採用可识别的 Oracle 格式,或者其内容在内部不一致. 通常情况下,损坏是由硬件故障或操作系统问题引起的.Oracle 数据库将损坏的块标识为&qu ...
- [转]Oracle数据块体系的详细介绍
数据块概述Oracle对数据库数据文件(datafile)中的存储空间进行管理的单位是数据块(data block).数据块是数据库中最小的(逻辑)数据单位.与数据块对应的,所有数据在操作系统级的最小 ...
- Oracle数据块深入分析总结
http: 最近在研究块的内部结构,把文档简单整理了一下,和大家分享一下.该篇文章借助dump和BBED对数据 库内部结构进行了分析,最后附加了一个用BBED解决ORA-1200错误的小例子.在总结的 ...
随机推荐
- 【LeetCode】四数之和【排序,固定k1,k2,二分寻找k3和k4】
给定一个包含 n 个整数的数组 nums 和一个目标值 target,判断 nums 中是否存在四个元素 a,b,c 和 d ,使得 a + b + c + d 的值与 target 相等?找出所有满 ...
- kube-proxy运行机制分析【转载】
转自:http://blog.itpub.net/28624388/viewspace-2155433/ 1.Service在很多情况下只是一个概念,而真正将Service的作用实现的是kube-pr ...
- js 获取服务端时间,并实现时钟
本例子以vue语法伪代码书写: 1,获取服务端北京时间 getRealTime() { let that = this; var xhr = new XMLHttpRequest(); if( !xh ...
- [转帖]B树索引、位图索引和散列索引
B树索引.位图索引和散列索引 https://blog.csdn.net/huashanlunjian/article/details/84460436 索引在数据结构上可以分为三种B树索引.位图 ...
- 对于并发任务,应该使用 Task 替代 BackgroundWorker
背景 EF + Oracle,并发存储监控记录,使用 BackgroundWorker 时产生错误如下: public void MonitorLogging(DateTime DateStart, ...
- REST-framework之频率组件
REST-framework之频率控制 一 频率简介 为了控制用户对某个url请求的频率,比如,一分钟以内,只能访问三次 二 自定义频率类,自定义频率规则 自定义的逻辑 ""&qu ...
- Spark 系列(六)—— 累加器与广播变量
一.简介 在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: ...
- 关于base64的一个小细节
Base64出现\r\n的问题 前段时间遇到这么一个小问题: 后台接口返回一个图片的base64串,同事拿着这个字符串,找了一个在线图片和Base64字符串互转的工具网站,想将字符串转成图片,死活转不 ...
- ITIL《信息技术基础架构库》
一 概述 1. ITIL 自上世纪70年代开始,个人计算机以及计算机网络开始在欧美发达国家普及.随着时间的推移,信息系统的规模越来越大,人们对信息系统的依赖也越来越强.特别是到了80年代,互联网开始普 ...
- TFTP(Trivial File Transfer Protocol,简单文件传输协议)
TFTP(Trivial File Transfer Protocol,简单文件传输协议),是 TCP/IP 协议族中用来在客户机和服务器之间进行简单文件传输的协议,开销很小.这时候有人可能会纳闷,既 ...