MapReduce Join的使用
一、Map端Join
可连接两个都非常大的数据集之间可使用map端连接,数据在到达map端之前就执行连接操作。
需满足:
两个要连接的数据集都先划分成相同数量的分区,相同的key要保证在同一分区中(每个分区中两个数据集数据量不一定要要相同), 并且要 按连接key排序;
利用CompositeInputFormat类,可实现map端连接:
代码参考:GitHub上Join示例
其它参考:hadoop实现join (CompositeInputFormat)
二、Reduce端连接
Reduce端连接更简单易用,以天气连接为例:
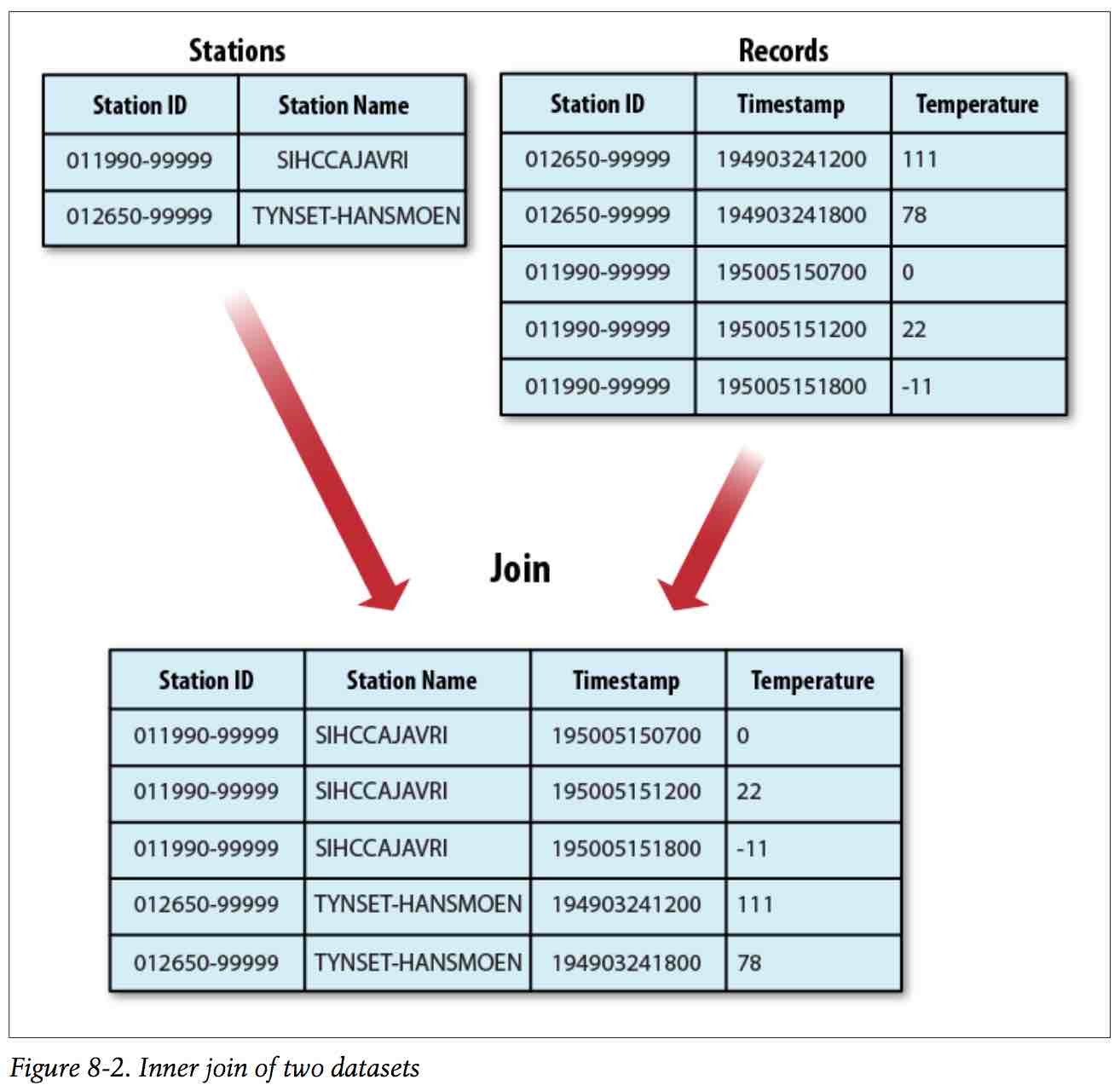
使用步骤:
1、使用MutipleInputs类设定不同输入数据集的InputFormat,以及Mapper;
2、辅助排序:通过自定义一个WritableComparable类型的 T,添加一个辅助排序字段,重写compareTo()方法,
作为传入Reducer的key,可完成可控的二次排序;
3、自定义Partitioner类,保证以自定义WritableComparable类型的T以首字段进行分区;自定一个分组Comparator类;
job.setPartitionerClass(KeyPartitioner.class);
job.setGroupingComparatorClass(TextPair.FirstComparator.class);
自定义Partitioner类、Comparator:
public static class KeyPartitioner extends Partitioner<TextPair, Text> {
@Override
public int getPartition(TextPair key, Text value, int numPartitions) {
return (key.getFirst().hashCode() & Integer.MAX_VALUE) % numPartitions;
}
}
public static class FirstComparator extends WritableComparator {
private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
public FirstComparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
return TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
if (a instanceof TextPair && b instanceof TextPair) {
return ((TextPair) a).first.compareTo(((TextPair) b).first);
}
return super.compare(a, b);
}
}
3、在Reducer中把选到达的key提取出来,即可自定义完成Join操作;
三、使用分布式缓存来实现:
其它参考:MapReduce 中的两表 join 几种方案简介
MapReduce Join的使用的更多相关文章
- mapreduce join
MapReduce Join 对两份数据data1和data2进行关键词连接是一个很通用的问题,如果数据量比较小,可以在内存中完成连接. 如果数据量比较大,在内存进行连接操会发生OOM.mapredu ...
- SQL join中级篇--hive中 mapreduce join方法分析
1. 概述. 本文主要介绍了mapreduce框架上如何实现两表JOIN. 2. 常见的join方法介绍 假设要进行join的数据分别来自File1和File2. 2.1 reduce side jo ...
- MapReduce Join关联
Reduce join 原理 Map端的主要工作:为来自不同表(文件)的key/value对打标签以区别不同来源的记录.然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出. R ...
- mapreduce join操作
上次和朋友讨论到mapreduce,join应该发生在map端,理由太想当然到sql里面的执行过程了 wheremap端 join在map之前(笛卡尔积),但实际上网上看了,mapreduce的笛卡尔 ...
- Hadoop.2.x_高级应用_二次排序及MapReduce端join
一.对于二次排序案例部分理解 1. 分析需求(首先对第一个字段排序,然后在对第二个字段排序) 杂乱的原始数据 排序完成的数据 a,1 a,1 b,1 a,2 a,2 [排序] a,100 b,6 == ...
- MapReduce实现的Join
MapReduce Join 对两份数据data1和data2进行关键词连接是一个很通用的问题,如果数据量比较小,可以在内存中完成连接. 如果数据量比较大,在内存进行连接操会发生OOM.mapredu ...
- MapReduce中的Join算法
在关系型数据库中Join是非常常见的操作,各种优化手段已经到了极致.在海量数据的环境下,不可避免的也会碰到这种类型的需求,例如在数据分析时需要从不同的数据源中获取数据.不同于传统的单机模式,在分布式存 ...
- 大数据mapreduce俩表join之python实现
二次排序 在Hadoop中,默认情况下是按照key进行排序,如果要按照value进行排序怎么办?即:对于同一个key,reduce函数接收到的value list是按照value排序的.这种应用需求在 ...
- Hadoop学习之路(二十一)MapReduce实现Reduce Join(多个文件联合查询)
MapReduce Join 对两份数据data1和data2进行关键词连接是一个很通用的问题,如果数据量比较小,可以在内存中完成连接. 如果数据量比较大,在内存进行连接操会发生OOM.mapredu ...
随机推荐
- Office 中的各种小tips(更新中)
1.Word 中打字输入会擦掉之后原有字符,出现“吃字”的情况? 要将“改写”切换为“插入”,最简单的方法就是点击键盘上小键盘旁边的“insert”键. 其实仔细观察的话,在word文档下方,会看到如 ...
- cf299C Weird Game
Weird Game Yaroslav, Andrey and Roman can play cubes for hours and hours. But the game is for three, ...
- ElasticSearch中Date
ElasticSearch中有时会想要通过索引日期来筛选查询的数据,此时就需要用到日期数学表达式. 比如现在的时间是2024年3月22日中午12点.utc 注意,如果是中国的时间需要加上8个小时! 表 ...
- AOP面向方面(切面)编程
1.引言 软件开发的目标是要对世界的部分元素或者信息流建立模型,实现软件系统的工程需要将系统分解成可以创建和管理的模块.于是出现了以系统模块化特性的面向对象程序设计技术.模块化的面向对象编程极度极地提 ...
- 数据库数据导出CSV文件,浏览器下载
直接上代码: def download(request): # 从数据库查询数据 data_list = Info.objects.all() # 定义返回对象 response = HttpResp ...
- Wannafly挑战赛11 D 题 字符串hash + 卡常
题目链接 https://ac.nowcoder.com/acm/contest/73#question map与order_map https://blog.csdn.net/BillCYJ/art ...
- R 包安装、载入和卸载
生物上的一些包可以这样安装 source("https://bioconductor.org/biocLite.R") biocLite("affy") 一般的 ...
- Chrome常用URL命令(伪URL)
在Chrome地址栏输入chrome://chrome-urls/可以看到所有的Chrome支持的伪RUL 1.chrome://accessibility/ 可达性分析,默认是关闭的,点击acces ...
- pinpoint 应用性能管理工具安装部署
原文:http://www.cnblogs.com/yyhh/p/6106472.html pinpoint 安装部署 阅读目录 1. 环境配置 1.1 获取需要的依赖包 1.2 配置jdk1.7 ...
- 修复OS X的Finder中文档 打开方式中重复程序的问题
如上图,OS X在使用一段时间后,有些软件就会重复注册打开方式,对于有洁癖的人,这是难以接受的事. 不过有个命令可以很简单的把重复项给去掉. /System/Library/Frameworks/Co ...