python网络爬虫。第一次测试-有道翻译
2018-03-0720:53:56
成功的效果如下

代码备份
# -*- coding: UTF-8 -*-
from urllib import request
from urllib import parse
import json if __name__ == "__main__":
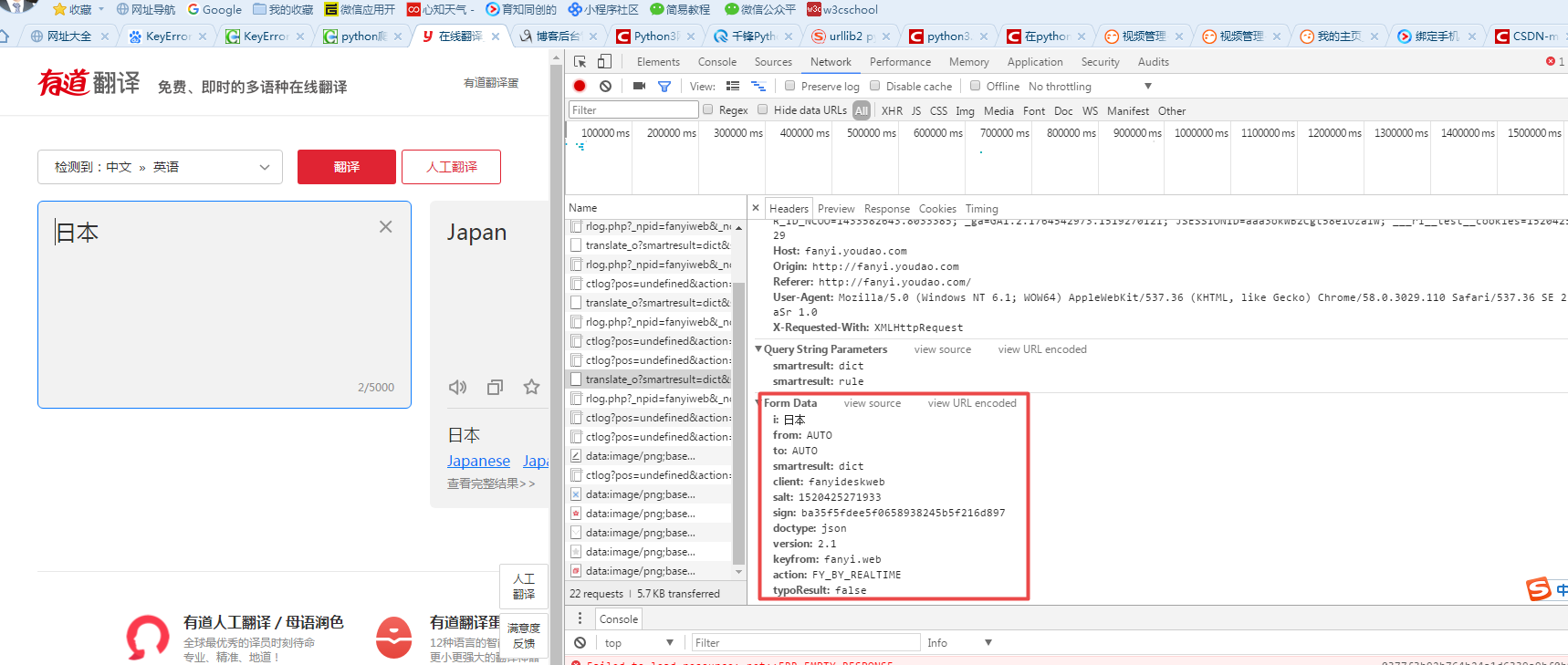
#对应上图的Request URL
Request_URL = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc'
#创建Form_Data字典,存储上图的Form Data
Form_Data = {}
Form_Data['i'] = 'hello'
Form_Data['from'] = 'AUTO'
Form_Data['to'] = 'AUTO'
Form_Data['smartresult'] = 'dict'
Form_Data['client'] = 'fanyideskweb'
Form_Data['salt'] = ''
Form_Data['sign'] = 'ba35f5fdee5f0658938245b5f216d897'
Form_Data['doctype'] = "json"
Form_Data['version'] = '2.1'
Form_Data['keyfrom'] = 'fanyi.web'
Form_Data['action'] = 'FY_BY_REALTIME'
Form_Data['typoResult'] = 'false'
#使用urlencode方法转换标准格式
data = parse.urlencode(Form_Data).encode('utf-8')
#传递Request对象和转换完格式的数据
response = request.urlopen(Request_URL,data)
print(response.getcode())
#读取信息并解码
html = response.read().decode('utf-8')
#使用JSON
translate_results = json.loads(html)
#找到翻译结果
translate_results = translate_results["translateResult"][0][0]['tgt']
#打印翻译信息
print(html)
print("翻译的结果是:%s" % translate_results)
效果还是可以的,毕竟这是自己的第一次调试。
代码更新
加入json数据解析的方法
# -*- coding: UTF-8 -*-
from urllib import request
from urllib import parse
import json if __name__ == "__main__":
#对应上图的Request URL
Request_URL = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc'
#创建Form_Data字典,存储上图的Form Data
Form_Data = {}
Form_Data['i'] = '我曾经有一个梦想'
Form_Data['from'] = 'AUTO'
Form_Data['to'] = 'AUTO'
Form_Data['smartresult'] = 'dict'
Form_Data['client'] = 'fanyideskweb'
Form_Data['salt'] = ''
Form_Data['sign'] = 'ba35f5fdee5f0658938245b5f216d897'
Form_Data['doctype'] = "json"
Form_Data['version'] = '2.1'
Form_Data['keyfrom'] = 'fanyi.web'
Form_Data['action'] = 'FY_BY_REALTIME'
Form_Data['typoResult'] = 'false'
#使用urlencode方法转换标准格式
data = parse.urlencode(Form_Data).encode('utf-8')
#传递Request对象和转换完格式的数据
response = request.urlopen(Request_URL,data)
#读取信息并解码
html = response.read().decode('utf-8')
#使用JSON
translate_results = json.loads(html)
print("输出json数据为: %s" % translate_results)
# 找到可用的key
print("可用的key为:%s" %translate_results.keys())
#找到翻译结果
test = translate_results["type"]
your_input = translate_results["translateResult"][0][0]['src']
translate_results = translate_results["translateResult"][0][0]['tgt'] #打印翻译信息 print("测试输出 %s" %test)
print("待翻译的内容为:%s" % your_input)
print("翻译的结果是:%s" % translate_results)
输出结果为
C:\Users\Administrator\PycharmProjects\python_test1\venv\Scripts\python.exe C:/Users/Administrator/PycharmProjects/python_test1/123.py
输出json数据为: {'type': 'ZH_CN2EN', 'errorCode': 0, 'elapsedTime': 1, 'translateResult': [[{'src': '我曾经有一个梦想', 'tgt': 'I had a dream'}]]}
可用的key为:dict_keys(['type', 'errorCode', 'elapsedTime', 'translateResult'])
测试输出 ZH_CN2EN
待翻译的内容为:我曾经有一个梦想
翻译的结果是:I had a dream Process finished with exit code 0
python网络爬虫。第一次测试-有道翻译的更多相关文章
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
- Python 正则表达式 (python网络爬虫)
昨天 2018 年 01 月 31 日,农历腊月十五日.20:00 左右,152 年一遇的月全食.血月.蓝月将今晚呈现空中,虽然没有看到蓝月亮,血月.月全食也是勉强可以了,还是可以想像一下一瓶蓝月亮洗 ...
- Python网络爬虫学习总结
1.检查robots.txt 让爬虫了解爬取该网站时存在哪些限制. 最小化爬虫被封禁的可能,而且还能发现和网站结构相关的线索. 2.检查网站地图(robots.txt文件中发现的Sitemap文件) ...
- Python 网络爬虫 001 (科普) 网络爬虫简介
Python 网络爬虫 001 (科普) 网络爬虫简介 1. 网络爬虫是干什么的 我举几个生活中的例子: 例子一: 我平时会将 学到的知识 和 积累的经验 写成博客发送到CSDN博客网站上,那么对于我 ...
- 学习推荐《精通Python网络爬虫:核心技术、框架与项目实战》中文PDF+源代码
随着大数据时代的到来,我们经常需要在海量数据的互联网环境中搜集一些特定的数据并对其进行分析,我们可以使用网络爬虫对这些特定的数据进行爬取,并对一些无关的数据进行过滤,将目标数据筛选出来.对特定的数据进 ...
- Python网络爬虫实战(一)快速入门
本系列从零开始阐述如何编写Python网络爬虫,以及网络爬虫中容易遇到的问题,比如具有反爬,加密的网站,还有爬虫拿不到数据,以及登录验证等问题,会伴随大量网站的爬虫实战来进行. 我们编写网络爬虫最主要 ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
随机推荐
- SSD硬盘安装系统后要做的事
1***cmd>fsutil behavior query DisableDeleteNotify 0如果返回值是0,则代表TRIM处于开启状态:反之如果返回值是1,则代表TRIM处于关闭状态2 ...
- 【剑指Offer学习】【面试题65:滑动窗体的最大值】
题目:给定一个数组和滑动窗体的大小,请找出全部滑动窗体里的最大值. 举例说明 比如,假设输入数组{2,3,4,2,6,2,5,1}及滑动窗体的大小.那么一共存在6个滑动窗体,它们的最大值分别为{4,4 ...
- String类的四个默认成员函数
优化版的拷贝构造函数,先创建一个暂时实例tmp,接着把tmp._ptr和this->_ptr交换,因为tmp是一个局部变量.程序执行到该函数作用域外,就会自己主动调用析构函数.释放tmp._pt ...
- 常用Lunix命令
计算机 1.硬件系统 输入单元.输出单元.算术逻辑单元.控制单元.记忆单元 中央处理单元:CPU(算术逻辑单元.控制单元) 电源.主板.CPU.内存(RAM).硬盘.(声卡.显卡.网卡)(集成在主板上 ...
- web metrics dashboard 数据分析工具 看板 从可视化发现问题 避免sql重复写 调高效率
<?php$todo = array();$done = array();$h = array();$v = $all['v'];$l = count($v);#19700101 08for ( ...
- JMeter快捷键图标制作 去掉cmd命令窗口
使用jmeter时: 如果使用默认的jmeter.bat启动的话,会出现一个CMD命令窗口之后再会启动jmeter工作界面 直接启用ApacheJMeter.jar文件即可跳过CMD命令窗口启动jme ...
- Notification操作大全
目录 一:普通的Notification Notification 的基本操作 给 Notification 设置 Action 更新 Notification 取消 Notification 设置 ...
- hdu 5782(kmp+hash)
Cycle Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Submi ...
- 【HDU 2157】 How Many Ways??
[题目链接] 点击打开链接 [算法] 设A[i][j]为走一条边,从i走到j的方案数 C[i][j]为走两条边,从i走到j的方案数,显然有 : C = A * A = A^2 C'[i][j]为走三条 ...
- [bzoj3073]Journeys
https://www.zybuluo.com/ysner/note/1295471 题面 \(Seter\)建造了一个很大的星球,他准备建造\(N\)个国家和无数双向道路.\(N\)个国家很快建造好 ...