使用Navicat客户端运行SQL语句出现中文乱码
出现乱码无非就是编码方式不统一造成的,通过查阅资料解决了问题。
(简 体中文系统环境支持国标 GB2312、GB18030 和 Unicode (UTF-8) 编码。它们在系统中设置的locale(亦指语言别)名称为:
国标 GB2312: zh_CN.hp15CN
国标 GB18030: zh_CN.gb18030
Unicode (UTF-8): zh_CN.utf8
)
只要涉及到文字的地方,就会存在字符集和编码方式。对于MySQL数据库系统而言,用户从MySQL client端敲入一条sql语句,通过TCP/IP传递给
MySQL server进程,到最终存入server端的文件,每个环节都涉及到字符存储。涉及到字符存储的地方,就涉及到字符集编码。
我们就用 show variables like'char%';和 showvariables like 'collation_%';来查看一下:
分别在MYSQL、Navicat中运行命令;
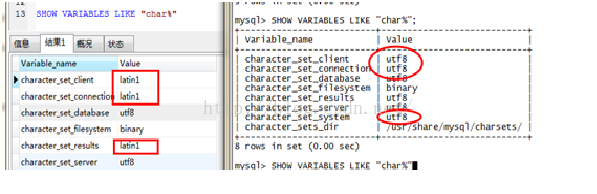
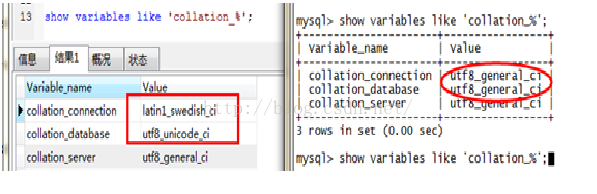
两边有些字符集和校对的系统变量是不同的。
两种方法:
①我们以MySQL配置为准。在Navicat 中运行以下命令:
setcharacter_set_client= utf8;
setcharacter_set_connection =utf8 ;
setcharacter_set_results=utf8 ;
再查看字符集,两边就一致了。进行测试,乱码问题解决。
②保证MySQL字符集配置正确的前提下,在navicat的连接属性中勾选使用MYSQL字符集。(推荐)
这里插入一篇关于MySQL数据库字符集的文章,总结的很棒。
字符集&字符编码方式
字符集(Character set)是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,这里的字符可以是英文字符,汉字字符,或者其他国家语言字符。
常见字符集包括:ASCII字符集、LATIN1字符集、GB2312字符集、GBK字符集、GB18030字符集、Unicode字符集等。字符编码方式是用一个或多个字节表示字符集中的一个字符。每种字符集都有自己特有的编码方式,因此同一个字符,在不同字符集的编码方式下,会产生不同的二进制。ASCII是基于罗马字母表的一套字符集,它采用1个字节的低7位表示字符,高位始终为0。LATIN1字符集相对于ASCII字符集做了扩展,仍然使用一个字节表示字符,但启用了高位,扩展了字符集的表示范围。GB2312、GBK、GB18030字符集是支持中文的字符集,字符集范围GB2312<GBK< GB18030。GBK字符集的字符有一字节编码和两字节编码方式。对于00-7F的字符与ASCII保持一致,汉字采用2个字节表示。第一字节范围是81-FE,避免与00-7F冲突。Unicode字符集是计算机科学领域里的一项业界标准,支持了所有国家的文字字符。Unicode字符集有好几种编码方式,比如常见的utf-8,utf-16,utf-32等。Utf8采用1-4个字节表示字符,utf-16采用固定的2个字节,utf-32则采用4个字节存储。
MySQL与字符集
只要涉及到文字的地方,就会存在字符集和编码方式。对于MySQL数据库系统而言,用户从MySQL client端敲入一条sql语句,通过TCP/IP传递给MySQL server进程,到最终存入server端的文件,每个环节都涉及到字符存储。涉及到字符存储的地方,就涉及到字符集编码,通过MySQL提供的系统变量就可见一斑。MySQL字符集设置系统变量以及含义如下表:
|
变量名 |
含义 |
|
character_set_server |
默认的内部操作字符集 |
|
character_set_client |
客户端来源数据使用的字符集 |
|
character_set_connection |
连接层字符集 |
|
character_set_results |
查询结果字符集 |
|
character_set_database |
当前选中数据库的默认字符集 |
|
character_set_system |
系统元数据(字段名等)字符集 |
以上这些参数如何起作用
1.库、表、列字符集的由来
(1).建库时,若未明确指定字符集,则采用character_set_server指定的字符集。
(2).建表时,若未明确指定字符集,则采用当前库所采用的字符集。
(3).新增,修改表字段时,若未明确指定字符集,则采用当前表所采用的字符集。
2.更新、查询涉及到得字符集变量
用户在更新(插入,删除,修改),查询数据库时,最常使用的字符集变量主要包含character_set_client,character_set_connection,character_set_result。
更新流程字符集转换过程:character_set_client-》character_set_connection-》表字符集。
查询流程字符集转换过程:表字符集-》character_set_result
PS:个人认为character_set_connection连接字符集设置有点冗余,因为最终都是要转换到表字符集的。
3.character_set_database
这个参数是当前默认数据库的字符集,比如执行use xxx后,当前数据库变为xxx,若xxx的字符集为utf8,那么这个变量值就变为utf8。因此这个参数是供系统设置,无需人工设置。
mysql字符编码转换流程
如果以上各个系统变量的设置不一致,比如character_set_client为UTF8,而character_set_database为GBK,则会出现需要进行编码转换的情况。那么字符集转换的原理是什么?假设GBK字符集的字符串“小明”,需要转为UTF8字符集存储,实际就是对于“小明”字符串中的每个汉字去UTF8编码表里面查询对应的二进制,然后存储,仅此而已,编码转换并不涉及到复杂的算法。mysql字符集转换主要涉及到几个步骤:
1) 将数据从character_set_client设置转换为character_set_connection设置;
2) 将character_set_connection设置转为表字段的字符集设置;
3) 将操作结果从表字段字符集转为character_set_results设置。
下面我通过一个常用的场景来描述字符集转换的流程。用户通过mysql命令行(如果是远程连接:SecureCRT),敲入命令“insert into T values(1,’小明’)”,字符串’小明’在流转过程中二进制存储内容。
a) 用户采用的客户端为utf8字符集,character_set_client=gbk,character_set_connection=gbk, 表T采用gbk字符集。

由于character_set_client、character_set_connection和表字符集均为GBK,不涉及编码转换。因此,表虽然为字符集虽然为GBK,但“小明”的编码并非为GBK编码的二进制流,而是UTF8的二进制流,两个汉字占用了6个字节,而读取则是一个逆向的过程,不涉及到编码转换,查询依然能正确返回“小明”。
b) 在a)的情况下,改变character_set_client的设置为utf8,查询插入的值。

可以看到返回的值是“灏忔槑”, 这是由于表的字符集是GBK,而客户端请求是UTF8,那么server将二进制流E5B08FE6988E对应的GBK汉字“灏忔槑”转为UTF8汉字对应的二进制流E7818FE5BF94E6A791,因此查询结果在SecureCRT就显示为“灏忔槑”,即通常我们所谓的乱码。
c) 在b)的情况下,设置SecureCRT的字符集为GBK,看看SecureCRT字符集设置对结果影响

可以看到返回的是另外一组字符“鐏忓繑妲�”,整个流转过程与b)一样,只是在第一步发生了字节流转换,设置SecureCRT字符集编码,只是改变了显示方式。
字符集相关的SQL语句
1) 查看字符集编码设置
SHOW VARIABLES LIKE ‘%CHARACTER%’
2) 设置字符集编码
SET NAMES xxx;
这个语句相当于设置了client的字符集,主要包含3个系统变量,character_set_client,character_set_connection和character_set_results。
3) 修改数据库字符集
ALTER DATABASE DATABASENAME CHARACTER SET XXX;
这个语句只修改库的字符集,影响后续创建的表的默认定义;对于已创建的表的字符集不受影响。
4) 修改表的字符集
ALTER TABLE TABLENAME CHARACTER SET XXX;
这个语句只修改表的字符集,影响后续该表新增列的默认定义,已有列的字符集不受影响。
ALTER TABLE TABLENAME CONVERT TO CHARACTER SET XXX;
这个语句同时修改表字符集和已有列字符集,并将已有数据进行字符集编码转换。
5) 修改列字符集
ALTER TABLE `TABLE_NAME` MODIFY COLUMN `COLUMN_NAME` CHARACTER SET xxx
6) 查询字符的二进制编码
SELECT HEX(COL_NAME) FROM TABLE_NAME;
SELECT LENGTH(COL_NAME) FROM TABLE_NAME;
对于GBK的表,如果查出来一个字符占用了3个字节,比如图1这种情况,则肯定是字符集在某个环节设置统一,图1就是因为客户端是UTF8,而mysqlclient和database都是GBK造成的。
mysql默认的字符集latin1
mysql 4.x版本之前默认采用的是latin1字符集(又称ISO-8859-1),latin1字符集编码方式采用单字节编码。抛一个问题,latin1字符集的表,用户写入和读取汉字是否有问题?答案是只要合理设置,没有问题。假设SecureCRT为UTF8,character_set_client和表字符集均设置为latin1,参考第3节的分析,那么用户读取和写入数据的过程中,并不涉及字符集编码转换的问题,将UTF8的汉字字符转为二进制流写入database,提取出来后,secureCRT再将对应的二进制解码为对应的汉字,所以不影响用户的使用。但是,若character_set_client,character_set_connection,与表字符集设置等不统一,就可能出现乱码的情况。
使用Navicat客户端运行SQL语句出现中文乱码的更多相关文章
- SQL Server中存储过程比直接运行SQL语句慢的原因
原文:SQL Server中存储过程比直接运行SQL语句慢的原因 在很多的资料中都描述说SQLSERVER的存储过程较普通的SQL语句有以下优点: 1. 存储过程只在创造时进行编译即可,以 ...
- linux程序设计——运行SQL语句(第八章)
8.3 使用C语言訪问MySQL数据 8.3.3 运行SQL语句 运行SQL语句的主要API函数被恰当的命名为: int mysql_query(MYSQL *connection, const ...
- PL/SQL Developer显示中文乱码
PL/SQL Developer显示中文乱码,可能是oracle客户端和服务器端的编码方式不一样. 解决方法: Select userenv('language') from dual; 设置环境变量 ...
- PL/SQL Developer 显示中文乱码问题解决
PL/SQL Developer 显示中文乱码问题简单版本:首先,通过 select userenv('language') from dual;查询oracle服务器端的编码, 如为: AMERIC ...
- response 返回js的alert()语句,中文乱码如何解决
response 返回js的alert()语句,中文乱码如何解决, 步骤1:在后台加上如下代码: response.setCharacterEncoding("utf-8"); r ...
- .Net 执行 Oracle SQL语句时, 中文变问号
带中文的Sql语句在.Net调用时, 中文变问号(可使用 SQL Tracker工具跟踪) 问题: 服务器的字符集与客户端的字符集不一致. 解决方法: 1. 查看服务端的字符集: ...
- oracle从客户端到sql语句追踪
这两天看小布老师的视频学习了一下从客户端到oracle数据库发送执行的SQL语句的跟踪,整理一下笔记. 需要用到的命令:netstat oracle端要用到的四个视图为: V$session:当前有多 ...
- SQL Server中存储过程 比 直接运行SQL语句慢的原因
问题是存储过程的Parameter sniffing 在很多的资料中都描述说SQLSERVER的存储过程较普通的SQL语句有以下优点: 1. 存储过程只在创造时进行编译即可,以后每次执行存储过 ...
- C# 执行oracle sql 语句出现中文不兼容的问题
最近我用C#调用 操作oracle 数据库 出现了一个问题就是 我的查询语中的条件语句 含有中文 字符在C#中查询不了 ,但是在pl sql 中能够正常的查询出来. 这个原因是 C# 执行orccl ...
随机推荐
- SQLSERVER 去除字符串中特殊字符
原文:SQLSERVER 去除字符串中特殊字符 /*========================================================================== ...
- ABP创建应用服务
原文作者:圣杰 原文地址:ABP入门系列(4)——创建应用服务 在原文作者上进行改正,适配ABP新版本.内容相同 1. 解释下应用服务层 应用服务用于将领域(业务)逻辑暴露给展现层.展现层通过传入DT ...
- Spring的四种事务特性,五种隔离级别,七种传播行为
Spring事务: 什么是事务: 事务逻辑上的一组对数据对操作,组成这些操作的各个逻辑单元,要么一起成功,要么一起失败. 事务特性(4种): 原子性(atomicity):强调事务的不可分割:一致性( ...
- 剑指offer3:从尾到头打印链表每个节点的值
1. 题目描述 输入一个链表,从尾到头打印链表每个节点的值. 2. 思路和方法 2.1 推荐的方法 (1)栈,循环 后进先出,我们可以用栈实现这种顺序.每经过一个结点的时候,把该节点放到一个栈里面,当 ...
- django F与Q查询 事务 only与defer
F与Q 查询 class Product(models.Model): name = models.CharField(max_length=32) #都是类实例化出来的对象 price = mode ...
- Censoring(栈+KMP)
# 10048. 「一本通 2.2 练习 4」Censoring [题目描述] 给出两个字符串 $S$ 和 $T$,每次从前往后找到 $S$ 的一个子串 $A=T$ 并将其删除,空缺位依次向前补齐,重 ...
- RHEL8配置本地yum源
在RHEL8中把软件源分成了两部分一个是BaseOS,一个是AppStream. 在Red Hat Enterprise Linux 8.0中,统一的ISO自动加载BaseOS和AppStream安装 ...
- C#解决界面闪烁
添加缓冲: private void SetDoubleBuffer() { base.SetStyle( ControlStyles.OptimizedDoubleBuffer | ControlS ...
- SQL SERVER中Datetime时间的范围与.net的DateTime对象的区别
对于编写.net程序中我们一般写默认的时间,我们会自动创建一个new DateTime()对象.但与SQL SERVER连用我们就会出现一个时间范围的问题. 今天我就记录一下该时间问题. 我们创建的n ...
- 打包JavaFX11桌面应用程序
打包JavaFX11桌面应用程序 这是JavaFX系列的第二弹,第一弹在这里 在第一弹中,我们使用的是OpenJDK8,但是OpenJDK8和Oracle Java JDK不一样,它没有内置JavaF ...