Apache Flink - 内存管理
JVM:
- JAVA本身提供了垃圾回收机制来实现内存管理
现今的GC(如Java和.NET)使用分代收集(generation collection),依照对象存活时间的长短使用不同的垃圾收集算法,以达到最好的收集性能。
以Java为例,整个Java堆可以切割成为三个部分:
- Young:
- Eden:存放新生对象。
- Survivor:存放经过垃圾回收没有被清除的对象。
- semi-Spaces:和Survivor做Copying collection。
- Tenured:对象多次回收没有被清除,则移到该区块。
- Perm:存放加载的类别还有方法对象。
Java不同的世代使用不同的GC算法。
- Minor collection:
- YOUNG世代使用将Eden还有Survivor内的数据利用semi-space做复制收集(Copying collection),
- 并将原本Survivor内经过多次垃圾收集仍然存活的对象移动到Tenured。
- Major collection则会进行Minor collection,Tenured世代则进行标记压缩收集。
- Young:
- JVM存在的问题:
- Java 对象存储密度低。一个只包含 boolean 属性的对象占用了16个字节内存:对象头占了8个,boolean 属性占了1个,对齐填充占了7个。而实际上只需要一个bit。
- 在处理大量数据时会生成大量对象,Java GC可能会被反复触发,其中Full GC或Major GC的开销是非常大的,GC 会达到秒级甚至分钟级。
- OOM 问题影响稳定性。OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemoryError错误,导致JVM崩溃,分布式框架的健壮性和性能都会受到影响。
Flink的内存管理:
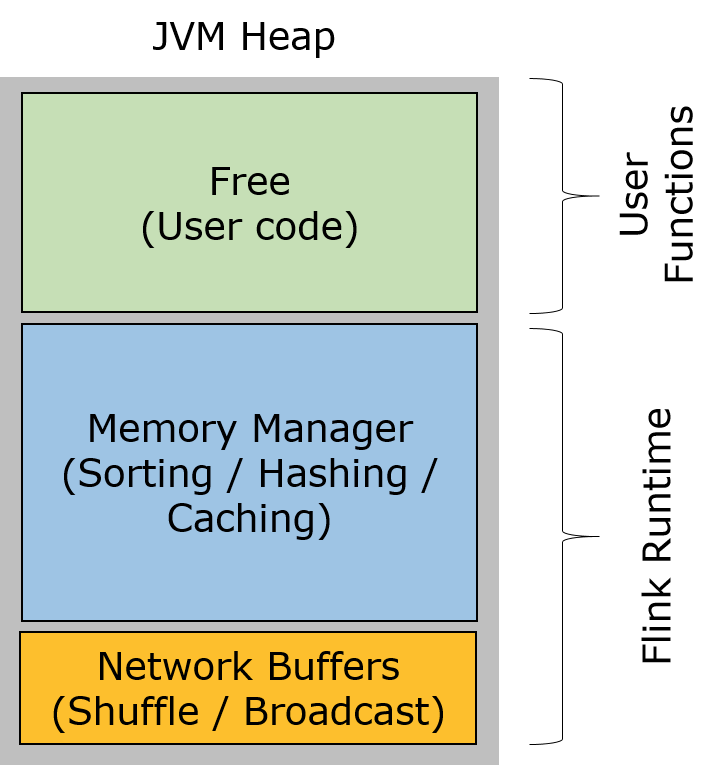
- Flink 并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块上,这个内存块叫做
MemorySegment,它代表了一段固定长度的内存(默认大小为 32KB),也是 Flink 中最小的内存分配单元,并且提供了非常高效的读写方法。每条记录都会以序列化的形式存储在一个或多个MemorySegment中。 - Flink堆内存划分:
- Network Buffers: 一定数量的32KB大小的缓存,主要用于数据的网络传输。在 TaskManager 启动的时候就会分配。默认数量是 2048 个,可以通过
taskmanager.network.numberOfBuffers来配置 - Memory Manager Pool: 这是一个由
MemoryManager管理的,由众多MemorySegment组成的超大集合。Flink 中的算法(如 sort/shuffle/join)会向这个内存池申请 MemorySegment,将序列化后的数据存于其中,使用完后释放回内存池。默认情况下,池子占了堆内存的 70% 的大小。 - Remaining (Free) Heap: 这部分的内存是留给用户代码以及 TaskManager 的数据结构使用的,可以把这里看成的新生代。
- Network Buffers: 一定数量的32KB大小的缓存,主要用于数据的网络传输。在 TaskManager 启动的时候就会分配。默认数量是 2048 个,可以通过
- 序列化与反序列化可以理解为编码与解码的过程。序列化以后的数据希望占用比较小的空间,而且数据能够被正确地反序列化出来。为了能正确反序列化,序列化时仅存储二进制数据本身肯定不够,需要增加一些辅助的描述信息。此处可以采用不同的策略,因而产生了很多不同的序列化方法。Java本身自带的序列化和反序列化的功能,但是辅助信息占用空间比较大,在序列化对象时记录了过多的类信息。
- Flink实现了自己的序列化框架,Flink处理的数据流通常是一种类型,所以可以只保存一份对象Schema信息,节省存储空间。又因为对象类型固定,所以可以通过偏移量存取。
- Java支持任意Java或Scala类型,类型信息由
TypeInformation类表示,TypeInformation 支持以下几种类型:BasicTypeInfo: 任意Java 基本类型或 String 类型。BasicArrayTypeInfo: 任意Java基本类型数组或 String 数组。WritableTypeInfo: 任意 Hadoop Writable 接口的实现类。TupleTypeInfo: 任意的 Flink Tuple 类型(支持Tuple1 to Tuple25)。Flink tuples 是固定长度固定类型的Java Tuple实现。CaseClassTypeInfo: 任意的 Scala CaseClass(包括 Scala tuples)。PojoTypeInfo: 任意的 POJO (Java or Scala),例如,Java对象的所有成员变量,要么是 public 修饰符定义,要么有 getter/setter 方法。GenericTypeInfo: 任意无法匹配之前几种类型的类。
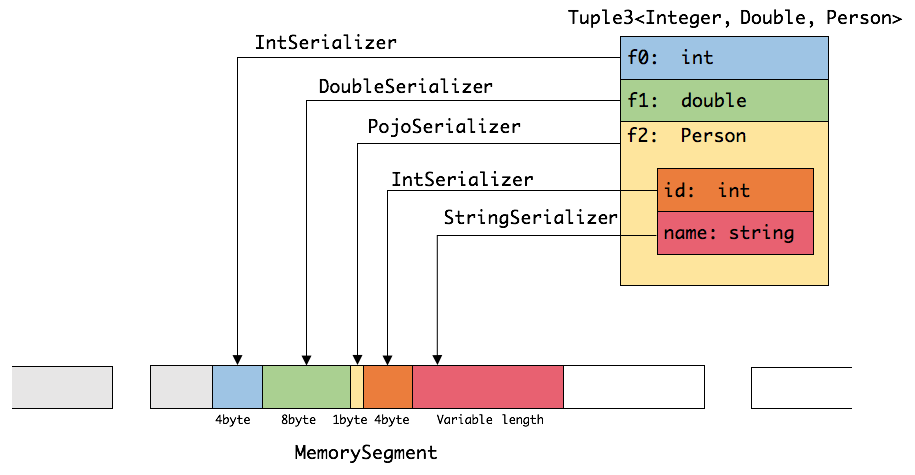
- 针对前六种类型数据集,Flink皆可以自动生成对应的TypeSerializer,能非常高效地对数据集进行序列化和反序列化。对于最后一种数据类型,Flink会使用Kryo进行序列化和反序列化。每个TypeInformation中,都包含了serializer,类型会自动通过serializer进行序列化,然后用Java Unsafe接口写入MemorySegments。如下图展示 一个内嵌型的Tuple3<integer,double,person> 对象的序列化过程:
操纵二进制数据:
- Flink 提供了如 group、sort、join 等操作,这些操作都需要访问海量数据。以sort为例。
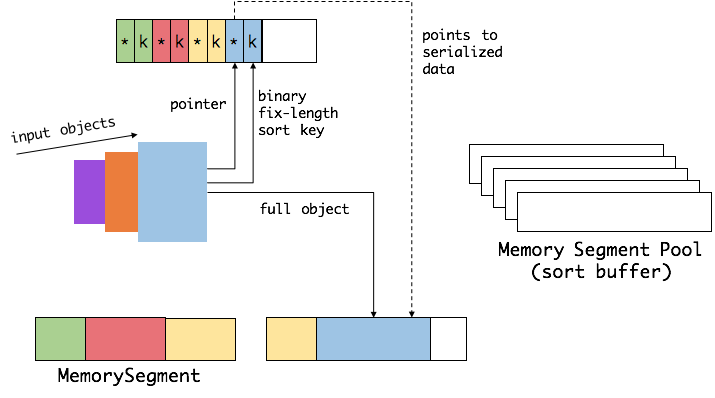
首先,Flink 会从 MemoryManager 中申请一批 MemorySegment,用来存放排序的数据。
- 这些内存会分为两部分,一个区域是用来存放所有对象完整的二进制数据。另一个区域用来存放指向完整二进制数据的指针以及定长的序列化后的key(key+pointer)。将实际的数据和point+key分开存放有两个目的。第一,交换定长块(key+pointer)更高效,不用交换真实的数据也不用移动其他key和pointer。第二,这样做是缓存友好的,因为key都是连续存储在内存中的,可以增加cache命中。 排序会先比较 key 大小,这样就可以直接用二进制的 key 比较而不需要反序列化出整个对象。访问排序后的数据,可以沿着排好序的key+pointer顺序访问,通过 pointer 找到对应的真实数据。
Flink使用堆外内存:
- 启动超大内存(上百GB)的JVM需要很长时间,GC停留时间也会很长(分钟级)。使用堆外内存可以极大地减小堆内存(只需要分配Remaining Heap),使得 TaskManager 扩展到上百GB内存不是问题。
- 进行IO操作时,使用堆外内存可以zero-copy,使用堆内内存至少要复制一次。
- 堆外内存在进程间是共享的。
Apache Flink - 内存管理的更多相关文章
- Flink内存管理源代码解读之基础数据结构
概述 在分布式实时计算领域,怎样让框架/引擎足够高效地在内存中存取.处理海量数据是一个非常棘手的问题.在应对这一问题上Flink无疑是做得非常杰出的,Flink的自主内存管理设计或许比它自身的知名度更 ...
- 一文带你彻底了解大数据处理引擎Flink内存管理
摘要: Flink是jvm之上的大数据处理引擎. Flink是jvm之上的大数据处理引擎,jvm存在java对象存储密度低.full gc时消耗性能,gc存在stw的问题,同时omm时会影响稳定性.同 ...
- Apache Spark 内存管理详解(转载)
Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行性能调优.本文旨在梳理出 ...
- Apache Spark 内存管理详解
在spark里面,内存管理有两块组成,一部分是JVM的堆内内存(on-heap memory),这部分内存是通过spark dirver参数executor-memory以及spark.executo ...
- Spark内存管理机制
Spark内存管理机制 Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行 ...
- Off-heap Memory in Apache Flink and the curious JIT compiler
https://flink.apache.org/news/2015/09/16/off-heap-memory.html Running data-intensive code in the J ...
- Peeking into Apache Flink's Engine Room
http://flink.apache.org/news/2015/03/13/peeking-into-Apache-Flinks-Engine-Room.html Join Processin ...
- Apache Flink
Flink 剖析 1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来, ...
- 新一代大数据处理引擎 Apache Flink
https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/index.html 大数据计算引擎的发展 这几年大数据的飞速发 ...
随机推荐
- echart——vue封装成公共组件
<!-- 自定义Echarts * options: Object,//数据 * theme: String,//主题 * initOptions: Object,//初始化 * group: ...
- nginx 请求限制和访问控制
请求限制 限制主要有两种类型: 连接频率限制: limit_conn_module 请求频率限制: limit_req_module HTTP协议的连接与请求 HTTP协议是基于TCP的,如果要完成一 ...
- [#Linux] CentOS 7 应用程序添加快捷方式到桌面
在centos使用中,会发现应用程序只能到eclipse的目录中执行eclipse的脚本去启动.这样很不方便. 查阅资料后找到了解决方案: 1.通过命令行,进入到桌面文件夹中 cd /home/you ...
- 第十八篇:简易版web服务器开发
在上篇有实现了一个静态的web服务器,可以接收web浏览器的请求,随后对请求消息进行解析,获取客户想要文件的文件名,随后根据文件名返回响应消息:那么这篇我们对该web服务器进行改善,通过多任务.非阻塞 ...
- Django之模型层2
多表操作 创建模型 实例:我们来假定下面这些概念,字段和关系 作者模型:一个作者有姓名和年龄. 作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息.作者详情模型和作者模型之间是一对 ...
- Python函数Day6
一.内置函数 list() 将一个可迭代对象转化为列表 字典转为列表:会将所有键转化为列表 字符串转为列表:键每个字符转化为列表 s = 'abc' dic = {'a':1,'b':2,'c':3} ...
- Linux命令——pgrep
参考:Linux pgrep Command Tutorial for Beginners (10 Examples) Linux命令——ps.pstree bash基础——grep.基本正则表达式. ...
- JAVA设计模式之单例模式(单件模式)—Singleton Pattern
1.什么是单例模式? <Head First 设计模式>中给出如下定义:确保一个类只有一个实例,并提供一个全局访问点. 关键词:唯一实例对象. 2.单例模式的实现方式: 2.1 懒汉式 对 ...
- 开源框架---tensorflow c++ API 运行第一个“手写字的例子”
#CMakeLists.txt cmake_minimum_required (VERSION ) project (tf_example) set(CMAKE_CXX_FLAGS "${C ...
- Scala配置环境变量windows
scala下载官网网址:http://www.scala-lang.org/download/ 1.下载scala-2.10.4.msi 2.点击安装scala,默认安装路径 3.配置环境变量 ( ...