7.MapReduce操作Hbase
7 HBase的MapReduce
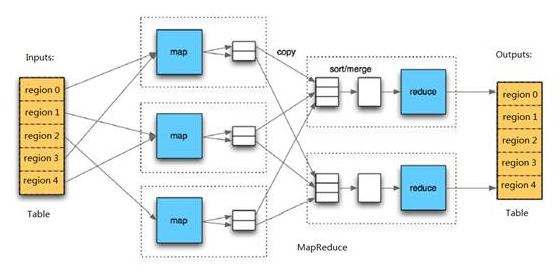
HBase中Table和Region的关系,有些类似HDFS中File和Block的关系。由于HBase提供了配套的与MapReduce进行交互的API如
TableInputFormat和TableOutputFormat,可以将HBase的数据表直接作为Hadoop MapReduce的输入和输出,从而方便了MapReduce
应用程序的开发,基本不需要关注HBase系统自身的处理细节。
8 实现方法:
Hbase对MapReduce提供支持,它实现了TableMapper类和TableReducer类,我们只需要继承这两个类即可
1、写个mapper继承TableMapper<Text, IntWritable>:参数:Text:mapper的输出key类型; IntWritable:mapper的输出value类型。
其中的map方法如下:
map(ImmutableBytesWritable key, Result value,Context context):参数:key:rowKey;value: Result ,一行数据; context上下文
2、写个reduce继承TableReducer<Text, IntWritable, ImmutableBytesWritable>:参数:Text:reducer的输入key; IntWritable:reduce的输入value
ImmutableBytesWritable:reduce输出到hbase中的rowKey类型。
其中的reduce方法如下:
reduce(Text key, Iterable<IntWritable> values,Context context)
参数: key:reduce的输入key;values:reduce的输入value;
详细代码文件:
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
/**
* mapreduce操作hbase:创建word表,并插入数据,通过MapReduce将word表中的数据写入创建的hbase新表stat表
*/
public class HBaseMr {
/**
* 创建hbase配置
*/
static Configuration config = null;
static {
config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "shizhan3,shizhan5,shizhan6");
config.set("hbase.zookeeper.property.clientPort", "2183");
}
/**
* 表信息
*/
public static final String tableName = "word";//表名1
public static final String colf = "content";//列族
public static final String col = "info";//列
public static final String tableName2 = "stat";//表名2
/**
* 初始化表结构,及其数据
*/
public static void initTB() {
HTable table=null;
HBaseAdmin admin=null;
try {
admin = new HBaseAdmin(config);//创建表管理
/*删除表*/
if (admin.tableExists(tableName)||admin.tableExists(tableName2)) {
System.out.println("table is already exists!");
admin.disableTable(tableName);
admin.deleteTable(tableName);
admin.disableTable(tableName2);
admin.deleteTable(tableName2);
}
/*创建表*/
HTableDescriptor desc = new HTableDescriptor(tableName);
HColumnDescriptor family = new HColumnDescriptor(colf);
desc.addFamily(family);
admin.createTable(desc);
HTableDescriptor desc2 = new HTableDescriptor(tableName2);
HColumnDescriptor family2 = new HColumnDescriptor(colf);
desc2.addFamily(family2);
admin.createTable(desc2);
/*插入数据*/
table = new HTable(config,tableName);
table.setAutoFlush(false);
table.setWriteBufferSize(500);
List<Put> lp = new ArrayList<Put>();
Put p1 = new Put(Bytes.toBytes("1"));
p1.add(colf.getBytes(), col.getBytes(), ("The Apache Hadoop software library is a framework").getBytes());
lp.add(p1);
Put p2 = new Put(Bytes.toBytes("2"));p2.add(colf.getBytes(),col.getBytes(),("The common utilities that support the other Hadoop modules").getBytes());
lp.add(p2);
Put p3 = new Put(Bytes.toBytes("3"));
p3.add(colf.getBytes(), col.getBytes(),("Hadoop by reading the documentation").getBytes());
lp.add(p3);
Put p4 = new Put(Bytes.toBytes("4"));
p4.add(colf.getBytes(), col.getBytes(),("Hadoop from the release page").getBytes());
lp.add(p4);
Put p5 = new Put(Bytes.toBytes("5"));
p5.add(colf.getBytes(), col.getBytes(),("Hadoop on the mailing list").getBytes());
lp.add(p5);
table.put(lp);
table.flushCommits();
lp.clear();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if(table!=null){
table.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* MyMapper 继承 TableMapper
* TableMapper<Text,IntWritable>
* Text:输出的key类型,
* IntWritable:输出的value类型
*/
public static class MyMapper extends TableMapper<Text, IntWritable> {
private static IntWritable one = new IntWritable(1);
private static Text word = new Text();
@Override
//输入的类型为:key:rowKey; value:一行数据的结果集Result
protected void map(ImmutableBytesWritable key, Result value,Context context) throws IOException, InterruptedException {
//获取一行数据中的colf:col
String words = Bytes.toString(value.getValue(Bytes.toBytes(colf), Bytes.toBytes(col)));// 表里面只有一个列族,所以我就直接获取每一行的值
//按空格分割
String itr[] = words.toString().split(" ");
//循环输出word和1
for (int i = 0; i < itr.length; i++) {
word.set(itr[i]);
context.write(word, one);
}
}
}
/**
* MyReducer 继承 TableReducer
* TableReducer<Text,IntWritable>
* Text:输入的key类型,
* IntWritable:输入的value类型,
* ImmutableBytesWritable:输出类型,表示rowkey的类型
*/
public static class MyReducer extends
TableReducer<Text, IntWritable, ImmutableBytesWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
//对mapper的数据求和
int sum = 0;
for (IntWritable val : values) {//叠加
sum += val.get();
}
// 创建put,设置rowkey为单词
Put put = new Put(Bytes.toBytes(key.toString()));
// 封装数据
put.add(Bytes.toBytes(colf), Bytes.toBytes(col),Bytes.toBytes(String.valueOf(sum)));
//写到hbase,需要指定rowkey、put
context.write(new ImmutableBytesWritable(Bytes.toBytes(key.toString())),put);
}
} public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
//初始化表
initTB();//初始化表
//创建job
Job job = new Job(config, "HBaseMr");//job
job.setJarByClass(HBaseMr.class);//主类
//创建scan
Scan scan = new Scan();
//可以指定查询某一列
scan.addColumn(Bytes.toBytes(colf), Bytes.toBytes(col));
//创建查询hbase的mapper,设置表名、scan、mapper类、mapper的输出key、mapper的输出value
TableMapReduceUtil.initTableMapperJob(tableName, scan, MyMapper.class,Text.class, IntWritable.class, job);
//创建写入hbase的reducer,指定表名、reducer类、job
TableMapReduceUtil.initTableReducerJob(tableName2, MyReducer.class, job);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
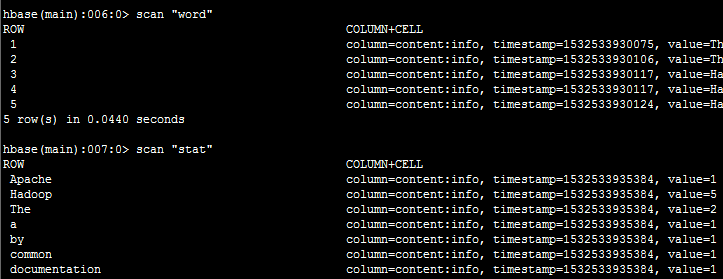
运行截图:
程序下载链接:https://pan.baidu.com/s/1ofHWKNV9F-R8OcW54PGJ5g
总结:
通过Mr操作Hbase的‘word’表,对‘content:info’中的短文做词频统计,并将统计结果写入‘stat’表的‘content:info中’,
行键为单词
7.MapReduce操作Hbase的更多相关文章
- Mapreduce操作HBase
这个操作和普通的Mapreduce还不太一样,比如普通的Mapreduce输入可以是txt文件等,Mapreduce可以直接读取Hive中的表的数据(能够看见是以类似txt文件形式),但Mapredu ...
- HBase 相关API操练(三):MapReduce操作HBase
MapReduce 操作 HBase 在 HBase 系统上运行批处理运算,最方便和实用的模型依然是 MapReduce,如下图所示. HBase Table 和 Region 的关系类似 HDFS ...
- Hbase理论&&hbase shell&&python操作hbase&&python通过mapreduce操作hbase
一.Hbase搭建: 二.理论知识介绍: 1Hbase介绍: Hbase是分布式.面向列的开源数据库(其实准确的说是面向列族).HDFS为Hbase提供可靠的底层数据存储服务,MapReduce为Hb ...
- Hbase第五章 MapReduce操作HBase
容易遇到的坑: 当用mapReducer操作HBase时,运行jar包的过程中如果遇到 java.lang.NoClassDefFoundError 类似的错误时,一般是由于hadoop环境没有hba ...
- HBase学习之路 (五)MapReduce操作Hbase
MapReduce从HDFS读取数据存储到HBase中 现有HDFS中有一个student.txt文件,格式如下 95002,刘晨,女,19,IS 95017,王风娟,女,18,IS 95018,王一 ...
- MapReduce操作Hbase --table2file
官方手册:http://hbase.apache.org/book.html#mapreduce.example 简单的操作,将hbase表中的数据写入到文件中. RunJob 源码: import ...
- hadoop2的mapreduce操作hbase数据
1.从hbase中取数据,再把计算结果插入hbase中 package com.yeliang; import java.io.IOException; import org.apache.hadoo ...
- 大数据入门第十四天——Hbase详解(三)hbase基本原理与MR操作Hbase
一.基本原理 1.hbase的位置 上图描述了Hadoop 2.0生态系统中的各层结构.其中HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持, MapReduce为HBas ...
- Hbase框架原理及相关的知识点理解、Hbase访问MapReduce、Hbase访问Java API、Hbase shell及Hbase性能优化总结
转自:http://blog.csdn.net/zhongwen7710/article/details/39577431 本blog的内容包含: 第一部分:Hbase框架原理理解 第二部分:Hbas ...
随机推荐
- 安卓 adb命令
获取包名 aapt d badging C:\Users\600844\Desktop\beijingtoon.apk "package launchable-activity" ...
- matlab截取图像
声明:引用请注明出处http://blog.csdn.net/lg1259156776/ 对于Matlab的使用情况常常是这样子的,很多零碎的函数名字很难记忆,经常用过后过一段时间就又忘记了,又得去网 ...
- windows服务器入门 初始化数据盘
本人在寒假的时候自行搭建了一个服务器,在此分享一下我的方法.本人服务器的系统为Windows 2012R2 在后面的讲解中中文英文都会有 所以不用在意系统的语言问题 1)第一步 自然就是打开服 ...
- php5.6安装及php-fpm优化配置
1,安装依赖包: yum install -y gcc gcc-c++ zlib zlib-devel pcre pcre-devel gd libjpeg libjpeg-devel libpn ...
- python不定长参数 *argc,**kargcs(19)
在 python函数的声明和调用 中我们简单的了解了函数的相关使用,然而在函数传递参数的时候,我们埋下了一个坑,关于不定长参数的传递我们还没有讲,今天这篇文章主要就是讲解这个问题. 一.函数不定长参数 ...
- 乐字节Java循环:循环控制和嵌套循环
乐字节小乐上次讲完了Java反射,接下来小乐给大家讲述Java循环. 循环有以下四部分: 一.循环控制 1. do..while 直到型 ( 先执行后判断) ,结构为: 先执行循环体,后判断布尔表达式 ...
- ABP中的本地化处理(上)
今天这篇文章主要来总结一下ABP中的多语言是怎么实现的,在后面我们将结合ABP中的源码和相关的实例来一步步进行说明,在介绍这个之前我们先来看看ABP的官方文档,通过这个文档我们就知道怎样在我们的系统中 ...
- GstStaticCaps的初始化
struct _GstStaticCaps { /*< public >*/ GstCaps *caps; const char *string; /*< private >* ...
- 附录:ARM 手册 词汇表
来自:<DDI0406C_C_arm_architecture_reference_manual.pdf>p2723 能够查询到:“RAZ RAO WI 等的意思” RAZ:Read-As ...
- Creating a ModelForm without either the 'fields' attribute or the 'exclude' attribute is prohibited; form ResumeForm needs updating.
django 报错 django.core.exceptions.ImproperlyConfigured: Creating a ModelForm without either the 'fiel ...