Python 【爬虫】
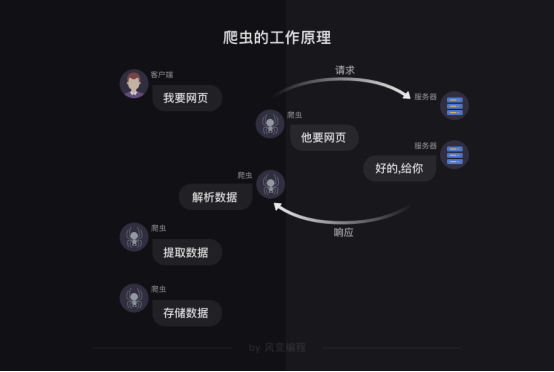
爬虫的工作原理
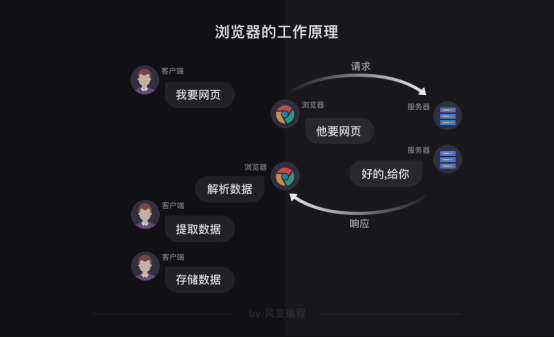
首先,爬虫可以模拟浏览器去向服务器发出请求;
其次,等服务器响应后,爬虫程序还可以代替浏览器帮我们解析数据;
接着,爬虫可以根据我们设定的规则批量提取相关数据,而不需要我们去手动提取;
最后,爬虫可以批量地把数据存储到本地
爬虫的步骤

第0步:获取数据。爬虫程序会根据我们提供的网址,向服务器发起请求,然后返回数据。
第1步:解析数据。爬虫程序会把服务器返回的数据解析成我们能读懂的格式。
第2步:提取数据。爬虫程序再从中提取出我们需要的数据。
第3步:储存数据。爬虫程序把这些有用的数据保存起来,便于你日后的使用和分析。
#######################################################################
Mac pip3 install requests
Win pip install requests
requests库可以帮我们下载网页源代码、文本、图片,甚至是音频
import requests
#引入requests库
res = requests.get('URL')
#requests.get是在调用requests库中的get()方法,它向服务器发送了一个请求,括号里的参数是你需要的数据所在的网址,然后服务器对请求作出了响应。
#我们把这个响应返回的结果赋值在变量res上。

##############################################################
Response对象的常用属性

response.status_code
print(变量.status_code)
用来检查请求是否正确响应,如果响应状态码为200,即代表请求成功
response.content
把Response对象的内容以二进制数据的形式返回,适用于图片、音频、视频的下载
import requests
res = requests.get('https://res.pandateacher.com/2018-12-18-10-43-07.png')
#发出请求,并把返回的结果放在变量res中
pic=res.content
#把Reponse对象的内容以二进制数据的形式返回
photo = open('ppt.jpg','wb')
#新建了一个文件ppt.jpg,这里的文件没加路径,它会被保存在程序运行的当前目录下。
#图片内容需要以二进制wb读写。你在学习open()函数时接触过它。
photo.write(pic)
#获取pic的二进制内容
photo.close()
#关闭文件
response.text
把Response对象的内容以字符串的形式返回,适用于文字、网页源代码的下载
import requests
#引用requests库
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md')
#下载《三国演义》第一回,我们得到一个对象,它被命名为res
novel=res.text
#把Response对象的内容以字符串的形式返回
print(novel[:800])
#现在,可以打印小说了,但考虑到整章太长,只输出800字看看就好。在关于列表的知识那里,你学过[:800]的用法。
k = open('《三国演义》.txt', 'a+')
k.write(novel)
k.close()
response.encoding
#语法:res.encoding=''
import requests
#引用requests库
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md')
#下载《三国演义》第一回,我们得到一个对象,它被命名为res
res.encoding='utf-8'
#定义Reponse对象的编码为utf-8。
novel=res.text
#把Response对象的内容以字符串的形式返回
print(novel[:800])
#打印小说的前800个字。
定义Response对象的编码
遇上文本的乱码问题,才考虑用res.encoding
目标数据本身是什么编码是未知的。
用requests.get()发送请求后,我们会取得一个Response对象,其中,requests库会对数据的编码类型做出自己的判断。
但是!这个判断有可能准确,也可能不准确。
如果它判断准确的话,我们打印出来的response.text的内容就是正常的、没有乱码的,那就用不到res.encoding;
如果判断不准确,就会出现一堆乱码,那我们就可以去查看目标数据的编码,然后再用res.encoding把编码定义成和目标数据一致的类型即可。

####################################################################
Robots协议
“网络爬虫排除标准”(Robots exclusion protocol),这个协议用来告诉爬虫,哪些页面是可以抓取的,哪些不可以。
#查看robots协议 网站的域名后加上/robots.txt
User-agent: Baiduspider #百度爬虫
Allow: /article #允许访问 /article.htm
Allow: /oshtml #允许访问 /oshtml.htm
Allow: /ershou #允许访问 /ershou.htm
Allow: /$ #允许访问根目录,即淘宝主页
Disallow: /product/ #禁止访问/product/
Disallow: / #禁止访问除 Allow 规定页面之外的其他所有页面
User-Agent: Googlebot #谷歌爬虫
Allow: /article
Allow: /oshtml
Allow: /product #允许访问/product/
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Allow: /ershou
Allow: /$
Disallow: / #禁止访问除 Allow 规定页面之外的其他所有页面
…… # 文件太长,省略了对其它爬虫的规定,想看全文的话,点击上面的链接
User-Agent: * #其他爬虫
Disallow: / #禁止访问所有页面
爬取时,先看看网站的Robots协议是否允许你去爬取
限制好爬虫的速度
Python 【爬虫】的更多相关文章
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python 爬虫(二)
python 爬虫 Advanced HTML Parsing 1. 通过属性查找标签:基本上在每一个网站上都有stylesheets,针对于不同的标签会有不同的css类于之向对应在我们看到的标签可能 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- [python]爬虫学习(一)
要学习Python爬虫,我们要学习的共有以下几点(python2): Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
随机推荐
- ZR#959
ZR#959 解法: 对于一个询问,设路径 $ (u, v) $ 经过的所有边的 $ gcd $ 为 $ g $,这可以倍增求出. 考虑 $ g $ 的所有质因子 $ p_1, p_2, \cdots ...
- Tkinter 之Text文本框标签
一.参数说明 语法 作用 t=tk.Text()t.insert(END,'插入的文本信息') INSERT:光标的插入点CURRENT:鼠标的当前位置所对应的字符位置END:这个Textbuffer ...
- 说自己熟悉 Spring Cloud 这些面试题你会吗
问题一:什么是Spring Cloud? Spring cloud流应用程序启动器是基于Spring Boot的Spring集成应用程序,提供与外部系统的集成.Spring cloud Task,一个 ...
- Java实现通过IP获取域名,通过域名获取IP
一.通过Linux命令实现 ping www.baidu.com nslookup www.baidu.com nslookup 14.215.177.166 为什么这个命令会有一个192.168.1 ...
- php语言查询Mysql数据库内容
通过php语言实现对Mysql数据库的基本操作 1.php页面在进行浏览时需要有php语言执行的环境,本人用的是WampServer软件,只要将项目复制到wampserver_php\wamp\www ...
- Go 语言入门(三)并发
写在前面 在学习 Go 语言之前,我自己是有一定的 Java 和 C++ 基础的,这篇文章主要是基于A tour of Go编写的,主要是希望记录一下自己的学习历程,加深自己的理解 Go 语言入门(三 ...
- legend3---开发总结1
legend3---开发总结1 一.总结 一句话总结: 管它柳绿花红,我自潇洒人间 1.数据库字段命名:比如l_id? 见名知意,字段唯一,方便连表 2.所有方法在服务端都要加验证? 比如先查数据再更 ...
- LiquiBase实战总结
LiquiBase概述 Liquibase是一个用于跟踪.管理和应用数据库变化的开源的数据库重构工具.它将所有数据库的变化(包括结构和数据)都保存在XML文件中,便于版本控制. Liquibase具备 ...
- mysql占用服务器cpu过高的原因以及解决办法
登陆Mysql: mysql -p<port> -u<user> -p<pwd> mysql> show processlist; show processl ...
- navigationBarTitleText
想修改整个程序的导航栏,在app.json 文件 修改 "window": { "backgroundTextStyle": "light" ...