049 DSL语句
1.说明

2.sql程序
package com.scala.it import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show()
}
}
3.效果
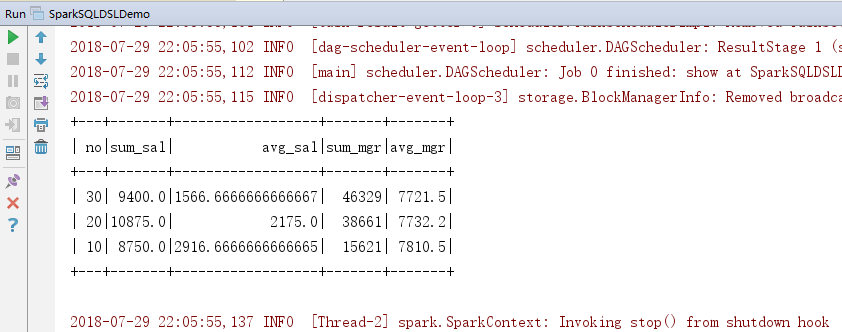
4.DSL对上面程序重构
package com.scala.it import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show() //=================================================
// 读取数据形成DataFrame,并缓存DataFrame
val df = sqlContext.read.table("hadoop09.emp")
df.cache()
//=================================================
import sqlContext.implicits._
import org.apache.spark.sql.functions._ //=================================================对上面sql进行DSL
df.select("deptno", "sal", "mgr")
.groupBy("deptno")
.agg(
sum("sal").as("sum_sal"),
avg("sal").as("avg_sal"),
sum("mgr").as("sum_mgr"),
avg("mgr").as("avg_mgr")
)
.orderBy($"deptno".desc)
.show()
}
}
5.效果

6.Select语句
可以使用string,也可以使用col,或者$。
在Select中可以使用自定义的函数进行使用。
package com.scala.it import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show() //=================================================
// 读取数据形成DataFrame,并缓存DataFrame
val df = sqlContext.read.table("hadoop09.emp")
df.cache()
//=================================================
import sqlContext.implicits._
import org.apache.spark.sql.functions._ //=================================================Select语句
df.select("empno", "ename", "deptno").show()
df.select(col("empno").as("id"), $"ename".as("name"), df("deptno")).show()
df.select($"empno".as("id"), substring($"ename", 0, 1).as("name")).show()
df.selectExpr("empno as id", "substring(ename,0,1) as name").show() //使用自定义的函数
sqlContext.udf.register(
"doubleValueFormat", // 自定义函数名称
(value: Double, scale: Int) => {
// 自定义函数处理的代码块
BigDecimal.valueOf(value).setScale(scale, RoundingMode.HALF_DOWN).doubleValue()
})
df.selectExpr("doubleValueFormat(sal,2)").show()
}
}
7.Where语句
//=================================================Where语句
df.where("sal > 1000 and sal < 2000").show()
df.where($"sal" > 1000 && $"sal" < 2000).show()
8.groupBy语句
建议使用第三种方式,也是最常见的使用方式。
同样是支持自定义函数。
package com.scala.it import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show() //=================================================
// 读取数据形成DataFrame,并缓存DataFrame
val df = sqlContext.read.table("hadoop09.emp")
df.cache()
//=================================================
import sqlContext.implicits._
import org.apache.spark.sql.functions._ //=================================================GroupBy语句
//这种方式不推荐使用,下面也说明了问题
df.groupBy("deptno").agg(
"sal" -> "min", // 求min(sal)
"sal" -> "max", // 求max(sal) ===> 会覆盖同列的其他聚合函数,解决方案:重新命名
"mgr" -> "max" // 求max(mgr)
).show() sqlContext.udf.register("selfAvg", AvgUDAF)
df.groupBy("deptno").agg(
"sal" -> "selfAvg"
).toDF("deptno", "self_avg_sal").show() df.groupBy("deptno").agg(
min("sal").as("min_sal"),
max("sal").as("max_sal"),
max("mgr")
).where("min_sal > 1200").show() }
}
9.sort、orderBy排序
//=================================================数据排序
// sort、orderBy ==> 全局有序
// repartition ==> 局部数据有序
df.sort("sal").select("empno", "sal").show()
df.repartition(3).sort($"sal".desc).select("empno", "sal").show()
df.repartition(3).orderBy($"sal".desc).select("empno", "sal").show()
df.repartition(3).sortWithinPartitions($"sal".desc).select("empno", "sal").show()
10.窗口函数
//=================================================Hive的窗口分析函数
// 必须使用HiveContext来构建DataFrame
// 通过row_number函数来实现分组排序TopN的需求: 先按照某些字段进行数据分区,然后分区的数据在分区内进行topN的获取
val window = Window.partitionBy("deptno").orderBy($"sal".desc)
df.select(
$"empno",
$"ename",
$"deptno",
row_number().over(window).as("rnk")
).where("rnk <= 3").show()
二:总程序总览
package com.scala.it import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show() //=================================================
// 读取数据形成DataFrame,并缓存DataFrame
val df = sqlContext.read.table("hadoop09.emp")
df.cache()
//=================================================
import sqlContext.implicits._
import org.apache.spark.sql.functions._ //=================================================对上面sql进行DSL
df.select("deptno", "sal", "mgr")
.groupBy("deptno")
.agg(
sum("sal").as("sum_sal"),
avg("sal").as("avg_sal"),
sum("mgr").as("sum_mgr"),
avg("mgr").as("avg_mgr")
)
.orderBy($"deptno".desc)
.show() //=================================================Select语句
df.select("empno", "ename", "deptno").show()
df.select(col("empno").as("id"), $"ename".as("name"), df("deptno")).show()
df.select($"empno".as("id"), substring($"ename", 0, 1).as("name")).show()
df.selectExpr("empno as id", "substring(ename,0,1) as name").show() //使用自定义的函数
sqlContext.udf.register(
"doubleValueFormat", // 自定义函数名称
(value: Double, scale: Int) => {
// 自定义函数处理的代码块
BigDecimal.valueOf(value).setScale(scale, RoundingMode.HALF_DOWN).doubleValue()
})
df.selectExpr("doubleValueFormat(sal,2)").show() //=================================================Where语句
df.where("sal > 1000 and sal < 2000").show()
df.where($"sal" > 1000 && $"sal" < 2000).show() //=================================================GroupBy语句
//这种方式不推荐使用,下面也说明了问题
df.groupBy("deptno").agg(
"sal" -> "min", // 求min(sal)
"sal" -> "max", // 求max(sal) ===> 会覆盖同列的其他聚合函数,解决方案:重新命名
"mgr" -> "max" // 求max(mgr)
).show() sqlContext.udf.register("selfAvg", AvgUDAF)
df.groupBy("deptno").agg(
"sal" -> "selfAvg"
).toDF("deptno", "self_avg_sal").show() df.groupBy("deptno").agg(
min("sal").as("min_sal"),
max("sal").as("max_sal"),
max("mgr")
).where("min_sal > 1200").show() //=================================================数据排序
// sort、orderBy ==> 全局有序
// repartition ==> 局部数据有序
df.sort("sal").select("empno", "sal").show()
df.repartition(3).sort($"sal".desc).select("empno", "sal").show()
df.repartition(3).orderBy($"sal".desc).select("empno", "sal").show()
df.repartition(3).sortWithinPartitions($"sal".desc).select("empno", "sal").show() //=================================================Hive的窗口分析函数
// 必须使用HiveContext来构建DataFrame
// 通过row_number函数来实现分组排序TopN的需求: 先按照某些字段进行数据分区,然后分区的数据在分区内进行topN的获取
val window = Window.partitionBy("deptno").orderBy($"sal".desc)
df.select(
$"empno",
$"ename",
$"deptno",
row_number().over(window).as("rnk")
).where("rnk <= 3").show()
}
}
049 DSL语句的更多相关文章
- ElasticSearch实战系列二: ElasticSearch的DSL语句使用教程---图文详解
前言 在上一篇中介绍了ElasticSearch集群和kinaba的安装教程,本篇文章就来讲解下 ElasticSearch的DSL语句使用. ElasticSearch DSL 介绍 Elastic ...
- [elk]elasticsearch dsl语句
例子1 统计1,有唱歌兴趣的 2,按年龄分组 3,求每组平均年龄 4,按平均年龄降序排序 sql转为dsl例子 # 每种型号车的颜色数 > 1的 SELECT model,COUNT(DISTI ...
- Elasticsearch DSL语句之连接查询
传统数据库支持的full join(全连接)查询方式. 这种方式在Elasticsearch中使用时非常昂贵的.因此,Elasticsearch提供两种操作可以支持水平扩展 更多内容请参考Elasti ...
- kibana常用聚合查询DSL语句记录
-------- GET winlogbeat-2017.11.*/_search { "query": { "bool": { "must" ...
- ES 20 - 查询Elasticsearch中的数据 (基于DSL查询, 包括查询校验match + bool + term)
目录 1 什么是DSL 2 DSL校验 - 定位不合法的查询语句 3 match query的使用 3.1 简单功能示例 3.1.1 查询所有文档 3.1.2 查询满足一定条件的文档 3.1.3 分页 ...
- Elasticsearch DSL 常用语法介绍
课程环境 CentOS 7.3 x64 JDK 版本:1.8(最低要求),主推:JDK 1.8.0_121 Elasticsearch 版本:5.2.0 相关软件包百度云下载地址(密码:0yzd):h ...
- ElasticSearch入门系列(三)文档,索引,搜索和聚合
一.文档 在实际使用中的对象往往拥有复杂的数据结构 Elasticsearch是面向文档的,这意味着他可以存储整个对象或文档,然而他不仅仅是存储,还会索引每个文档的内容使之可以被搜索,在Elastic ...
- Gradle学习系列之三——读懂Gradle语法
在本系列的上篇文章中,我们讲到了创建Task的多种方法,在本篇文章中,我们将学习如何读懂Gradle. 请通过以下方式下载本系列文章的Github示例代码: git clone https://git ...
- Gradle学习
Gradle是一种构建工具,它抛弃了基于XML的构建脚本,取而代之的是采用一种基于Groovy的内部领域特定语言.近期,Gradle获得了极大的关注,这也是我决定去研究Gradle的原因. 这篇文章是 ...
随机推荐
- 时间日期date/cal
命令: date 作用: 查看下系统时间 使用: date 命令: cal 对应英文: calendar 作用: 查看日历 选项: -y:可查看一年的日历 使用: cal cal -y
- layui框架中关于table方法级渲染和自动化渲染之间的区别简单介绍
方法级渲染: <table class="layui-hide" id="LAY_table_user" lay-filter="user&qu ...
- 基于ARM Cortex-M和Eclipse的SWO单总线输出
最近在MCU on Eclipse网站上看到Erich Styger所写的一篇有关通过SWD的跟踪接口SWO获取ARM Cortex-M相关信息的文章,文章结构明晰,讲解透彻,本人深受启发,特意将其翻 ...
- windows+mysql集群搭建-三分钟搞定集群
注:本文来源: 陈晓婵 < windows+mysql集群搭建-三分钟搞定集群 > 一:mysql集群搭建教程-基础篇 计算机一级考试系统要用集群,目标是把集群搭建起来,保证一 ...
- Confluence 6 重构索引缓慢
你的索引构建是否需要很长时间?索引构建需要的时间是由下面的一些因素确定的: 你 Confluence 安装实例中的页面数量. 附件的数量,类型和大小. Confluence 安装实例可用的内存大小. ...
- Confluence 6 针对你的数据库类型确定校验 SQL
不同的数据库通常要求不同的 SQL 校验查询.校验查询通常需要尽可能的简单,这个查询在链接从数据库连接池中取出的时候都会被执行一次. 针对不同的数据库类型,我们推荐先的校验查询 SQL: MySQL ...
- 【ftp】主动模式和被动模式
来自:http://blog.csdn.net/liuhelong12/article/details/50218311 原博主不让转载全文,不过下面这部分是原博主转载别人的,所以我拿过来应该没问题吧 ...
- laravel CSRF 保护
在开始之前让我们来实现上述表单访问伪造的完整示例,为简单起见,我们在路由闭包中实现所有业务代码: Route::get('task/{id}/delete', function ($id) { ret ...
- java web----TCP/DUP 通信
服务端和单客户端通信 注意事项:如果服务端或者客户端采用read() 一个字节这种读取数据,只要另一方没有关闭连接,read是永远读取不到-1,会陷入死循环中: 解决方法:加上一个判断,程序员自己跳出 ...
- fdisk命令
fdisk -l命令详解 Disk /dev/sda: 53.7 GB, 53687091200 bytes 块设备名称为/dev/sda,此设备的大小为53.7GB,这个数字不是特别精确,我系统是5 ...