spark单机搭建
说明:单机版的Spark的机器上只需要安装Scala和JDK即可,其他诸如Hadoop、Zookeeper之类的东西可以一概不安装
只需下载如下三个包

1.安装jdk

配置环境变量
vim /etc/profile

路径根据自己的解压路径配置
之后将其生效
source /etc/profile
2安装scala

配置环境变量

同样执行命令source /etc/profile
3,最后安装spark

同样配置环境变量,执行命令使其生效,ps,path中的$PATH必须要加,否则bash脚本失效

那么现在看spark是否能成功启动
cd之spark的bin目录,执行./bin/spark-shell
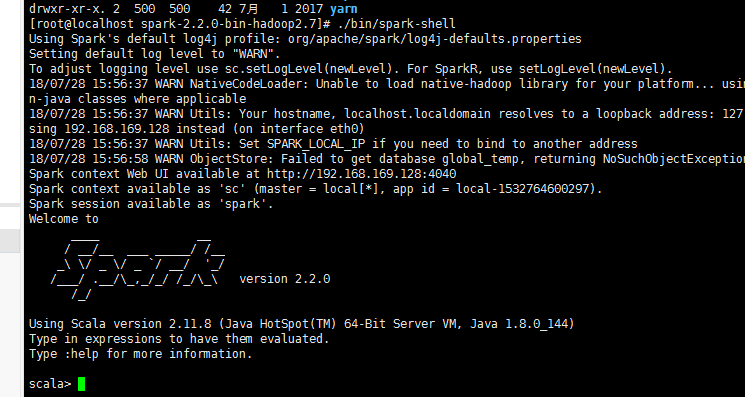
则进入scala交互环境,则成功启动
写个python脚本测试下
# _*_ coding:utf-8 _*_
from __future__ import print_function from pyspark.sql import SparkSession
from pyspark.sql import Row def json_dataset_example(spark):
sc = spark.sparkContext #读取json串
path = "/home/hadoop/spark-2.2.0-bin-hadoop2.7/mydemo/employees.json"
peopleDF = spark.read.json(path) peopleDF.printSchema() peopleDF.createOrReplaceTempView("employees") teenagerNamesDF = spark.sql("SELECT name FROM employees WHERE salary BETWEEN 3500 AND 4500")
teenagerNamesDF.show() #直接字符串
jsonStrings = ['{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}']
otherPeopleRDD = sc.parallelize(jsonStrings)
otherPeople = spark.read.json(otherPeopleRDD)
otherPeople.show() if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("myPeople demo") \
.getOrCreate()
json_dataset_example(spark)
spark.stop()
提交测试脚本

输出


没毛病,收工
spark单机搭建的更多相关文章
- windows7 spark单机环境搭建及pycharm访问spark
windows7 spark单机环境搭建 follow this link how to run apache spark on windows7 pycharm 访问本机 spark 安装py4j ...
- spark单机部署及样例运行
spark单机运行部署 环境预装 需要预先下载jdk和spark.机器使用centos6.6(推荐).然后依次运行 [root@spark-master root]# cd /root #安装必要的软 ...
- 分布式计算框架-Spark(spark环境搭建、生态环境、运行架构)
Spark涉及的几个概念:RDD:Resilient Distributed Dataset(弹性分布数据集).DAG:Direct Acyclic Graph(有向无环图).SparkContext ...
- Hive On Spark环境搭建
Spark源码编译与环境搭建 Note that you must have a version of Spark which does not include the Hive jars; Spar ...
- 单机搭建Android开发环境(二)
前文介绍了如何优化SSD和内存,以发挥开发主机的最佳性能,同时提到在SSD上创建虚拟机.为什么不装双系统呢?双系统性能应该会更好!采用Windows+虚拟机的方式,主要是考虑到安卓开发和日常办公两方面 ...
- 单机搭建Android开发环境(四)
单机搭建安卓开发环境,前三篇主要是磨刀霍霍,这一篇将重点介绍JDK.REPO.GIT及编译工具的安装,下载项目代码并编译.特别说明,以下操作基于64位12.04 Server版Ubuntu.若采用其他 ...
- 单机搭建Android开发环境(三)
单机搭建Android开发环境,第一篇重点介绍了如何优化Windows 7系统,以提高开发主机的性能并延长SSD的使用寿命.第二篇重点介绍了基于VMWare安装64位版的Ubuntu 12.04,并安 ...
- Kafka 概念、单机搭建与使用
目录 Kafka 概念.单机搭建与使用 基本概念介绍 Topic Producer Consumer Kafka单机配置,一个Broker 环境: 配置zookeeper 配置Kafka 使用Kafk ...
- scala+hadoop+spark环境搭建
一.JDK环境构建 在指定用户的根目录下编辑.bashrc文件,添加如下部分: # .bashrc # Source global definitions if [ -f /etc/bashrc ]; ...
随机推荐
- XSS(四)攻击防御
XSS Filter XSS Filter的作用是过滤用户(客户端)提交的有害信息,从而达到防范XSS攻击的效果 XSS Filter作为防御跨站攻击的主要手段之一,已经广泛应用在各类Web系统之中, ...
- 4. Traffic monitoring tools (流量监控工具 10个)
4. Traffic monitoring tools (流量监控工具 10个)EttercapNtop SolarWinds已经创建并销售了针对系统管理员的数十种专用工具. 安全相关工具包括许多网络 ...
- 下载jar包的网站
http://mvnrepository.com/ http://findjar.com http://sourceforge.net/
- Event对象中的target属性和currentTarget属性的区别
先上结论: Event.target:触发事件的元素: Event.currentTarget:事件绑定的元素: 通过下面的例子来理解这两个属性的区别: 使用Event.target属性的例子:(我在 ...
- kotlin 编译 运行 hello world
kotlin 编译器下载地址:https://github.com/JetBrains/kotlin/releases/tag/v1.3.31 解压:kotlin-compiler-1.3.31.zi ...
- python selenium-webdriver 元素操作之键盘操作(五)
上节介绍了模拟鼠标对元素的操作,本节主要介绍键盘对元素的操作,实际过程中鼠标对元素的操作比键盘对元素的操作更经常使用,但是键盘对元素的操作也很重要,本节主要介绍一下键盘对元素的操作. selenium ...
- Oracle中函数/过程返回多个值(结果集)
Oracle中函数/过程返回结果集的几种方式: 以函数return为例,存储过程只需改为out参数即可,在oracle 10g测试通过. (1) 返回游标: return的类型为:SYS_REFCUR ...
- Python3学习的准备工作
简单好用的桌面开发平台:ubuntu 16.x/18.x 或 LinuxMint 18.x 开发工具:新版操作系统都自带有Python3.5及更高版本 其实作为初学者,不要迷信版本,也不必着急升级成最 ...
- java.util.concurrent包下集合类的特点与适用场景
java.util.concurrent包,此包下的集合都不允许添加null元素 序号 接口 类 特性 适用场景 1 Queue.Collection ArrayBlockingQueue 有界.阻塞 ...
- 适用于nodercms的打包构建脚本
背景 最近自己用nodercms搭建了一个简单的博客系统,用户发布一些自己谁便谢谢的文章.感谢nodercms团队,这个cms轻量易用,用于做个人博客太方便了.开发了博客系统,肯定设计到部署到AWS或 ...