Hadoop Java API操作HDFS文件系统(Mac)
2、关联jar包
在eclipse中新建项目中,建lib文件夹,把要用的jar包拷贝进来,jar包在解压好的 hadoop-2.9.1/share/hadoop中
我们这里不拷贝,选择关联你所存放在电脑上的路径
在项目上右键选择 Bulid Path > Add Libraries > User Library > ok > new > 命名 > ok > Add External JARs > 选择jar包
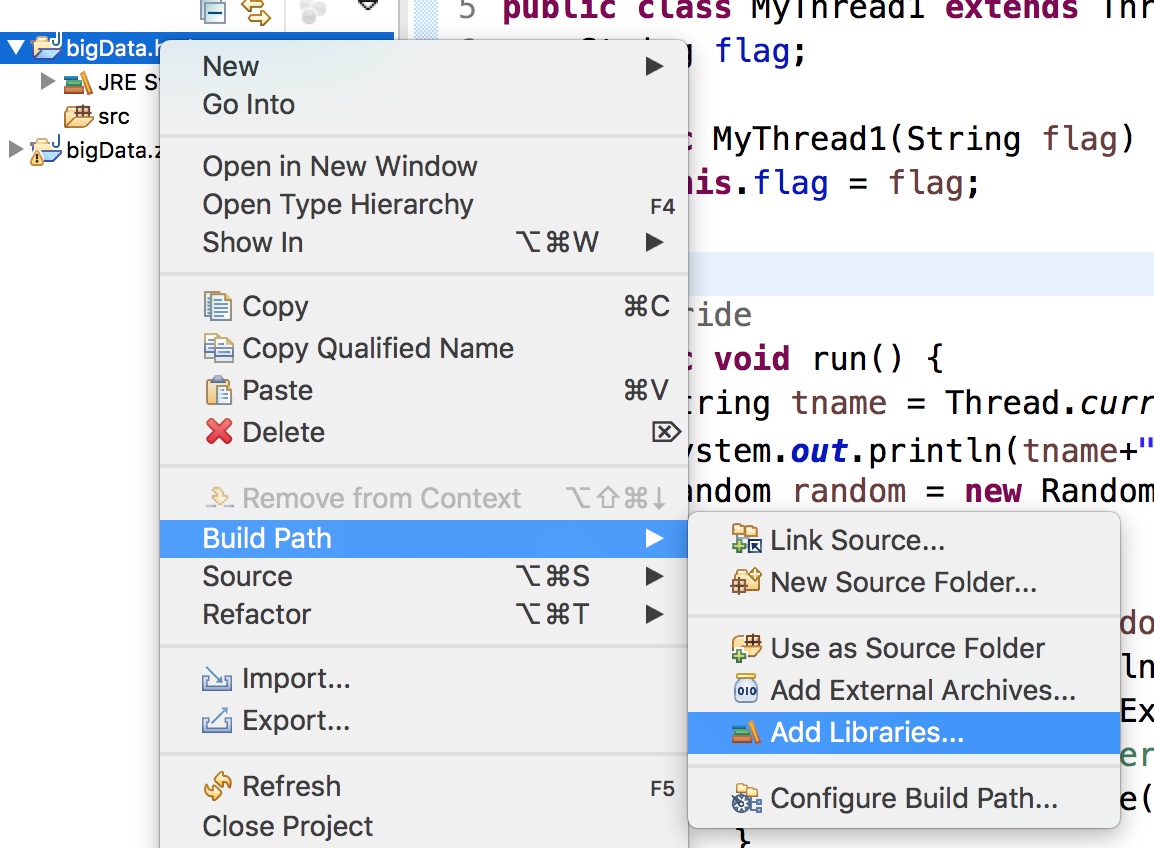

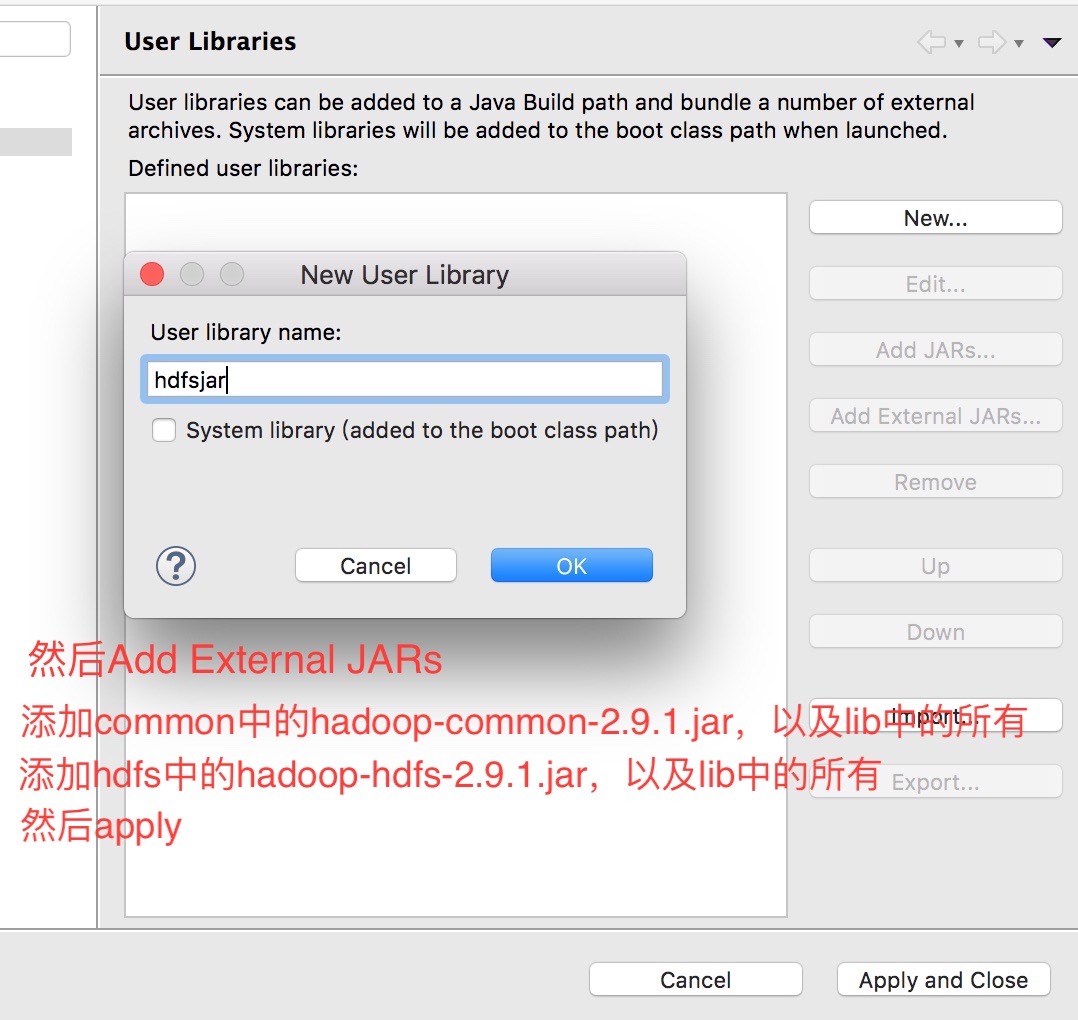
然后会看到项目下多了个包

3、开始写代码
package bigdata.hdfs; import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.net.URI;
import java.util.Iterator;
import java.util.Map.Entry; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test; /* 客户端操作hdfs时,需要一个用户身份,
* 默认情况下,hdfs客户端会从jvm中获取一个参数来作为自己的用户身份:-DHADOOP_USER_NAME=hadoop,
* 解决方法方法有两种:
* 1、设置外部参数;
* 2、在代码中写明,用get方法时,选择三个参数的,将用户名传进去;
*/
public class HdfsClientDemo {
FileSystem fs = null; @Before
public void init() throws Exception {
Configuration conf = new Configuration();
//这里要识别master的话,需要修改本机hosts文件
conf.set("fs.defaultFS", "hdfs://master:9000");
//拿到一个文件操作系统的客户端实例对象
fs = FileSystem.get(new URI("hdfs://master:9000"), conf, "wang");
} // 上传
@Test
public void testUpload() throws Exception {
fs.copyFromLocalFile(new Path("/Users/wang/Desktop/upload.jpg"),new Path("/upload_copy.jpg"));
fs.close();
} //下载
@Test
public void testDownload() throws Exception {
fs.copyToLocalFile(new Path("/upload_copy.jpg"), new Path("/Users/wang/Desktop/download.jpg"));
fs.close();
} @Test
public void testUpload2() throws Exception {
//以流的方式上传
FSDataOutputStream outputStream = fs.create(new Path("/liu.txt"));
FileInputStream inputStream = new FileInputStream("/Users/wang/Desktop/");
org.apache.commons.io.IOUtils.copy(inputStream, outputStream);
} @Test
public void testDownload2() throws Exception {
//以流的方式下载
FSDataInputStream InputStream= fs.open(new Path("/a.txt"));
//指定读取文件的指针的起始位置
InputStream.seek(12);
FileOutputStream OutputStream = new FileOutputStream("/Users/wang/Desktop/a.txt");
org.apache.commons.io.IOUtils.copy(InputStream, OutputStream);
} //打印参数
@Test
public void testConf() {
Configuration conf = new Configuration();
Iterator<Entry<String, String>> it = conf.iterator();
while(it.hasNext()) {
Entry<String, String> en = it.next();
System.out.println(en.getKey()+':'+en.getValue());
}
} @Test
public void testLs() throws Exception{
//递归列出所有文件,返回一个迭代器对象
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("blocksize:"+fileStatus.getBlockSize());
System.out.println("owner:"+fileStatus.getOwner());
System.out.println("Replication:"+fileStatus.getReplication());
System.out.println("Permission:"+fileStatus.getPermission());
System.out.println("Name:"+fileStatus.getPath().getName());
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for(BlockLocation b:blockLocations) {
System.out.println("块起始偏移量"+b.getOffset());
System.out.println("块长度"+b.getLength());
String[] hosts = b.getHosts();
//块所在的datanode节点
for(String host:hosts) {
System.out.println("datanode:"+host);
}
}
System.out.println("--------------------");
}
} @Test
public void testLs2() throws Exception {
//只列出一个层级
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for(FileStatus file:listStatus) {
System.out.print("name:"+file.getPath().getName()+",");
System.out.println((file.isFile()?"file":"directory"));
}
}
}
Hadoop Java API操作HDFS文件系统(Mac)的更多相关文章
- 使用Java API操作HDFS文件系统
使用Junit封装HFDS import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org ...
- 使用Java Api 操作HDFS
如题 我就是一个标题党 就是使用JavaApi操作HDFS,使用的是MAVEN,操作的环境是Linux 首先要配置好Maven环境,我使用的是已经有的仓库,如果你下载的jar包 速度慢,可以改变Ma ...
- hadoop学习笔记(五):java api 操作hdfs
HDFS的Java访问接口 1)org.apache.hadoop.fs.FileSystem 是一个通用的文件系统API,提供了不同文件系统的统一访问方式. 2)org.apache.hadoop. ...
- Hadoop Java API 操作 hdfs--1
Hadoop文件系统是一个抽象的概念,hdfs仅仅是Hadoop文件系统的其中之一. 就hdfs而言,访问该文件系统有两种方式:(1)利用hdfs自带的命令行方式,此方法类似linux下面的shell ...
- 使用java api操作HDFS文件
实现的代码如下: import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; import ...
- Hadoop之HDFS(三)HDFS的JAVA API操作
HDFS的JAVA API操作 HDFS 在生产应用中主要是客户端的开发,其核心步骤是从 HDFS 提供的 api中构造一个 HDFS 的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS ...
- HDFS 05 - HDFS 常用的 Java API 操作
目录 0 - 配置 Hadoop 环境(Windows系统) 1 - 导入 Maven 依赖 2 - 常用类介绍 3 - 常见 API 操作 3.1 获取文件系统(重要) 3.2 创建目录.写入文件 ...
- JAVA API 实现hdfs文件操作
java api 实现hdfs 文件操作会出现错误提示: Permission denied: user=hp, access=WRITE, inode="/":hdfs:supe ...
- 大数据-09-Intellij idea 开发java程序操作HDFS
主要摘自 http://dblab.xmu.edu.cn/blog/290-2/ 简介 本指南介绍Hadoop分布式文件系统HDFS,并详细指引读者对HDFS文件系统的操作实践.Hadoop分布式文件 ...
随机推荐
- Ubuntu16.04 换阿里源
国内阿里源速度比较快,北京联通下载极快.更新也比较稳定 1.备份 cp /etc/apt/source.list /etc/apt/source.list.bak 2.编辑source文件 sudo ...
- 一键部署office的工具——OTool
OTool可用于office的下载.安装和激活,其激活方式是调用kmspico服务器进行的,官方网站是https://otp.landian.vip/zh-cn/,最新版本5.9.3.6在2019/4 ...
- Python(五) —— 内置模块
文档参考:https://docs.python.org/zh-cn/3.7/library/index.html 随机模块——random 这里我们介绍几种常用 random 的操作 名称 功能 ...
- oracle报错 ORA-02290: 违反检查约束条件问题
场景: 使用plsql/developer 将原本要求非空的字段 改为可以为空 然后在插入数据的时候 报错改字段约束条件还起作用 解决方案: 首先查询该表的约束条件 select * from u ...
- python selenium-webdriver 定位frame中的元素 (十三)
定位元素时经常会出现定位不到元素,这时候我们需要观察标签的上下文,一般情况下这些定位不到的元素存放在了frame或者放到窗口了,只要我们切入进去就可以很容易定位到元素. 处理frame时主要使用到sw ...
- 【申嵌视频】5-1 ubuntu下安装VMWare Tools工具
[申嵌视频]5-1 ubuntu下安装VMWare Tools工具 适合搭建mini2440, Tiny6410, smart210,Tiny4412, NanoPC-T2, NanoPC-T3, N ...
- excel表格公式无效、不生效的解决方案及常见问题、常用函数
1.表格公式无效.不生效 使用公式时碰到了一个问题,那就是公式明明已经编辑好了,但是在单元格里不生效,直接把公式显示出来了,网上资料说有4种原因,但是我4种都不是,是第5种原因,如下图: 这种情况是由 ...
- C#-IniFiles文件配置连接数据库
第一步:创建一个INI文件放在程序下的bin下Debug下 第二步:添加一个类在程序中,进行读写操作 public class IniFiles { public string inipath; // ...
- elasticSearch 2.3 delete-by-query plugin
The delete-by-query plugin adds support for deleteing all of the documents which match the specified ...
- node-js:文摘
ES6相关 1.module.exports与exports,export与export default之间的关系和区别 nodejs基础 1.NodeJs安装与全局配置(不建议修改包的全局安装路径, ...