基于图的图像分割(Graph-Based Image Segmentation)
一、介绍
基于图的图像分割(Graph-Based Image Segmentation),论文《Efficient Graph-Based Image Segmentation》,P. Felzenszwalb, D. Huttenlocher,International Journal of Computer Vision, Vol. 59, No. 2, September 2004
论文下载和论文提供的C++代码在这里。
Graph-Based Segmentation是经典的图像分割算法,其作者Felzenszwalb也是提出DPM(Deformable Parts Model)算法的大牛。
Graph-Based Segmentation算法是基于图的贪心聚类算法,实现简单,速度比较快,精度也还行。不过,目前直接用它做分割的应该比较少,很多算法用它作垫脚石,比如Object Propose的开山之作《Segmentation as Selective Search for Object Recognition》就用它来产生过分割(over segmentation)。
二、图的基本概念
因为该算法是将图像用加权图抽象化表示,所以补充图的一些基本概念。
1、图
是由顶点集V(vertices)和边集E(edges)组成,表示为G=(V, E),顶点v∈V,在论文即为单个的像素点,连接一对顶点的边(vi, vj)具有权重w(vi, vj),本文中的意义为顶点之间的不相似度(dissimilarity),所用的是无向图。
2、树
特殊的图,图中任意两个顶点,都有路径相连接,但是没有回路。如下图中加粗的边所连接而成的图。如果看成一团乱连的珠子,只保留树中的珠子和连线,那么随便选个珠子,都能把这棵树中所有的珠子都提起来。
如果顶点i和h这条边也保留下来,那么顶点h,i,c,f,g就构成了一个回路。
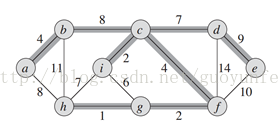
3、最小生成树(minimum spanning tree)
特殊的树,给定需要连接的顶点,选择边权之和最小的树。
论文中,初始化时每一个像素点都是一个顶点,然后逐渐合并得到一个区域,确切地说是连接这个区域中的像素点的一个MST。如下图,棕色圆圈为顶点,线段为边,合并棕色顶点所生成的MST,对应的就是一个分割区域。分割后的结果其实就是森林。
三、相似性
既然是聚类算法,那应该依据何种规则判定何时该合二为一,何时该继续划清界限呢?对于孤立的两个像素点,所不同的是灰度值,自然就用灰度的距离来衡量两点的相似性,本文中是使用RGB的距离,即

当然也可以用perceptually uniform的Luv或者Lab色彩空间,对于灰度图像就只能使用亮度值了,此外,还可以先使用纹理特征滤波,再计算距离,比如先做Census Transform再计算Hamming distance距离。
四、全局阈值 >> 自适应阈值,区域的类内差异、类间差异
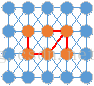
上面提到应该用亮度值之差来衡量两个像素点之间的差异性。对于两个区域(子图)或者一个区域和一个像素点的相似性,最简单的方法即只考虑连接二者的边的不相似度。如下图,已经形成了棕色和绿色两个区域,现在通过紫色边来判断这两个区域是否合并。那么我们就可以设定一个阈值,当两个像素之间的差异(即不相似度)小于该值时,合二为一。迭代合并,最终就会合并成一个个区域,效果类似于区域生长:星星之火,可以燎原。
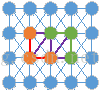
举例说明:

对于上右图,显然应该聚成上左图所示的3类:高频区h,斜坡区s,平坦区p。
如果我们设置一个全局阈值,那么如果h区要合并成一块的话,那么该阈值要选很大,但是那样就会把p和s区域也包含进来,分割结果太粗。如果以p为参考,那么阈值应该选特别小的值,那样的话p区是会合并成一块,但是h区就会合并成特别特别多的小块,如同一面支离破碎的镜子,分割结果太细。显然,全局阈值并不合适,那么自然就得用自适应阈值。对于p区该阈值要特别小,s区稍大,h区巨大。
先来两个定义,原文依据这两个附加信息来得到自适应阈值。
一个区域内的类内差异Int(C):

可以近似理解为一个区域内部最大的亮度差异值,定义是MST中不相似度最大的一条边。
俩个区域的类间差异Diff(C1, C2):

即连接两个区域所有边中,不相似度最小的边的不相似度,也就是两个区域最相似的地方的不相似度。
直观的判断,当:

时,两个区域应当合并!
五、算法步骤
1、计算每一个像素点与其8邻域或4邻域的不相似度。
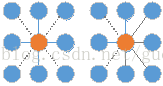
如上图,实线为只计算4领域,加上虚线就是计算8邻域,由于是无向图,按照从左到右,从上到下的顺序计算的话,只需要计算右图中灰色的线即可。
2、将边按照不相似度non-decreasing排列(从小到大)排序得到e1, e2, ..., en。
3、选择ei
4、对当前选择的边ej(vi和vj不属于一个区域)进行合并判断。设其所连接的顶点为(vi, vj),
if 不相似度小于二者内部不相似度:
5、更新阈值以及类标号
else:
6、如果i < n,则按照排好的顺序,选择下一条边转到Step 4,否则结束。
六、论文提供的代码
打开本博文最开始的连接,进入论文网站,下载C++代码。下载后,make编译程序。命令行运行格式:
/******************************************** sigma 对原图像进行高斯滤波去噪 k 控制合并后的区域的数量 min: 后处理参数,分割后会有很多小区域,当区域像素点的个数小于min时,选择与其差异最小的区域合并 input 输入图像(PPM格式) output 输出图像(PPM格式) sigma: Used to smooth the input image before segmenting it. k: Value for the threshold function. min: Minimum component size enforced by post-processing. input: Input image. output:Output image. Typical parameters are sigma = 0.5, k = 500, min = 20. Larger values for k result in larger components in the result. */ ./segment sigma k min input output
七、OpenCV3.3 cv::ximgproc::segmentation::GraphSegmentation类
/opencv_contrib/modules/ximgproc/include/opencv2/ximgproc/segmentation.hpp基于图的图像分割(Graph-Based Image Segmentation)的更多相关文章
- 图像切割—基于图的图像切割(Graph-Based Image Segmentation)
图像切割-基于图的图像切割(Graph-Based Image Segmentation) Reference: Efficient Graph-Based Image Segmentation ...
- 【GCN】图卷积网络初探——基于图(Graph)的傅里叶变换和卷积
[GCN]图卷积网络初探——基于图(Graph)的傅里叶变换和卷积 2018年11月29日 11:50:38 夏至夏至520 阅读数 5980更多 分类专栏: # MachineLearning ...
- Learning Combinatorial Embedding Networks for Deep Graph Matching(基于图嵌入的深度图匹配)
1. 文献信息 题目: Learning Combinatorial Embedding Networks for Deep Graph Matching(基于图嵌入的深度图匹配) 作者:上海交通大学 ...
- 基于图嵌入的高斯混合变分自编码器的深度聚类(Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedding, DGG)
基于图嵌入的高斯混合变分自编码器的深度聚类 Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedd ...
- Graph Based SLAM 基本原理
作者 | Alex 01 引言 SLAM 基本框架大致分为两大类:基于概率的方法如 EKF, UKF, particle filters 和基于图的方法 .基于图的方法本质上是种优化方法,一个以最小化 ...
- Azure ARM (16) 基于角色的访问控制 (Role Based Access Control, RBAC) - 使用默认的Role
<Windows Azure Platform 系列文章目录> 今天上午刚刚和客户沟通过,趁热打铁写一篇Blog. 熟悉Microsoft Azure平台的读者都知道,在老的Classic ...
- 图:无向图(Graph)基本方法及Dijkstra算法的实现 [Python]
一般来讲,实现图的过程中需要有两个自定义的类进行支撑:顶点(Vertex)类,和图(Graph)类.按照这一架构,Vertex类至少需要包含名称(或者某个代号.数据)和邻接顶点两个参数,前者作为顶点的 ...
- 基于聚类的“图像分割”(python)
基于聚类的“图像分割” 参考网站: https://zhuanlan.zhihu.com/p/27365576 昨天萌新使用的是PIL这个库,今天发现机器学习也可以这样玩. 视频地址Python机器学 ...
- 图数据库 Nebula Graph 的数据模型和系统架构设计
Nebula Graph:一个开源的分布式图数据库.作为唯一能够存储万亿个带属性的节点和边的在线图数据库,Nebula Graph 不仅能够在高并发场景下满足毫秒级的低时延查询要求,而且能够提供极高的 ...
随机推荐
- 【BZOJ】1294: [SCOI2009]围豆豆Bean
题解 随机跳题真好玩 这个就是考虑我们怎么判断点在多边形内,就是点做一条射线,穿过了奇数条边 我们只需要记录一个二进制状态表示每个点的射线穿过路径的次数的奇偶性 枚举起点,然后用BFS的方式更新dp状 ...
- 【Ubuntu】Ubuntu设置和查看环境变量
[Ubuntu]Ubuntu设置和查看环境变量 转载 https://blog.csdn.net/White_Idiot/article/details/78253004 1. 查看环境变量 查 ...
- HttpRequest中常见的四种Content-Type(转)
add by zhj: Content-Type用于说明request body的编码格式的,对于没有request body的http method如GET,HEAD没有必要设置这个参数,当然,你设 ...
- Sublime快速入门
在当前的互联网时代,任何程序语言和相关技术都只是实现互联网应用的一种手段,这也就造成了大量的互联网工程师长期与不同的语言.技术.系统环境.IDE等打交道.因此一个相对统一方便的IDE对于程序员来说显得 ...
- html5 利用谷歌地图显示当前位置
目前,google在国内需要FQ才能上,翻不了墙的话,只能获取到经纬度信息. *调用navigator.geolocation对象时,首先要获取用户同意. navigator.geolocation. ...
- Mysql索引整理总结
一.索引概述 1. 简介 索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息. 举例说明索引:如果把数据库中的某一张看成一本书,那么索引就像是书的目录,可以通过 ...
- 循序渐进学.Net Core Web Api开发系列【4】:前端访问WebApi
系列目录 循序渐进学.Net Core Web Api开发系列目录 本系列涉及到的源码下载地址:https://github.com/seabluescn/Blog_WebApi 一.概述 前一篇文章 ...
- PC端meta标签
下面介绍meta标签的几个属性,charset,content,http-equiv,name. 一.charset 此特性声明当前文档所使用的字符编码,但该声明可以被任何一个元素的lang特性的值覆 ...
- 面向对象设计原则 接口分离原则(Interface Segregation Principle)
接口隔离原则 使用多个专门的接口,而不使用单一的总接口,即客户端不应该依赖那些它不需要的接口. 从接口隔离原则的定义可以看出,他似乎跟SRP有许多相似之处. 是的其实ISP和SRP都是强调职责的单一性 ...
- hdu 4460 第37届ACM/ICPC杭州赛区H题 STL+bfs
题意:一些小伙伴之间有朋友关系,比如a和b是朋友,b和c是朋友,a和c不是朋友,则a和c之间存在朋友链,且大小为2,给出一些关系,求出这些关系中最大的链是多少? 求最短路的最大距离 #include& ...