Hadoop详细安装步骤
hadoop安装:(分布式模式)
参考地址:http://dblab.xmu.edu.cn/blog/install-hadoop/
http://dblab.xmu.edu.cn/blog/install-hadoop-cluster/
1、安装包准备, Ubuntu 14.04 64位 作为系统环境;hadoop2版本:hadoop2.6.0
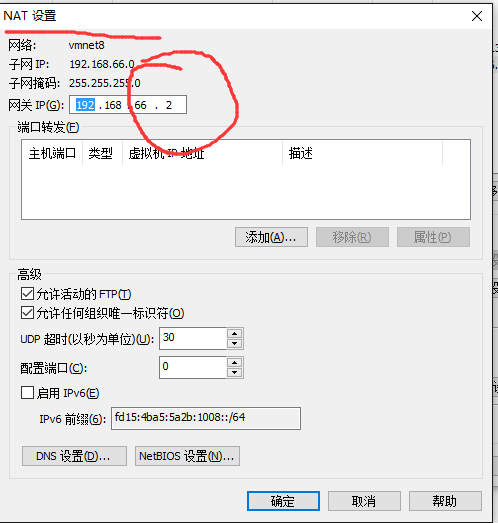
2、虚拟机完毕后,nat模式下设置静态ip
--此时如果你的虚拟机没有网时,注意在虚拟机的虚拟网络编辑器里面,将联网模式改成nat或者桥接模式(速度较快)
先更新ubantu:sudo apt-get update
先安装vim编辑器:sudo apt-get install vim
Ubantu设置ip:
1、sudo vim /etc/NetworkManager/NetworkManager.conf
将false改成true
2、修改配置文件/etc/network/interfaces
sudo vim /etc/network/interfaces
添加以下内容:(具体ip根据nat下面的地址来配喔)
auto eth0 //设置自动启动eth0接口
iface eth0 inet static //配置静态IP
address 192.168.66.106 //IP地址
netmask 255.255.255.128 //子网掩码
gateway 192.168.66.2 //网关和nat配置中要一致,下面的dns也得这样
dns-nameservers 192.168.66.2
3、重启网络,使配置生效:sudo /etc/init.d/networking restart
4、重启机器:sudo shutdown -r now
3、查看有无ssh ①.ssh localhost ②.没有则安装ssh:sudo apt-get install ssh
4、ssh 互信生产密钥:进入.ssh目录下;执行命令: ssh-keygen -t rsa ;cat ./id_rsa.pub >> ./authorized_keys
并将authorized_keys scp给下面的datanode节点的机器
5、安装Java环境
sudo apt-get install openjdk-7-jre openjdk-7-jdk
6、配置环境变量$JAVA_HOME
①、查询java_home目录:
dpkg -L openjdk-7-jdk | grep '/bin/javac' 结果 /bin/javac 之前为JAVA_HOME路径
②、在 ~/.bashrc 中进行设置$JAVA_HOME环境变量:export JAVA_HOME=JDK安装路径
7、创建hadoop用户
sudo useradd -m hadoop -s /bin/bash #创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。
sudo passwd hadoop #设置密码
sudo adduser hadoop sudo #hadoop 用户增加管理员权限
8、安装Hadoop2
①、sudo tar -zxf ~/下载/hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中
②、cd /usr/local/ # 就安装到/usr/local中
③、sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
④、sudo chown -R hadoop ./hadoop # 修改文件权限
9、Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version
10、因为要使用命令更加方便不再使用"./"命令来执行,故配置环境变量 $PATH
①、在 ~/.bashrc 中进行设置$PATH环境变量:export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
注释:/etc/usr/local/hadoop/bin 此目录为hadoop操作命令
/etc/usr/local/hadoop/bin 此目录为hadoop开启关闭命令
11、此时如果运行hadoop时会报错,说$JAVA_HOME未配置
原因在于还需更改配置文件:
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
需要将里面配置的$JAVA_HOME的环境变量改为绝对路径: export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
12、Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version
13、节点机器名称和ip映射关系配置
节点机器名配置:sudo vim /etc/hostname
namenode ----Master
datenode ----Slave1
节点机器映射关系配置:/etc/sysconfig/network
192.168.1.121 Master
192.168.1.122 Slave1
13、分布式模式还需配置:
①、/usr/local/hadoop/etc/hadoop/ 路径下hadoop的配置文件,用于配置namenode,datanode等
一, 文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。
本教程让 Master 节点仅作为 NameNode 使用,因此将文件中原来的 localhost 删除,只添加一行内容:Slave1。
二、文件 core-site.xml 改为下面的配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
三、文件 hdfs-site.xml,dfs.replication 一般设为 3,但我们只有一个 Slave 节点,所以 dfs.replication 的值还是设为 1:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
四、文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
五、文件 yarn-site.xml:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
六、Slave1 datanode节点同样配置如上。
14、配置完后初始化配置:
hdfs namenode -format
15、启动 hadoop 了,启动需要在 Master 节点上进行:
start-all.sh
或
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
16、通过jps命令查看hadoop进程
此时Msater有五个进程,Slave1 有三个进程
另外还需要在 Master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。
例如我这边一共有 1 个 Datanodes: 结果就为1
也可以通过 Web 页面看到查看 DataNode 和 NameNode 的状态:http://master:50070/。
17、首先创建 HDFS 上的用户目录:
hadoop fs -mkdir -p /user/hadoop
将 /usr/local/hadoop/etc/hadoop 中的配置文件作为输入文件复制到分布式文件系统中:
hadoop fs -mkdir input
hadoop fs -put /usr/local/hadoop/etc/hadoop/*.xml input
接着就可以运行 MapReduce 作业了:(在hdfs上的input目录所有文件中,查询dfs开头;执行比较慢,大概6分钟)
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
可以通过 Web 界面查看任务进度 http://master:8088/cluster
SUCCEEDED 表示完成
18、关闭 Hadoop 集群也是在 Master 节点上执行的:
stop-all.sh
或
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver
Hadoop详细安装步骤的更多相关文章
- Linux详细安装步骤
Linux详细安装步骤(CentOS_6.7_64位) 1.先安装好VMware10软件 2.验证VM是否安装成功: (有些机器在安装vmware的时候会出现一个错误:virtual XT,这需要重启 ...
- LAMP----linux+apache+mysql+php详细安装步骤之一APACHE篇(openldap等)
LAMP----linux+apache+mysql+php详细安装步骤之一APACHE篇(openldap等) linux详细版本为RHEL5.3 [root@localhost mail]# un ...
- Windows下Oracle安装图解----oracle-win-64-11g 详细安装步骤
一. Oracle 下载 官方下地址 http://www.oracle.com/technetwork/database/enterprise-edition/downloads/index.htm ...
- SQL Server系列之SQL Server 2016 中文企业版详细安装步骤(超多图)
1. 下载地址 下载地址 :https://www.microsoft.com/en-us/server-cloud/products/sql-server-2016/ 官方技术文档:https:// ...
- Anaconda的详细安装步骤图文并茂
Anaconda(官方网站)就是可以便捷获取包且对包能够进行管理,同时对环境可以统一管理的发行版本.Anaconda包含了conda.Python在内的超过180个科学包及其依赖项. 事实上Anaco ...
- --nodejs详细安装步骤
什么是nodejs? 脚本语言需要一个解析器才能运行,JavaScript是脚本语言,在不同的位置有不一样的解析器,如写入html的js语言,浏览器是它的解析器角色.而对于需要独立运行的JS,node ...
- Oracle(11g)详细安装步骤
最详细的Oracle安装步骤就在这里,话不多说直接给大家上安装Oracle的详细教程 如果没有安装包,可以先点击下载下载地址:http://download.oracle.com/otn/nt/o ...
- 如何搭建SVN服务器,详细安装步骤。
SVN服务器端安装 下载: VisualSVN是一款图形化svn服务器.官网 http://www.visualsvn.com/server/ 下载地址: http://www.visualsvn.c ...
- Hadoop HA(高可用) 详细安装步骤
什么是HA? HA是High Availability的简写,即高可用,指当当前工作中的机器宕机后,会自动处理这个异常,并将工作无缝地转移到其他备用机器上去,以来保证服务的高可用.(简言之,有两台机器 ...
随机推荐
- 8.2.1-优化SELECT语句
8.2.1.优化 SELECT 语句 由SELECT 语句组成的查询,在数据中执行所有的查询.对这类语句的调优排在首位,无论是调优动态web网页的二级响应时间,还是减少生成巨大隔夜报告的时间. 而且, ...
- 如何利用Social Listening从社会化媒体中“提炼”有价值的信息?
本文转自知乎 作者:苏格兰折耳喵 ----------------------------------------------------- 在本文中,笔者将会介绍大数据分析主要的处对象---社会化媒 ...
- elk收集windows日志
参考网站:https://www.secpulse.com/archives/55636.html https://blog.csdn.net/qq_38094271/article/details/ ...
- Archlinux下vmware-workstation中安装rhel5并通过桥接模式(bridge)上网
首先安装vmware-workstation(从aur中) $yaourt vmware-workstation 安装linux-headers $pacman -S linux-headers 然后 ...
- 浏览器和对象的dom属性
1 DOM对象:var obj=document.getElementById('*'); obj.scrollWidth 是对象的实际内容的宽,不包边线宽度,会随对象中内容的多少改变(内容多了可能会 ...
- JS获取QueryString(Jquery)
QueryString = { data: {}, Initial: function() { var aPairs, aTmp; var qu ...
- Windows环境安装Django步骤
前提:已经安装Python 1.先从Django官网下载压缩包:https://www.djangoproject.com/download/ 2.解压Django,如我解压到 D:\Python\D ...
- ssh-keygen生成git ssh密钥
title: ssh-keygen生成git ssh密钥 date: 2018-05-07 08:49:21 tags: [git,ssh-keygen] --- ssh-keygen生成git ss ...
- hadoop-1
结合其他文章 http://weixiaolu.iteye.com/blog/1504898 https://www.cnblogs.com/dycg/p/3934394.html https://b ...
- Eclipse SVN文件冲突及不能直接提交情况
下图为Eclipse SVN使用过程中存在文件冲突的情形. 以下是三种冲突情形及相应解决办法: 1.简单的文件版本冲突 情形:A改变了文件的头部,B改变了文件的尾部,如果两者改动互不影响,SVN可以智 ...