【Java】 大话数据结构(11) 查找算法(2)(二叉排序树/二叉搜索树)
本文根据《大话数据结构》一书,实现了Java版的二叉排序树/二叉搜索树。
二叉排序树介绍
在上篇博客中,顺序表的插入和删除效率还可以,但查找效率很低;而有序线性表中,可以使用折半、插值、斐波那契等查找方法来实现,但因为要保持有序,其插入和删除操作很耗费时间。
二叉排序树(Binary Sort Tree),又称为二叉搜索树,则可以在高效率的查找下,同时保持插入和删除操作也又较高的效率。下图为典型的二叉排序树。
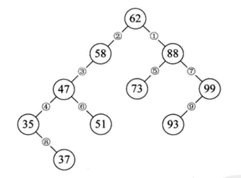
二叉查找树具有以下性质:
(1) 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2) 任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(3) 任意节点的左、右子树也分别为二叉查找树。
查找操作
思路:查找值与结点数据对比,根据大小确定往左子树还是右子树进行下一步比较。
采用递归的查找算法
/*
* 查找
*/
public boolean SearchBST(int key) {
return SearchBST(key, root);
} private boolean SearchBST(int key, Node node) {
if (node == null)
return false;
if (node.data == key) {
return true;
} else if (node.data < key) {
return SearchBST(key, node.rChild);
} else {
return SearchBST(key, node.lChild);
}
}
采用非递归的查找算法
/*
* 查找,非递归
*/
public boolean SearchBST2(int key) {
Node p = root;
while (p != null) {
if (p.data > key) {
p = p.lChild;
} else if (p.data < key) {
p = p.rChild;
} else {
return true;
}
}
return false;
}
插入操作
思路:与查找类似,但需要一个父节点来进行赋值。
采用非递归的插入算法:
/*
* 插入,自己想的,非递归
*/
public boolean InsertBST(int key) {
Node newNode = new Node(key);
if (root == null) {
root = newNode;
return true;
}
Node f = null; // 指向父结点
Node p = root; // 当前结点的指针
while (p != null) {
if (p.data > key) {
f = p;
p = p.lChild;
} else if (p.data < key) {
f = p;
p = p.rChild;
} else {
System.out.println("树中已有相同数据,不再插入!");
return false;
}
}
if (f.data > key) {
f.lChild = newNode;
} else if (f.data < key) {
f.rChild = newNode;
}
return true;
}
采用递归的插入算法:
/*
* 插入,参考别人博客,递归
* 思路:把null情况排除后用递归,否则无法赋值
*/
public boolean InsertBST2(int key) {
if (root == null) {
root = new Node(key);
return true;
}
return InsertBST2(key, root);
} private boolean InsertBST2(int key, Node node) {
if (node.data > key) {
if (node.lChild == null) {
node.lChild = new Node(key);
return true;
} else {
return InsertBST2(key, node.lChild);
}
} else if (node.data < key) {
if (node.rChild == null) {
node.rChild = new Node(key);
return true;
} else {
return InsertBST2(key, node.rChild);
}
} else {
System.out.println("树中已有相同数据,不再插入!");
return false;
}
}
新补充:在写【Java】 大话数据结构(12) 查找算法(3) (平衡二叉树(AVL树))这篇博客时,发现以下的插入方法比较好(如果没有要求返回值必须为boolean格式的话):(推荐使用此类方法)
/*
* 插入操作
*/
public void insert(int key) {
root = insert(root, key);
} private Node insert(Node node, int key) {
if (node == null) {
// System.out.println("插入成功!");
// 也可以定义一个布尔变量来保存插入成功与否
return new Node(key);
}
if (key == node.data) {
System.out.println("数据重复,无法插入!");
} else if (key < node.data) {
node.lChild=insert(node.lChild, key);
} else {
node.rChild=insert(node.rChild, key);
}
return node;
}
删除操作
思路:
(1)删除叶子结点
直接删除;
(2)删除仅有左或右子树的结点
子树移动到删除结点的位置即可;
(3)删除左右子树都有的结点
找到删除结点p的直接前驱(或直接后驱)s,用s来替换结点p,然后删除结点s,如下图所示。
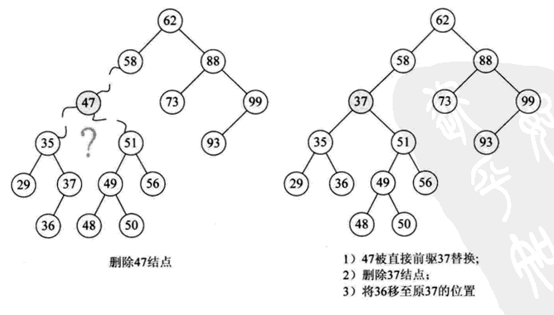
首先找到删除结点位置及其父结点
/*
* 删除操作,先找到删除结点位置及其父结点
* 因为需要有父结点,所以暂时没想到递归的方法(除了令Node对象带个parent属性)
*/
public boolean deleteBST(int key) {
if (root == null) {
System.out.println("空表,删除失败");
return false;
}
Node f = null; // 指向父结点
Node p = root; // 指向当前结点
while (p != null) {
if (p.data > key) {
f = p;
p = p.lChild;
} else if (p.data < key) {
f = p;
p = p.rChild;
} else {
delete(p, f);
return true;
}
}
System.out.println("该数据不存在");
return false;
}
再根据上述思路进行结点p的删除:(需注意删除结点为根节点的情况)
/*
* 删除结点P的操作
* 必须要有父结点,因为Java无法直接取得变量p的地址(无法使用*p=(*p)->lChild)
*/
private void delete(Node p, Node f) {// p为删除结点,f为其父结点
if (p.lChild == null) { // 左子树为空,重接右子树
if (p == root) { // 被删除结点为根结点时,无法利用f,该情况不能忽略
root = root.rChild;
p = null;
} else {
if (f.data > p.data) { // 被删结点为父结点的左结点,下同
f.lChild = p.rChild;
p = null; // 释放结点别忘了
} else {// 被删结点为父结点的右结点,下同
f.rChild = p.rChild;
p = null;
}
}
} else if (p.rChild == null) { // 右子树为空,重接左子树
if (p == root) { // 被删除结点为根结点
root = root.lChild;
p = null;
} else {
if (f.data > p.data) {
f.lChild = p.lChild;
p = null;
} else {
f.rChild = p.lChild;
p = null;
}
}
} else { // 左右子树都不为空,删除位置用前驱结点替代
Node q, s;
q = p;
s = p.lChild;
while (s.rChild != null) { // 找到待删结点的最大前驱s
q = s;
s = s.rChild;
}
p.data = s.data; // 改变p的data就OK
if (q != p) {
q.rChild = s.lChild;
} else {
q.lChild = s.lChild;
}
s = null;
}
}
完整代码(含测试代码)
package BST; /**
* 二叉排序树(二叉查找树)
* 若是泛型,则要求满足T extends Comparable<T> static问题
* @author Yongh
*
*/
class Node {
int data;
Node lChild, rChild; public Node(int data) {
this.data = data;
lChild = null;
rChild = null;
}
} public class BSTree {
private Node root; public BSTree() {
root = null;
} /*
* 查找
*/
public boolean SearchBST(int key) {
return SearchBST(key, root);
} private boolean SearchBST(int key, Node node) {
if (node == null)
return false;
if (node.data == key) {
return true;
} else if (node.data < key) {
return SearchBST(key, node.rChild);
} else {
return SearchBST(key, node.lChild);
}
} /*
* 查找,非递归
*/
public boolean SearchBST2(int key) {
Node p = root;
while (p != null) {
if (p.data > key) {
p = p.lChild;
} else if (p.data < key) {
p = p.rChild;
} else {
return true;
}
}
return false;
} /*
* 插入,自己想的,非递归
*/
public boolean InsertBST(int key) {
Node newNode = new Node(key);
if (root == null) {
root = newNode;
return true;
}
Node f = null; // 指向父结点
Node p = root; // 当前结点的指针
while (p != null) {
if (p.data > key) {
f = p;
p = p.lChild;
} else if (p.data < key) {
f = p;
p = p.rChild;
} else {
System.out.println("数据重复,无法插入!");
return false;
}
}
if (f.data > key) {
f.lChild = newNode;
} else if (f.data < key) {
f.rChild = newNode;
}
return true;
} /*
* 插入,参考别人博客,递归
* 思路:类似查找,
* 但若方法中的node为null的话,将无法插入新数据,需排除null的情况
*/
public boolean InsertBST2(int key) {
if (root == null) {
root = new Node(key);
return true;
}
return InsertBST2(key, root);
} private boolean InsertBST2(int key, Node node) {
if (node.data > key) {
if (node.lChild == null) { // 有null的情况下,才有父结点
node.lChild = new Node(key);
return true;
} else {
return InsertBST2(key, node.lChild);
}
} else if (node.data < key) {
if (node.rChild == null) {
node.rChild = new Node(key);
return true;
} else {
return InsertBST2(key, node.rChild);
}
} else {
System.out.println("数据重复,无法插入!");
return false;
}
} /*
* 这样的插入是错误的(node无法真正被赋值)
*/
/*
private boolean InsertBST2(int key, Node node) {
if(node!=null) {
if (node.data > key)
return InsertBST2(key, node.lChild);
else if (node.data < key)
return InsertBST2(key, node.rChild);
else
return false;//重复
}else {
node=new Node(key);
return true;
}
}
*/ /*
* 删除操作,先找到删除结点位置及其父结点
* 因为需要有父结点,所以暂时没想到递归的方法(除了令Node对象带个parent属性)
*/
public boolean deleteBST(int key) {
if (root == null) {
System.out.println("空表,删除失败");
return false;
}
Node f = null; // 指向父结点
Node p = root; // 指向当前结点
while (p != null) {
if (p.data > key) {
f = p;
p = p.lChild;
} else if (p.data < key) {
f = p;
p = p.rChild;
} else {
delete(p, f);
System.out.println("删除成功!");
return true;
}
}
System.out.println("该数据不存在");
return false;
} /*
* 删除结点P的操作
* 必须要有父结点,因为Java无法直接取得变量p的地址(无法使用*p=(*p)->lChild)
*/
private void delete(Node p, Node f) {// p为删除结点,f为其父结点
if (p.lChild == null) { // 左子树为空,重接右子树
if (p == root) { // 被删除结点为根结点,该情况不能忽略
root = root.rChild;
p = null;
} else {
if (f.data > p.data) { // 被删结点为父结点的左结点,下同
f.lChild = p.rChild;
p = null; // 释放结点别忘了
} else {// 被删结点为父结点的右结点,下同
f.rChild = p.rChild;
p = null;
}
}
} else if (p.rChild == null) { // 右子树为空,重接左子树
if (p == root) { // 被删除结点为根结点
root = root.lChild;
p = null;
} else {
if (f.data > p.data) {
f.lChild = p.lChild;
p = null;
} else {
f.rChild = p.lChild;
p = null;
}
}
} else { // 左右子树都不为空,删除位置用前驱结点替代
Node q, s;
q = p;
s = p.lChild;
while (s.rChild != null) { // 找到待删结点的最大前驱s
q = s;
s = s.rChild;
}
p.data = s.data; // 改变p的data就OK
if (q != p) {
q.rChild = s.lChild;
} else {
q.lChild = s.lChild;
}
s = null;
}
} /*
* 中序遍历
*/
public void inOrder() {
inOrder(root);
System.out.println();
} public void inOrder(Node node) {
if (node == null)
return;
inOrder(node.lChild);
System.out.print(node.data + " ");
inOrder(node.rChild);
} /*
* 测试代码
*/
public static void main(String[] args) {
BSTree aTree = new BSTree();
BSTree bTree = new BSTree();
int[] arr = { 62, 88, 58, 47, 35, 73, 51, 99, 37, 93 };
for (int a : arr) {
aTree.InsertBST(a);
bTree.InsertBST2(a);
}
aTree.inOrder();
bTree.inOrder();
System.out.println(aTree.SearchBST(35));
System.out.println(bTree.SearchBST2(99));
aTree.deleteBST(47);
aTree.inOrder();
}
}
true
true
删除成功!
BSTree
小结(自己编写时的注意点):
查找:操作简单,注意递归的方法没有循环while (p!=null),而是并列的几个判断;
插入:非递归时,要有父结点;递归时,要注意排除null的情况;
删除:记住要分两步,第一步找结点位置时也要把父结点带上;第二步删除结点时,要令p=null,还要注意p==root的情况以及q==p的情况。
【Java】 大话数据结构(11) 查找算法(2)(二叉排序树/二叉搜索树)的更多相关文章
- Java与算法之(13) - 二叉搜索树
查找是指在一批记录中找出满足指定条件的某一记录的过程,例如在数组{ 8, 4, 12, 2, 6, 10, 14, 1, 3, 5, 7, 9, 11, 13, 15 }中查找数字15,实现代码很简单 ...
- 【Java】 大话数据结构(12) 查找算法(3) (平衡二叉树(AVL树))
本文根据<大话数据结构>一书及网络资料,实现了Java版的平衡二叉树(AVL树). 平衡二叉树介绍 在上篇博客中所实现的二叉排序树(二叉搜索树),其查找性能取决于二叉排序树的形状,当二叉排 ...
- 【数据结构05】红-黑树基础----二叉搜索树(Binary Search Tree)
目录 1.二分法引言 2.二叉搜索树定义 3.二叉搜索树的CRUD 4.二叉搜索树的两种极端情况 5.二叉搜索树总结 前言 在[算法04]树与二叉树中,已经介绍过了关于树的一些基本概念以及二叉树的前中 ...
- LeetCode第[98]题(Java):Validate Binary Search Tree(验证二叉搜索树)
题目:验证二叉搜索树 难度:Medium 题目内容: Given a binary tree, determine if it is a valid binary search tree (BST). ...
- 看动画学算法之:平衡二叉搜索树AVL Tree
目录 简介 AVL的特性 AVL的构建 AVL的搜索 AVL的插入 AVL的删除 简介 平衡二叉搜索树是一种特殊的二叉搜索树.为什么会有平衡二叉搜索树呢? 考虑一下二叉搜索树的特殊情况,如果一个二叉搜 ...
- 【Java】 大话数据结构(10) 查找算法(1)(顺序、二分、插值、斐波那契查找)
本文根据<大话数据结构>一书,实现了Java版的顺序查找.折半查找.插值查找.斐波那契查找. 注:为与书一致,记录均从下标为1开始. 顺序表查找 顺序查找 顺序查找(Sequential ...
- 【Java】 大话数据结构(13) 查找算法(4) (散列表(哈希表))
本文根据<大话数据结构>一书,实现了Java版的一个简单的散列表(哈希表). 基本概念 对关键字key,将其值存放在f(key)的存储位置上.由此,在查找时不需比较,只需计算出f(key) ...
- Java实现 LeetCode 108 将有序数组转换为二叉搜索树
108. 将有序数组转换为二叉搜索树 将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树. 本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1. 示例: ...
- [数据结构]——二叉树(Binary Tree)、二叉搜索树(Binary Search Tree)及其衍生算法
二叉树(Binary Tree)是最简单的树形数据结构,然而却十分精妙.其衍生出各种算法,以致于占据了数据结构的半壁江山.STL中大名顶顶的关联容器--集合(set).映射(map)便是使用二叉树实现 ...
随机推荐
- 获取C++类成员虚函数地址
1.GCC平台 GCC平台获取C++成员虚函数地址可使用如下方法[1]: class Base{ int i; public: virtual void f1(){ cout<<" ...
- 敏捷持续集成(Jenkins)
在前面已经完成git和gitlab的相关操作 1.持续集成的概念: 1. 什么是持续集成: 持续集成是一种软件开发实践,即团队开发成员经常集成他们的工作,通过每个成员每天至少集成一次,也就意味着每天可 ...
- 前端学习 -- Css -- 浮动
块元素在文档流中默认垂直排列,所以这个三个div自上至下依次排开,如果希望块元素在页面中水平排列,可以使块元素脱离文档流. 使用float来使元素浮动,从而脱离文档流 可选值: none,默认值,元素 ...
- activiti复盘重推的一种简单实现方式:
activiti复盘重推的一种简单实现方式: 设置流程的每一步让用户选择,比如一共有6步完成,用户选择从第4步开始复盘重推,那么把原来的推演oldId和4传到后台, 首先,后台生成一个新的推演id n ...
- fidder及Charles使用
1. fidder抓https包的基本配置,可参见以下博文 http://blog.csdn.net/idlear/article/details/50999490 2. 遇到问题:抓包看只有Tunn ...
- 包学会之浅入浅出Vue.js:升学篇
包学会之浅入浅出Vue.js:升学篇 蔡述雄,现腾讯用户体验设计部QQ空间高级UI工程师.智图图片优化系统首席工程师,曾参与<众妙之门>书籍的翻译工作.目前专注前端图片优化与新技术的探研. ...
- Python教你找到最心仪的对象
规则 单身妹妹到了适婚年龄,要选对象.候选男子100名,都是单身妹妹没有见过的.百人以随机顺序,从单身妹妹面前逐一经过.每当一位男子在单身妹妹面前经过时,单身妹妹要么选他为配偶,要么不选.如果选他,其 ...
- 常见HTTP状态码(200、301、302、500等)解说
对网站管理工作者来说有个词不陌生,HTTP状态码,它是用以表示网页服务器HTTP响应状态的3位数字代码.状态码的第一个数字代表了响应的五种状态之一. 1XX系列:指定客户端应相应的某些动作,代表请求已 ...
- bzoj千题计划262:bzoj4868: [六省联考2017]期末考试
http://www.lydsy.com/JudgeOnline/problem.php?id=4868 假设 最晚出成绩的是第i天 预处理 cnt[i] 表示 有多少个学生 期望出成绩的那一天 &l ...
- Lua程序设计(一)面向对象概念介绍
完整代码 local mt = {} mt.__add = function(t1,t2) print("两个Table 相加的时候会调用我") end local t1 = {} ...